
호스팅된 컨트롤 플레인
OpenShift Container Platform에서 호스팅된 컨트롤 플레인 사용
초록
1장. 호스팅된 컨트롤 플레인 개요
독립 실행형 또는 호스팅된 컨트롤 플레인 구성의 두 가지 다른 컨트롤 플레인 구성을 사용하여 OpenShift Container Platform 클러스터를 배포할 수 있습니다. 독립 실행형 구성은 전용 가상 머신 또는 물리적 시스템을 사용하여 컨트롤 플레인을 호스팅합니다. OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 각 컨트롤 플레인의 전용 가상 또는 물리적 머신 없이도 호스팅 클러스터에서 컨트롤 플레인을 Pod로 생성합니다.
1.1. 호스트된 컨트롤 플레인 소개
Red Hat OpenShift Container Platform에 호스팅되는 컨트롤 플레인을 사용하여 관리 비용을 줄이고 클러스터 배포 시간을 최적화하며 관리 및 워크로드 문제를 분리하여 애플리케이션에 집중할 수 있습니다.
호스팅되는 컨트롤 플레인은 다음 플랫폼에서 Kubernetes Operator 버전 2.0 이상에 다중 클러스터 엔진 을 사용하여 사용할 수 있습니다.
- 에이전트 공급자를 사용하여 베어 메탈
- OpenShift Virtualization
- AWS(Amazon Web Services) - 기술 프리뷰 기능
- IBM Z, 기술 프리뷰 기능
- IBM Power, 기술 프리뷰 기능
1.1.1. 호스트된 컨트롤 플레인 아키텍처
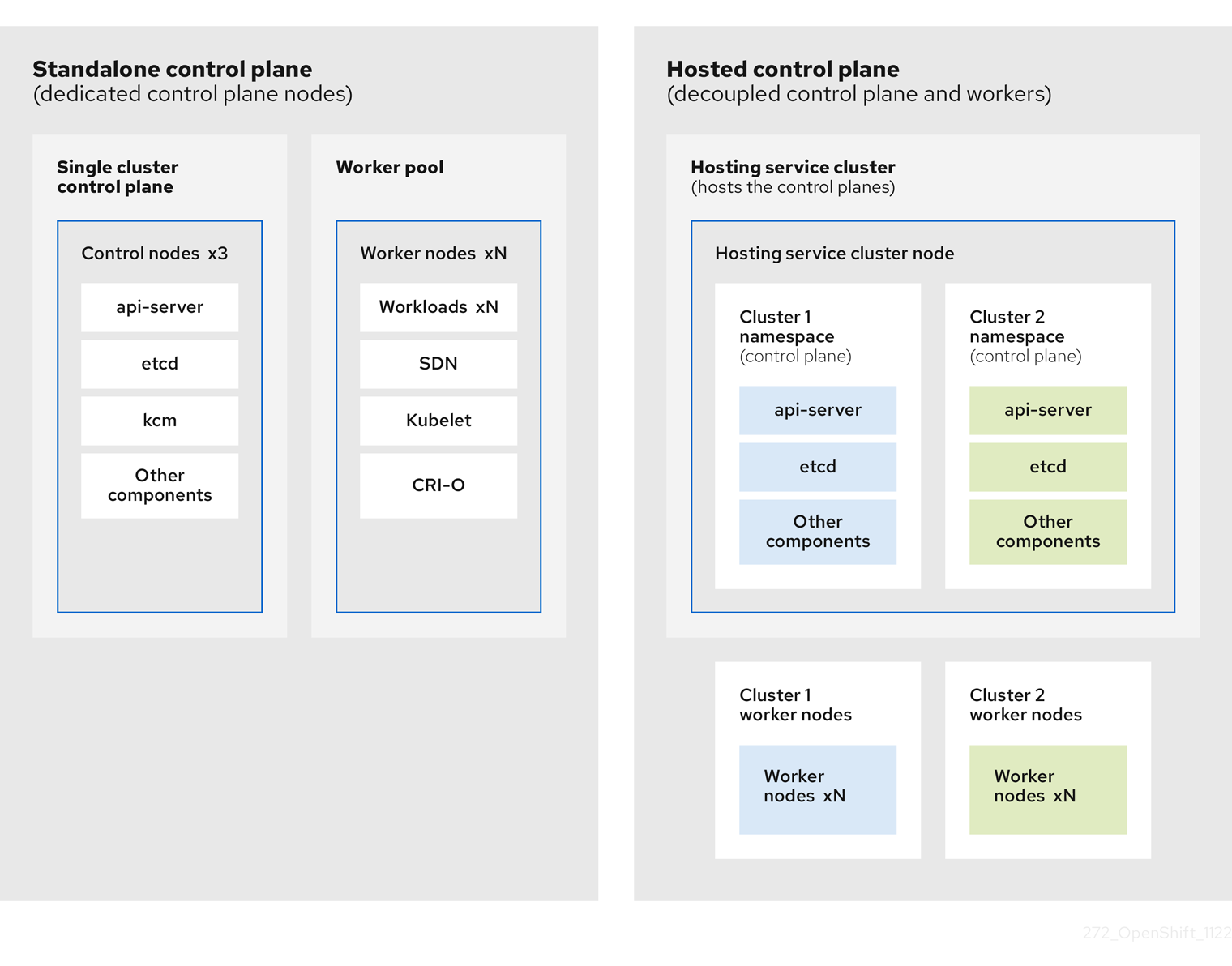
OpenShift Container Platform은 종종 클러스터가 컨트롤 플레인과 데이터 플레인으로 구성된 결합형 또는 독립 실행형 모델로 배포됩니다. 컨트롤 플레인에는 상태를 확인하는 API 끝점, 스토리지 끝점, 워크로드 스케줄러, 작업자가 포함됩니다. 데이터 플레인에는 워크로드 및 애플리케이션이 실행되는 컴퓨팅, 스토리지 및 네트워킹이 포함됩니다.
독립 실행형 컨트롤 플레인은 쿼럼을 보장하기 위해 최소 수를 사용하여 물리적 또는 가상 노드 전용 그룹에 의해 호스팅됩니다. 네트워크 스택이 공유됩니다. 클러스터에 대한 관리자 액세스는 클러스터의 컨트롤 플레인, 머신 관리 API 및 클러스터 상태에 기여하는 기타 구성 요소를 시각화할 수 있습니다.
독립 실행형 모델이 제대로 작동하지만 일부 상황에서는 컨트롤 플레인 및 데이터 플레인이 분리되는 아키텍처가 필요합니다. 이러한 경우 데이터 플레인은 전용 물리적 호스팅 환경을 사용하는 별도의 네트워크 도메인에 있습니다. 컨트롤 플레인은 Kubernetes의 네이티브 배포 및 상태 저장 세트와 같은 고급 프리미티브를 사용하여 호스팅됩니다. 컨트롤 플레인은 다른 워크로드로 처리됩니다.
1.1.2. 호스팅된 컨트롤 플레인의 장점
OpenShift Container Platform의 호스팅된 컨트롤 플레인을 사용하면 진정한 하이브리드 클라우드 접근 방식을 구축하고 다른 여러 가지 이점을 누릴 수 있습니다.
- 컨트롤 플레인이 분리되고 전용 호스팅 서비스 클러스터에서 호스팅되므로 관리와 워크로드 간의 보안 경계가 더욱 강화됩니다. 결과적으로 클러스터의 인증 정보를 다른 사용자에게 유출될 가능성이 줄어듭니다. 인프라 시크릿 계정 관리도 분리되므로 클러스터 인프라 관리자는 실수로 컨트롤 플레인 인프라를 삭제할 수 없습니다.
- 호스팅된 컨트롤 플레인을 사용하면 더 적은 수의 노드에서 많은 컨트롤 플레인을 실행할 수 있습니다. 이로 인해 클러스터 비용이 더 경제적이 됩니다.
- 컨트롤 플레인은 OpenShift Container Platform에서 시작되는 Pod로 구성되므로 컨트롤 플레인이 빠르게 시작됩니다. 모니터링, 로깅, 자동 확장과 같은 컨트롤 플레인 및 워크로드에 동일한 원칙이 적용됩니다.
- 인프라 화면에서 레지스트리, HAProxy, 클러스터 모니터링, 스토리지 노드 및 기타 인프라 구성 요소를 테넌트의 클라우드 공급자 계정으로 푸시하여 테넌트에서 사용을 분리할 수 있습니다.
- 운영 화면에서 다중 클러스터 관리는 더 중앙 집중화되어 클러스터 상태 및 일관성에 영향을 미치는 외부 요인이 줄어듭니다. 사이트 안정성 엔지니어는 문제를 디버그하고 클러스터 데이터 플레인으로 이동하여 문제 해결 시간 (TTR: Time to Resolution)이 단축되고 생산성 향상으로 이어질 수 있습니다.
추가 리소스
1.2. 호스팅된 컨트롤 플레인의 일반 개념 및 가상 사용자집
OpenShift Container Platform에 호스팅되는 컨트롤 플레인을 사용하는 경우 주요 개념과 관련 가상 사용자를 이해하는 것이 중요합니다.
1.2.1. 개념
- 호스트된 클러스터
- 관리 클러스터에서 호스팅되는 컨트롤 플레인 및 API 끝점이 있는 OpenShift Container Platform 클러스터입니다. 호스트된 클러스터에는 컨트롤 플레인과 해당 데이터 플레인이 포함됩니다.
- 호스트된 클러스터 인프라
- 테넌트 또는 최종 사용자 클라우드 계정에 존재하는 네트워크, 컴퓨팅 및 스토리지 리소스입니다.
- 호스트된 컨트롤 플레인
- 호스팅된 클러스터의 API 끝점에 의해 노출되는 관리 클러스터에서 실행되는 OpenShift Container Platform 컨트롤 플레인입니다. 컨트롤 플레인의 구성 요소에는 etcd, Kubernetes API 서버, Kubernetes 컨트롤러 관리자 및 VPN이 포함됩니다.
- 호스트 클러스터
- 관리 클러스터를 참조하십시오.
- 관리형 클러스터
- 허브 클러스터가 관리하는 클러스터입니다. 이 용어는 Kubernetes Operator의 다중 클러스터 엔진에서 Red Hat Advanced Cluster Management에서 관리하는 클러스터 라이프사이클에 따라 다릅니다. 관리형 클러스터는 관리 클러스터와 동일하지 않습니다. 자세한 내용은 관리 클러스터를 참조하십시오.
- 관리 클러스터
- HyperShift Operator가 배포되고 호스팅된 클러스터의 컨트롤 플레인이 호스팅되는 OpenShift Container Platform 클러스터입니다. 관리 클러스터는 호스팅 클러스터와 동일합니다.
- 관리 클러스터 인프라
- 관리 클러스터의 네트워크, 컴퓨팅 및 스토리지 리소스입니다.
1.2.2. 가상 사용자
- 클러스터 인스턴스 관리자
-
이 역할의 사용자는 독립 실행형 OpenShift Container Platform의 관리자와 동일한 것으로 간주됩니다. 이 사용자에게는 프로비저닝된 클러스터에
cluster-admin역할이 있지만 클러스터 업데이트 또는 구성 시 전원이 켜지지 않을 수 있습니다. 이 사용자는 클러스터에 예상된 일부 구성을 확인하기 위해 읽기 전용 액세스 권한이 있을 수 있습니다. - 클러스터 인스턴스 사용자
- 이 역할의 사용자는 독립 실행형 OpenShift Container Platform의 개발자와 동일한 것으로 간주됩니다. 이 사용자에게는 OperatorHub 또는 머신에 대한 보기가 없습니다.
- 클러스터 서비스 소비자
- 이 역할에서 컨트롤 플레인 및 작업자 노드를 요청하거나, 드라이브 업데이트를 요청하거나, 외부화된 구성을 수정할 수 있다고 가정합니다. 일반적으로 이 사용자는 클라우드 인증 정보 또는 인프라 암호화 키를 관리하거나 액세스하지 않습니다. 클러스터 서비스 소비자 가상 사용자는 호스트된 클러스터를 요청하고 노드 풀과 상호 작용할 수 있습니다. 이 역할에는 논리 경계 내에서 호스팅된 클러스터 및 노드 풀을 생성, 읽기, 업데이트 또는 삭제하는 RBAC가 있다고 가정합니다.
- 클러스터 서비스 공급자
이 역할에는 일반적으로 관리 클러스터에 대한
cluster-admin역할이 있고 HyperShift Operator의 가용성을 모니터링하고 소유할 수 있는 RBAC와 테넌트의 호스트 클러스터에 대한 컨트롤 플레인이 있는 사용자입니다. 클러스터 서비스 공급자 개인은 다음 예제를 포함하여 여러 활동을 담당합니다.- 컨트롤 플레인 가용성, 가동 시간 및 안정성에 대한 서비스 수준 오브젝트 보유
- 컨트롤 플레인을 호스팅할 관리 클러스터의 클라우드 계정 구성
- 사용 가능한 컴퓨팅 리소스에 대한 호스트 인식이 포함된 사용자 프로비저닝 인프라 구성
1.3. 호스팅된 컨트롤 플레인 버전 관리
OpenShift Container Platform의 각 메이저, 마이너 또는 패치 버전 릴리스에서 호스팅되는 컨트롤 플레인의 두 가지 구성 요소가 릴리스됩니다.
- The HyperShift Operator
-
hcp명령줄 인터페이스(CLI)
HyperShift Operator는 HostedCluster API 리소스로 표시되는 호스팅 클러스터의 라이프사이클을 관리합니다. HyperShift Operator는 각 OpenShift Container Platform 릴리스와 함께 릴리스됩니다. HyperShift Operator는 hypershift 네임스페이스에 supported-versions 구성 맵을 생성합니다. 구성 맵에는 지원되는 호스팅 클러스터 버전이 포함되어 있습니다.
동일한 관리 클러스터에서 다른 버전의 컨트롤 플레인을 호스팅할 수 있습니다.
supported-versions 구성 맵 오브젝트의 예
apiVersion: v1
data:
supported-versions: '{"versions":["4.15"]}'
kind: ConfigMap
metadata:
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift
hcp CLI를 사용하여 호스트된 클러스터를 생성할 수 있습니다.
HostedCluster 및 NodePool 과 같은 hypershift.openshift.io API 리소스를 사용하여 대규모로 OpenShift Container Platform 클러스터를 생성하고 관리할 수 있습니다. HostedCluster 리소스에는 컨트롤 플레인 및 일반 데이터 플레인 구성이 포함되어 있습니다. HostedCluster 리소스를 생성할 때 연결된 노드가 없는 완전히 작동하는 컨트롤 플레인이 있습니다. NodePool 리소스는 HostedCluster 리소스에 연결된 확장 가능한 작업자 노드 집합입니다.
API 버전 정책은 일반적으로 Kubernetes API 버전 관리 정책과 일치합니다.
1.4. 호스팅된 컨트롤 플레인의 시나리오 업그레이드
업그레이드하기 전에 다음 정보를 고려하십시오.
- 베어 메탈을 관리 클러스터 플랫폼으로 사용합니다.
- Agent 또는 KubeVirt를 호스팅된 클러스터 플랫폼으로 사용합니다.
관리 클러스터는 설치 관리자 프로비저닝 인프라(IPI)를 기반으로 합니다.
다음 시나리오를 검토합니다.
- OpenShift Container Platform 4.14에서 관리 클러스터를 실행하는 동안 다중 클러스터 엔진 (MCE) 버전을 2.4에서 2.5로 업그레이드할 수 있습니다. 그런 다음 호스팅된 클러스터 및 노드 풀을 OpenShift Container Platform 4.14에서 OpenShift Container Platform 4.15로 업그레이드할 수 있습니다.
관리 클러스터, MCE, 호스팅 클러스터 및 노드 풀을 최신 버전으로 업그레이드하려면 다음을 수행합니다.
- OpenShift Container Platform 4.14에서 OpenShift Container Platform 4.15로 관리 클러스터를 업그레이드
- MCE 버전을 2.4에서 2.5로 업그레이드
- 호스팅된 클러스터 및 노드 풀을 OpenShift Container Platform 4.14에서 OpenShift Container Platform 4.15로 업그레이드
2장. 호스트된 컨트롤 플레인 시작하기
OpenShift Container Platform의 호스팅된 컨트롤 플레인을 시작하려면 먼저 사용하려는 공급자에서 호스팅된 클러스터를 구성합니다. 그런 다음 몇 가지 관리 작업을 완료합니다.
다음 공급자 중 하나에서 선택하여 절차를 볼 수 있습니다.
2.1. 베어 메탈
- 호스팅된 컨트롤 플레인 크기 조정 지침
- 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
- 호스트된 클러스터 워크로드 배포
- 베어 메탈 방화벽 및 포트 요구 사항
- 베어 메탈 인프라 요구 사항: 베어 메탈에서 호스팅된 클러스터를 생성하기 위해 인프라 요구 사항을 검토합니다.
- DNS 구성
- 호스트된 클러스터 생성 및 클러스터 생성 확인
-
호스트 클러스터의
NodePool오브젝트를 스케일링 - 호스트 클러스터의 수신 트래픽 처리
- 호스트 클러스터의 노드 자동 확장 활성화
- 연결이 끊긴 환경에서 호스트된 컨트롤 플레인 구성
- 베어 메탈에서 호스트된 클러스터를 삭제하려면 베어 메탈의 호스트 클러스터 삭제 의 지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
2.2. OpenShift Virtualization
- 호스팅된 컨트롤 플레인 크기 조정 지침
- 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
- 호스트된 클러스터 워크로드 배포
- OpenShift Virtualization에서 호스트된 컨트롤 플레인 클러스터 관리: KubeVirt 가상 머신에서 호스팅하는 작업자 노드로 OpenShift Container Platform 클러스터를 생성합니다.
- 연결이 끊긴 환경에서 호스트된 컨트롤 플레인 구성
- 호스트 클러스터를 삭제하려면 OpenShift Virtualization에서 호스트된 클러스터 삭제 의 지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
2.3. AWS(Amazon Web Services)
AWS 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
- AWS 인프라 요구 사항: AWS에서 호스팅 클러스터를 생성하기 위해 인프라 요구 사항을 검토합니다.
- AWS에서 호스팅된 컨트롤 플레인 클러스터 구성(기술 프리뷰): AWS S3 OIDC 시크릿 생성, 라우팅 가능한 퍼블릭 영역 생성, 외부 DNS 활성화, AWS PrivateLink 활성화 및 호스트 클러스터 배포가 포함됩니다.
- 호스팅 된 컨트롤 플레인을 위해 SR-IOV Operator 배포: 호스팅 서비스 클러스터를 구성하고 배포한 후 호스팅된 클러스터에서 SR-IOV(Single Root I/O Virtualization) Operator에 대한 서브스크립션을 생성할 수 있습니다. SR-IOV Pod는 컨트롤 플레인이 아닌 작업자 머신에서 실행됩니다.
- AWS에서 호스트된 클러스터를 삭제하려면 AWS의 호스트 클러스터 삭제 의 지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
2.4. IBM Z
IBM Z 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
2.5. IBM Power
IBM Power 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
2.6. 베어 메탈 에이전트 머신
베어 메탈이 아닌 에이전트 시스템을 사용하는 호스팅된 컨트롤 플레인 클러스터는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
- 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치
- 베어 메탈이 아닌 에이전트를 사용하여 호스팅되는 컨트롤 플레인 클러스터 구성 (기술 프리뷰)
- 베어 메탈이 아닌 에이전트 머신에서 호스팅된 클러스터를 제거하려면 베어 메탈이 아닌 에이전트 머신의 호스트 클러스터 삭제지침을 따르십시오.
- 호스팅된 컨트롤 플레인 기능을 비활성화하려면 호스팅된 컨트롤 플레인 기능 비활성화를 참조하십시오.
3장. 호스팅된 컨트롤 플레인에 대한 인증 및 권한 부여
OpenShift Container Platform 컨트롤 플레인에는 내장 OAuth 서버가 포함되어 있습니다. OpenShift Container Platform API에 인증하기 위해 OAuth 액세스 토큰을 가져올 수 있습니다. 호스팅 클러스터를 생성한 후 ID 공급자를 지정하여 OAuth를 구성할 수 있습니다.
3.1. CLI를 사용하여 호스팅된 클러스터에 대한 OAuth 서버 구성
OpenID Connect ID 공급자(oidc)를 사용하여 호스팅된 클러스터에 대한 내부 OAuth 서버를 구성할 수 있습니다.
지원되는 ID 공급자에 대해 OAuth를 구성할 수 있습니다.
-
OIDC -
htpasswd -
Keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
Google
OAuth 구성에서 ID 공급자를 추가하면 기본 kubeadmin 사용자 공급자가 제거됩니다.
사전 요구 사항
- 호스팅된 클러스터를 생성하셨습니다.
절차
다음 명령을 실행하여 호스팅 클러스터에서
HostedClusterCR(사용자 정의 리소스)을 편집합니다.$ oc edit <hosted_cluster_name> -n <hosted_cluster_namespace>
다음 예제를 사용하여
HostedClusterCR에 OAuth 구성을 추가합니다.apiVersion: hypershift.openshift.io/v1alpha1 kind: HostedCluster metadata: name: <hosted_cluster_name> 1 namespace: <hosted_cluster_namespace> 2 spec: configuration: oauth: identityProviders: - openID: 3 claims: email: 4 - <email_address> name: 5 - <display_name> preferredUsername: 6 - <preferred_username> clientID: <client_id> 7 clientSecret: name: <client_id_secret_name> 8 issuer: https://example.com/identity 9 mappingMethod: lookup 10 name: IAM type: OpenID
- 1
- 호스팅된 클러스터 이름을 지정합니다.
- 2
- 호스팅된 클러스터 네임스페이스를 지정합니다.
- 3
- 이 공급자 이름은 ID 클레임 값 앞에 접두어로 지정되어 ID 이름을 형성합니다. 공급자 이름은 리디렉션 URL을 빌드하는 데도 사용됩니다.
- 4
- 이메일 주소로 사용할 속성 목록을 정의합니다.
- 5
- 표시 이름으로 사용할 속성 목록을 정의합니다.
- 6
- 기본 사용자 이름으로 사용할 속성 목록을 정의합니다.
- 7
- OpenID 공급자에 등록된 클라이언트의 ID를 정의합니다. 클라이언트가
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name> URL로 리디렉션되도록 허용해야 합니다. - 8
- OpenID 공급자에 등록된 클라이언트의 시크릿을 정의합니다.
- 9
- OpenID 사양에 설명된 Issuer Identifier 입니다. 쿼리 또는 조각 구성 요소 없이
https를 사용해야 합니다. - 10
- 이 공급자와
User오브젝트의 ID 간에 매핑이 설정되는 방법을 제어하는 매핑 방법을 정의합니다.
- 파일을 저장하여 변경 사항을 적용합니다.
3.2. 웹 콘솔을 사용하여 호스트 클러스터의 OAuth 서버 구성
OpenShift Container Platform 웹 콘솔을 사용하여 호스팅된 클러스터에 대한 내부 OAuth 서버를 구성할 수 있습니다.
지원되는 ID 공급자에 대해 OAuth를 구성할 수 있습니다.
-
OIDC -
htpasswd -
Keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
Google
OAuth 구성에서 ID 공급자를 추가하면 기본 kubeadmin 사용자 공급자가 제거됩니다.
사전 요구 사항
-
cluster-admin권한이 있는 사용자로 로그인했습니다. - 호스팅된 클러스터를 생성하셨습니다.
절차
- 홈 → API Explorer 로 이동합니다.
-
Filter by kind 상자를 사용하여
HostedCluster리소스를 검색합니다. -
편집하려는
HostedCluster리소스를 클릭합니다. - Instances 탭을 클릭합니다.
-
호스팅된 클러스터 이름 항목 옆에 있는 옵션 메뉴
 를 클릭하고 호스트 클러스터 편집을 클릭합니다.
를 클릭하고 호스트 클러스터 편집을 클릭합니다.
YAML 파일에 OAuth 구성을 추가합니다.
spec: configuration: oauth: identityProviders: - openID: 1 claims: email: 2 - <email_address> name: 3 - <display_name> preferredUsername: 4 - <preferred_username> clientID: <client_id> 5 clientSecret: name: <client_id_secret_name> 6 issuer: https://example.com/identity 7 mappingMethod: lookup 8 name: IAM type: OpenID- 1
- 이 공급자 이름은 ID 클레임 값 앞에 접두어로 지정되어 ID 이름을 형성합니다. 공급자 이름은 리디렉션 URL을 빌드하는 데도 사용됩니다.
- 2
- 이메일 주소로 사용할 속성 목록을 정의합니다.
- 3
- 표시 이름으로 사용할 속성 목록을 정의합니다.
- 4
- 기본 사용자 이름으로 사용할 속성 목록을 정의합니다.
- 5
- OpenID 공급자에 등록된 클라이언트의 ID를 정의합니다. 클라이언트가
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name> URL로 리디렉션되도록 허용해야 합니다. - 6
- OpenID 공급자에 등록된 클라이언트의 시크릿을 정의합니다.
- 7
- OpenID 사양에 설명된 Issuer Identifier 입니다. 쿼리 또는 조각 구성 요소 없이
https를 사용해야 합니다. - 8
- 이 공급자와
User오브젝트의 ID 간에 매핑이 설정되는 방법을 제어하는 매핑 방법을 정의합니다.
- 저장을 클릭합니다.
추가 리소스
- 지원되는 ID 공급자에 대한 자세한 내용은 인증 및 권한 부여 의 "ID 공급자 구성 이해" 를 참조하십시오.
4장. 호스트 클러스터에서 기능 게이트 사용
호스트 클러스터에서 기능 게이트를 사용하여 기본 기능 세트의 일부가 아닌 기능을 활성화할 수 있습니다. 호스팅된 클러스터에서 기능 게이트를 사용하여 TechPreviewNoUpgrade 기능을 활성화할 수 있습니다.
4.1. 기능 게이트를 사용하여 기능 세트 활성화
OpenShift CLI로 HostedCluster CR(사용자 정의 리소스)을 편집하여 호스트 클러스터에서 TechPreviewNoUpgrade 기능을 활성화할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다.
프로세스
다음 명령을 실행하여 호스팅 클러스터에서 편집할
HostedClusterCR을 엽니다.$ oc edit <hosted_cluster_name> -n <hosted_cluster_namespace>
featureSet필드에 값을 입력하여 기능 세트를 정의합니다. 예를 들면 다음과 같습니다.apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name> 1 namespace: <hosted_cluster_namespace> 2 spec: configuration: featureGate: featureSet: TechPreviewNoUpgrade 3
주의클러스터에서
TechPreviewNoUpgrade기능 세트를 활성화하면 취소할 수 없으며 마이너 버전 업데이트를 방지할 수 없습니다. 이 기능 세트를 사용하면 테스트 클러스터에서 이러한 기술 프리뷰 기능을 완전히 테스트할 수 있습니다. 프로덕션 클러스터에서 이 기능 세트를 활성화하지 마십시오.- 파일을 저장하여 변경 사항을 적용합니다.
검증
다음 명령을 실행하여 호스트 클러스터에서
TechPreviewNoUpgrade기능 게이트가 활성화되어 있는지 확인합니다.$ oc get featuregate cluster -o yaml
5장. 호스트된 컨트롤 플레인 업데이트
호스팅된 컨트롤 플레인을 업데이트하려면 호스팅된 클러스터 및 노드 풀을 업데이트해야 합니다. 업데이트 프로세스 중에 클러스터가 완전히 작동하려면 컨트롤 플레인 및 노드 업데이트를 완료하는 동안 Kubernetes 버전 스큐 정책의 요구 사항을 충족해야 합니다.
5.1. 호스팅된 클러스터 업데이트
spec.release 값은 컨트롤 플레인의 버전을 나타냅니다. HostedCluster 오브젝트는 의도한 spec.release 값을 HostedControlPlane.spec.release 값으로 전송하고 적절한 Control Plane Operator 버전을 실행합니다.
호스팅된 컨트롤 플레인은 새로운 버전의 CVO(Cluster Version Operator)를 통해 OpenShift Container Platform 구성 요소와 함께 새 버전의 컨트롤 플레인 구성 요소의 롤아웃을 관리합니다.
5.2. 노드 풀 업데이트
노드 풀을 사용하면 spec.release 및 spec.config 값을 노출하여 노드에서 실행 중인 소프트웨어를 구성할 수 있습니다. 다음과 같은 방법으로 롤링 노드 풀 업데이트를 시작할 수 있습니다.
-
spec.release또는spec.config값을 변경합니다. - AWS 인스턴스 유형과 같은 플랫폼별 필드를 변경합니다. 결과는 새 유형의 새 인스턴스 집합입니다.
- 클러스터 구성을 변경하면 변경 사항이 노드로 전파됩니다.
노드 풀은 업데이트 및 인플레이스 업데이트를 교체할 수 있습니다. nodepool.spec.release 값은 특정 노드 풀의 버전을 지정합니다. NodePool 오브젝트는 .spec.management.upgradeType 값에 따라 교체 또는 인플레이스 롤링 업데이트를 완료합니다.
노드 풀을 생성한 후에는 업데이트 유형을 변경할 수 없습니다. 업데이트 유형을 변경하려면 노드 풀을 생성하고 다른 노드를 삭제해야 합니다.
5.2.1. 노드 풀 교체 업데이트
교체 업데이트는 이전 버전에서 이전 인스턴스를 제거하는 동안 새 버전에 인스턴스를 생성합니다. 이 업데이트 유형은 이러한 수준의 불변성을 비용 효율적으로 사용하는 클라우드 환경에서 효과가 있습니다.
교체 업데이트에서는 노드가 완전히 다시 프로비저닝되므로수동 변경 사항이 유지되지 않습니다.
5.2.2. 노드 풀의 인플레이스 업데이트
인플레이스 업데이트는 인스턴스의 운영 체제를 직접 업데이트합니다. 이 유형은 베어 메탈과 같이 인프라 제약 조건이 높은 환경에 적합합니다.
인플레이스 업데이트는 수동 변경 사항을 유지할 수 있지만 kubelet 인증서와 같이 클러스터가 직접 관리하는 파일 시스템 또는 운영 체제 구성을 수동으로 변경하면 오류를 보고합니다.
5.3. 호스팅된 컨트롤 플레인의 노드 풀 업데이트
호스팅된 컨트롤 플레인에서 노드 풀을 업데이트하여 OpenShift Container Platform 버전을 업데이트합니다. 노드 풀 버전은 호스팅된 컨트롤 플레인 버전을 초과해서는 안 됩니다.
프로세스
OpenShift Container Platform의 새 버전으로 업데이트하는 프로세스를 시작하려면 다음 명령을 입력하여 노드 풀의
spec.release.image값을 변경합니다.$ oc -n <hosted_cluster_namespace> patch hostedcluster <hosted_cluster_name> --patch '{"spec":{"release":{"image": "<image_name>"}}}' --type=merge
검증
새 버전이 롤아웃되었는지 확인하려면 다음 명령을 실행하여
HostedClusterCR(사용자 정의 리소스)에서.status.version및.status.conditions값을 확인합니다.$ oc get hostedcluster <hosted_cluster_name> -o yaml
6장. 호스트된 컨트롤 플레인 Observability
메트릭 세트를 구성하여 호스팅되는 컨트롤 플레인의 메트릭을 수집할 수 있습니다. HyperShift Operator는 관리하는 각 호스팅 클러스터의 관리 클러스터에서 모니터링 대시보드를 생성하거나 삭제할 수 있습니다.
6.1. 호스팅된 컨트롤 플레인에 대한 메트릭 세트 구성
Red Hat OpenShift Container Platform의 호스트된 컨트롤 플레인은 각 컨트롤 플레인 네임스페이스에서 ServiceMonitor 리소스를 생성하여 Prometheus 스택이 컨트롤 플레인에서 지표를 수집할 수 있습니다. ServiceMonitor 리소스는 메트릭 재레이블을 사용하여 etcd 또는 Kubernetes API 서버와 같은 특정 구성 요소에서 포함되거나 제외되는 메트릭을 정의합니다. 컨트롤 플레인에서 생성하는 메트릭 수는 이를 수집하는 모니터링 스택의 리소스 요구 사항에 직접적인 영향을 미칩니다.
모든 상황에 적용되는 고정된 수의 메트릭을 생성하는 대신 각 컨트롤 플레인에 생성할 메트릭 세트를 식별하는 메트릭 세트를 구성할 수 있습니다. 다음 메트릭 세트가 지원됩니다.
-
Telemetry: 이러한 메트릭은 Telemetry에 필요합니다. 이 세트는 기본 세트이며 가장 작은 메트릭 세트입니다. -
SRE:이 세트에는 경고를 생성하고 컨트롤 플레인 구성 요소의 문제 해결을 허용하는 데 필요한 메트릭이 포함되어 있습니다. -
All: 이 세트에는 독립 실행형 OpenShift Container Platform 컨트롤 플레인 구성 요소에서 생성하는 모든 메트릭이 포함됩니다.
메트릭 세트를 구성하려면 다음 명령을 입력하여 HyperShift Operator 배포에서 METRICS_SET 환경 변수를 설정합니다.
$ oc set env -n hypershift deployment/operator METRICS_SET=All
6.1.1. SRE 메트릭 세트 구성
SRE 메트릭 세트를 지정하면 HyperShift Operator는 단일 key: config 를 사용하여 sre-metric-set 이라는 구성 맵을 찾습니다. config 키 값에는 컨트롤 플레인 구성 요소로 구성된 RelabelConfigs 세트가 포함되어야 합니다.
다음 구성 요소를 지정할 수 있습니다.
-
etcd -
kubeAPIServer -
kubeControllerManager -
openshiftAPIServer -
openshiftControllerManager -
openshiftRouteControllerManager -
cvo -
olm -
catalogOperator -
registryOperator -
nodeTuningOperator -
controlPlaneOperator -
hostedClusterConfigOperator
다음 예에는 SRE 메트릭 세트 구성이 설명되어 있습니다.
kubeAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "transformation_(transformation_latencies_microseconds|failures_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "network_plugin_operations_latency_microseconds|sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
kubeControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "rest_client_request_latency_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "root_ca_cert_publisher_sync_duration_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
openshiftAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
openshiftControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
openshiftRouteControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
olm:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
catalogOperator:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
cvo:
- action: drop
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]6.2. 호스트 클러스터에서 모니터링 대시보드 활성화
호스트 클러스터에서 모니터링 대시보드를 활성화하려면 다음 단계를 완료합니다.
프로세스
local-cluster네임스페이스에hypershift-operator-install-flags구성 맵을 생성하여data.installFlagsToAdd섹션에--monitoring-dashboards플래그를 지정해야 합니다. 예를 들면 다음과 같습니다.kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "--monitoring-dashboards" installFlagsToRemove: ""
다음 환경 변수를 포함하도록
hypershift네임스페이스에서 HyperShift Operator 배포를 업데이트할 때까지 몇 분 정도 기다립니다.- name: MONITORING_DASHBOARDS value: "1"모니터링 대시보드가 활성화된 경우 HyperShift Operator가 관리하는 각 호스팅 클러스터에 대해 Operator는
openshift-config-managed네임스페이스에cp-<hosted_cluster_namespace>-<hosted_cluster_name>이라는 구성 맵을 생성합니다. 여기서 <hosted_cluster_namespace>는 호스팅된 클러스터의 네임스페이스이고 <hosted_cluster_name>은 호스트된 클러스터의 이름입니다. 결과적으로 관리 클러스터의 관리 콘솔에 새 대시보드가 추가됩니다.- 대시보드를 보려면 관리 클러스터 콘솔에 로그인하고 모니터링 → 대시보드를 클릭하여 호스트 클러스터의 대시보드로 이동합니다.
-
선택 사항: 호스팅 클러스터에서 모니터링 대시보드를 비활성화하려면
hypershift-operator-install-flags구성 맵에서--monitoring-dashboards플래그를 제거합니다. 호스트 클러스터를 삭제하면 해당 대시보드도 삭제됩니다.
6.2.1. 대시보드 사용자 정의
HyperShift Operator는 호스트된 각 클러스터에 대한 대시보드를 생성하기 위해 Operator 네임스페이스(hypershift)의 monitoring-dashboard-template 구성 맵에 저장된 템플릿을 사용합니다. 이 템플릿에는 대시보드에 대한 메트릭이 포함된 Grafana 패널 세트가 포함되어 있습니다. 구성 맵의 콘텐츠를 편집하여 대시보드를 사용자 지정할 수 있습니다.
대시보드가 생성되면 다음 문자열이 특정 호스팅 클러스터에 해당하는 값으로 교체됩니다.
| 이름 | 설명 |
|
| 호스트된 클러스터의 이름 |
|
| 호스팅된 클러스터의 네임스페이스 |
|
| 호스팅된 클러스터의 컨트롤 플레인 Pod가 배치되는 네임스페이스 |
|
|
호스팅된 클러스터 메트릭의 |
7장. 호스팅된 컨트롤 플레인의 백업, 복원 및 재해 복구
호스팅된 클러스터에서 etcd를 백업 및 복원하거나 호스트된 클러스터에 재해 복구를 제공해야 하는 경우 다음 절차를 참조하십시오.
7.1. 호스트된 클러스터의 etcd Pod 복구
호스팅된 클러스터에서 etcd pod는 상태 저장 세트의 일부로 실행됩니다. 상태 저장 세트는 각 멤버의 etcd 데이터를 저장하기 위해 영구 스토리지에 의존합니다. 고가용성 컨트롤 플레인에서 상태 저장 세트의 크기는 3개의 Pod이며 각 멤버에는 자체 영구 볼륨 클레임이 있습니다.
7.1.1. 호스트 클러스터의 상태 확인
호스트 클러스터의 상태를 확인하려면 다음 단계를 완료합니다.
프로세스
다음 명령을 입력하여 확인할 etcd pod를 입력합니다.
$ oc rsh -n <control_plane_namespace> -c etcd <etcd_pod_name>
다음 명령을 입력하여 etcdctl 환경을 설정합니다.
sh-4.4$ export ETCDCTL_API=3
sh-4.4$ export ETCDCTL_CACERT=/etc/etcd/tls/etcd-ca/ca.crt
sh-4.4$ export ETCDCTL_CERT=/etc/etcd/tls/client/etcd-client.crt
sh-4.4$ export ETCDCTL_KEY=/etc/etcd/tls/client/etcd-client.key
sh-4.4$ export ETCDCTL_ENDPOINTS=https://etcd-client:2379
다음 명령을 입력하여 각 클러스터 구성원의 끝점 상태를 출력합니다.
sh-4.4$ etcdctl endpoint health --cluster -w table
7.1.2. 호스트 클러스터의 etcd 멤버 복구
데이터가 손상되거나 누락되어 3-노드 클러스터의 etcd 멤버가 실패할 수 있습니다. etcd 멤버를 복구하려면 다음 단계를 완료합니다.
프로세스
etcd 멤버가 실패하는지 확인해야 하는 경우 다음 명령을 입력합니다.
$ oc get pods -l app=etcd -n <control_plane_namespace>
etcd 멤버가 실패하는 경우 출력은 이 예와 유사합니다.
출력 예
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 64m etcd-1 2/2 Running 0 45m etcd-2 1/2 CrashLoopBackOff 1 (5s ago) 64m
다음 명령을 입력하여 실패한 etcd 멤버 및 pod의 영구 볼륨 클레임을 삭제합니다.
$ oc delete pvc/<pvc_name> pod/<etcd_pod_name> --wait=false
pod가 다시 시작되면 다음 명령을 입력하여 etcd 멤버가 etcd 클러스터에 다시 추가되고 올바르게 작동하는지 확인합니다.
$ oc get pods -l app=etcd -n <control_plane_namespace>
출력 예
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 67m etcd-1 2/2 Running 0 48m etcd-2 2/2 Running 0 2m2s
7.2. AWS의 호스트 클러스터에서 etcd 백업 및 복원
OpenShift Container Platform에 호스팅되는 컨트롤 플레인을 사용하는 경우 etcd를 백업하고 복원하는 프로세스는 일반적인 etcd 백업 프로세스 와 다릅니다.
다음 절차는 AWS의 호스팅 컨트롤 플레인에만 해당합니다.
AWS 플랫폼의 호스팅 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
7.2.1. 호스팅된 클러스터에서 etcd의 스냅샷 생성
호스팅된 클러스터의 etcd를 백업하는 프로세스의 일부로 etcd의 스냅샷을 생성합니다. 스냅샷을 만든 후 예를 들어 재해 복구 작업의 일부로 복원할 수 있습니다.
이 절차에는 API 다운타임이 필요합니다.
절차
다음 명령을 입력하여 호스트 클러스터의 조정을 일시 중지합니다.
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"true"}}' --type=merge다음 명령을 입력하여 모든 etcd-writer 배포를 중지합니다.
$ oc scale deployment -n <hosted_cluster_namespace> --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver
etcd 스냅샷을 만들려면 다음 명령을 실행하여 각 etcd 컨테이너에서
exec명령을 사용하십시오.$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db
스냅샷 상태를 확인하려면 다음 명령을 실행하여 각 etcd 컨테이너에서
exec명령을 사용하십시오.$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db
다음 예와 같이 나중에 검색할 수 있는 스냅샷 데이터를 S3 버킷과 같이 복사합니다.
참고다음 예제에서는 서명 버전 2를 사용합니다. 서명 버전 4를 지원하는 리전에 있는 경우 us-east-2 리전과 같이 서명 버전 4를 사용합니다. 그렇지 않으면 서명 버전 2를 사용하여 스냅샷을 S3 버킷에 복사하는 경우 업로드에 실패하고 서명 버전 2가 더 이상 사용되지 않습니다.
예제
BUCKET_NAME=somebucket FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.db나중에 새 클러스터에서 스냅샷을 복원하려면 다음 예와 같이 호스팅된 클러스터 참조의 암호화 보안을 저장합니다.
예제
oc get hostedcluster $CLUSTER_NAME -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"CLUSTER_NAME-etcd-encryption-key"}} # Save this secret, or the key it contains so the etcd data can later be decrypted oc get secret ${CLUSTER_NAME}-etcd-encryption-key -o=jsonpath='{.data.key}'
다음 단계
etcd 스냅샷을 복원하십시오.
7.2.2. 호스트 클러스터에서 etcd 스냅샷 복원
호스팅된 클러스터에서 etcd 스냅샷이 있는 경우 복원할 수 있습니다. 현재 클러스터 생성 중에만 etcd 스냅샷을 복원할 수 있습니다.
etcd 스냅샷을 복원하려면 create cluster --render 명령에서 출력을 수정하고 HostedCluster 사양의 etcd 섹션에 restoreSnapshotURL 값을 정의합니다.
사전 요구 사항
호스팅된 클러스터에서 etcd 스냅샷을 작성했습니다.
절차
awsCLI(명령줄 인터페이스)에서 인증 정보를 etcd 배포에 전달하지 않고 S3에서 etcd 스냅샷을 다운로드할 수 있도록 사전 서명된 URL을 생성합니다.ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})URL을 참조하도록
HostedCluster사양을 수정합니다.spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
spec.secretEncryption.aescbc값에서 참조한 보안에 이전 단계에서 저장한 것과 동일한 AES 키가 포함되어 있는지 확인합니다.
7.3. 온프레미스 환경의 호스팅 클러스터에서 etcd 백업 및 복원
호스트 클러스터에서 etcd를 백업하고 복원하면 3개의 노드 클러스터의 etcd 멤버의 손상된 데이터 또는 누락된 데이터와 같은 오류를 해결할 수 있습니다. etcd 클러스터의 여러 멤버가 데이터 손실이 발생하거나 CrashLoopBackOff 상태인 경우 이 접근 방식은 etcd 쿼럼 손실을 방지하는 데 도움이 됩니다.
이 절차에는 API 다운타임이 필요합니다.
사전 요구 사항
-
oc및jq바이너리가 설치되어 있습니다.
절차
먼저 환경 변수를 설정하고 API 서버를 축소합니다.
다음 명령을 입력하여 호스팅된 클러스터에 대한 환경 변수를 설정하여 필요에 따라 값을 바꿉니다.
$ CLUSTER_NAME=my-cluster
$ HOSTED_CLUSTER_NAMESPACE=clusters
$ CONTROL_PLANE_NAMESPACE="${HOSTED_CLUSTER_NAMESPACE}-${CLUSTER_NAME}"다음 명령을 입력하여 호스팅 클러스터의 조정을 일시 중지하여 필요에 따라 값을 교체합니다.
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":"true"}}' --type=merge다음 명령을 입력하여 API 서버를 축소합니다.
kube-apiserver를 축소합니다.$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/kube-apiserver --replicas=0openshift-apiserver를 축소합니다.$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/openshift-apiserver --replicas=0openshift-oauth-apiserver를 축소 :$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/openshift-oauth-apiserver --replicas=0
다음으로 다음 방법 중 하나를 사용하여 etcd의 스냅샷을 만듭니다.
- 이전에 백업한 etcd 스냅샷을 사용합니다.
사용 가능한 etcd pod가 있는 경우 다음 단계를 완료하여 활성 etcd pod에서 스냅샷을 만듭니다.
다음 명령을 입력하여 etcd pod를 나열합니다.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcdPod 데이터베이스의 스냅샷을 가져와서 다음 명령을 입력하여 시스템에 로컬로 저장합니다.
$ ETCD_POD=etcd-0
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=https://localhost:2379 \ snapshot save /var/lib/snapshot.db다음 명령을 입력하여 스냅샷이 성공했는지 확인합니다.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/snapshot.db
다음 명령을 입력하여 스냅샷의 로컬 사본을 만듭니다.
$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/snapshot.db /tmp/etcd.snapshot.dbetcd 영구 스토리지에서 스냅샷 데이터베이스의 사본을 만듭니다.
다음 명령을 입력하여 etcd pod를 나열합니다.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd실행 중인 Pod를 찾아
ETCD_POD: ETCD_POD=etcd-0의 값으로 설정한 다음 다음 명령을 입력하여 스냅샷 데이터베이스를 복사합니다.$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/data/member/snap/db /tmp/etcd.snapshot.db
다음으로 다음 명령을 입력하여 etcd 상태 저장 세트를 축소합니다.
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=0다음 명령을 입력하여 두 번째 및 세 번째 멤버의 볼륨을 삭제합니다.
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pvc/data-etcd-2pod를 생성하여 첫 번째 etcd 멤버의 데이터에 액세스합니다.
다음 명령을 입력하여 etcd 이미지를 가져옵니다.
$ ETCD_IMAGE=$(oc get -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd -o jsonpath='{ .spec.template.spec.containers[0].image }')etcd 데이터에 액세스할 수 있는 pod를 만듭니다.
$ cat << EOF | oc apply -n ${CONTROL_PLANE_NAMESPACE} -f - apiVersion: apps/v1 kind: Deployment metadata: name: etcd-data spec: replicas: 1 selector: matchLabels: app: etcd-data template: metadata: labels: app: etcd-data spec: containers: - name: access image: $ETCD_IMAGE volumeMounts: - name: data mountPath: /var/lib command: - /usr/bin/bash args: - -c - |- while true; do sleep 1000 done volumes: - name: data persistentVolumeClaim: claimName: data-etcd-0 EOFetcd-datapod의 상태를 확인하고 다음 명령을 입력하여 실행할 때까지 기다립니다.$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd-data다음 명령을 입력하여
etcd-datapod의 이름을 가져옵니다.$ DATA_POD=$(oc get -n ${CONTROL_PLANE_NAMESPACE} pods --no-headers -l app=etcd-data -o name | cut -d/ -f2)
다음 명령을 입력하여 etcd 스냅샷을 포드에 복사합니다.
$ oc cp /tmp/etcd.snapshot.db ${CONTROL_PLANE_NAMESPACE}/${DATA_POD}:/var/lib/restored.snap.db다음 명령을 입력하여
etcd-data포드에서 이전 데이터를 제거합니다.$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm -rf /var/lib/data$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- mkdir -p /var/lib/data다음 명령을 입력하여 etcd 스냅샷을 복원합니다.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- etcdutl snapshot restore /var/lib/restored.snap.db \ --data-dir=/var/lib/data --skip-hash-check \ --name etcd-0 \ --initial-cluster-token=etcd-cluster \ --initial-cluster etcd-0=https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-1=https://etcd-1.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-2=https://etcd-2.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380 \ --initial-advertise-peer-urls https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380다음 명령을 입력하여 포드에서 임시 etcd 스냅샷을 제거하십시오.
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm /var/lib/restored.snap.db다음 명령을 입력하여 데이터 액세스 배포를 삭제합니다.
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} deployment/etcd-data다음 명령을 입력하여 etcd 클러스터를 확장합니다.
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=3etcd 멤버 pod가 반환되고 다음 명령을 입력하여 사용 가능한 것으로 보고할 때까지 기다립니다.
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd -w다음 명령을 입력하여 모든 etcd-writer 배포를 확장합니다.
$ oc scale deployment -n ${CONTROL_PLANE_NAMESPACE} --replicas=3 kube-apiserver openshift-apiserver openshift-oauth-apiserver
다음 명령을 입력하여 호스팅 클러스터의 조정을 복원합니다.
$ oc patch -n ${CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":""}}' --type=merge
7.4. AWS 리전에서 호스팅된 클러스터 재해 복구
호스팅된 클러스터에 재해 복구(DR)가 필요한 경우 호스팅된 클러스터를 AWS 내의 동일한 리전으로 복구할 수 있습니다. 예를 들어 관리 클러스터 업그레이드에 실패하고 호스트 클러스터가 읽기 전용 상태인 경우 DR이 필요합니다.
호스팅된 컨트롤 플레인은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
DR 프로세스에는 세 가지 주요 단계가 포함됩니다.
- 소스 관리 클러스터에서 호스트된 클러스터 백업
- 대상 관리 클러스터에서 호스팅 클러스터 복원
- 소스 관리 클러스터에서 호스팅 클러스터 삭제
프로세스 중에 워크로드가 계속 실행됩니다. 기간 동안 클러스터 API를 사용할 수 없지만 이는 작업자 노드에서 실행 중인 서비스에는 영향을 미치지 않습니다.
다음 예와 같이 소스 관리 클러스터와 대상 관리 클러스터에 모두 API 서버 URL을 유지하기 위해 --external-dns 플래그가 있어야 합니다.
예: 외부 DNS 플래그
--external-dns-provider=aws \ --external-dns-credentials=<AWS Credentials location> \ --external-dns-domain-filter=<DNS Base Domain>
이렇게 하면 서버 URL이 https://api-sample-hosted.sample-hosted.aws.openshift.com 로 끝납니다.
API 서버 URL을 유지하기 위해 --external-dns 플래그를 포함하지 않으면 호스팅된 클러스터를 마이그레이션할 수 없습니다.
7.4.1. 환경 및 컨텍스트 예
복원할 클러스터가 세 개 있는 시나리오를 고려하십시오. 두 개는 관리 클러스터이며 하나는 호스트 클러스터입니다. 컨트롤 플레인만 또는 컨트롤 플레인 및 노드를 복원할 수 있습니다. 시작하기 전에 다음 정보가 필요합니다.
- 소스 MGMT 네임스페이스: 소스 관리 네임스페이스
- 소스 MGMT ClusterName: 소스 관리 클러스터 이름
-
소스 MGMT Kubeconfig: 소스 관리
kubeconfig파일 -
대상 MGMT Kubeconfig: 대상 관리
kubeconfig파일 -
HC Kubeconfig: 호스팅된 클러스터
kubeconfig파일 - SSH 키 파일: SSH 공개 키
- 풀 시크릿: 릴리스 이미지에 액세스하는 풀 시크릿 파일
- AWS 인증 정보
- AWS 리전
- 기본 도메인: 외부 DNS로 사용할 DNS 기본 도메인
- S3 버킷 이름: etcd 백업을 업로드할 AWS 리전의 버킷
이 정보는 다음 예제 환경 변수에 표시됩니다.
환경 변수 예
SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
AWS_ZONE_ID="Z02718293M33QHDEQBROL"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
# DNS
AWS_ZONE_ID="Z07342811SH9AA102K1AC"
EXTERNAL_DNS_DOMAIN="hc.jpdv.aws.kerbeross.com"
7.4.2. 백업 및 복원 프로세스 개요
백업 및 복원 프로세스는 다음과 같이 작동합니다.
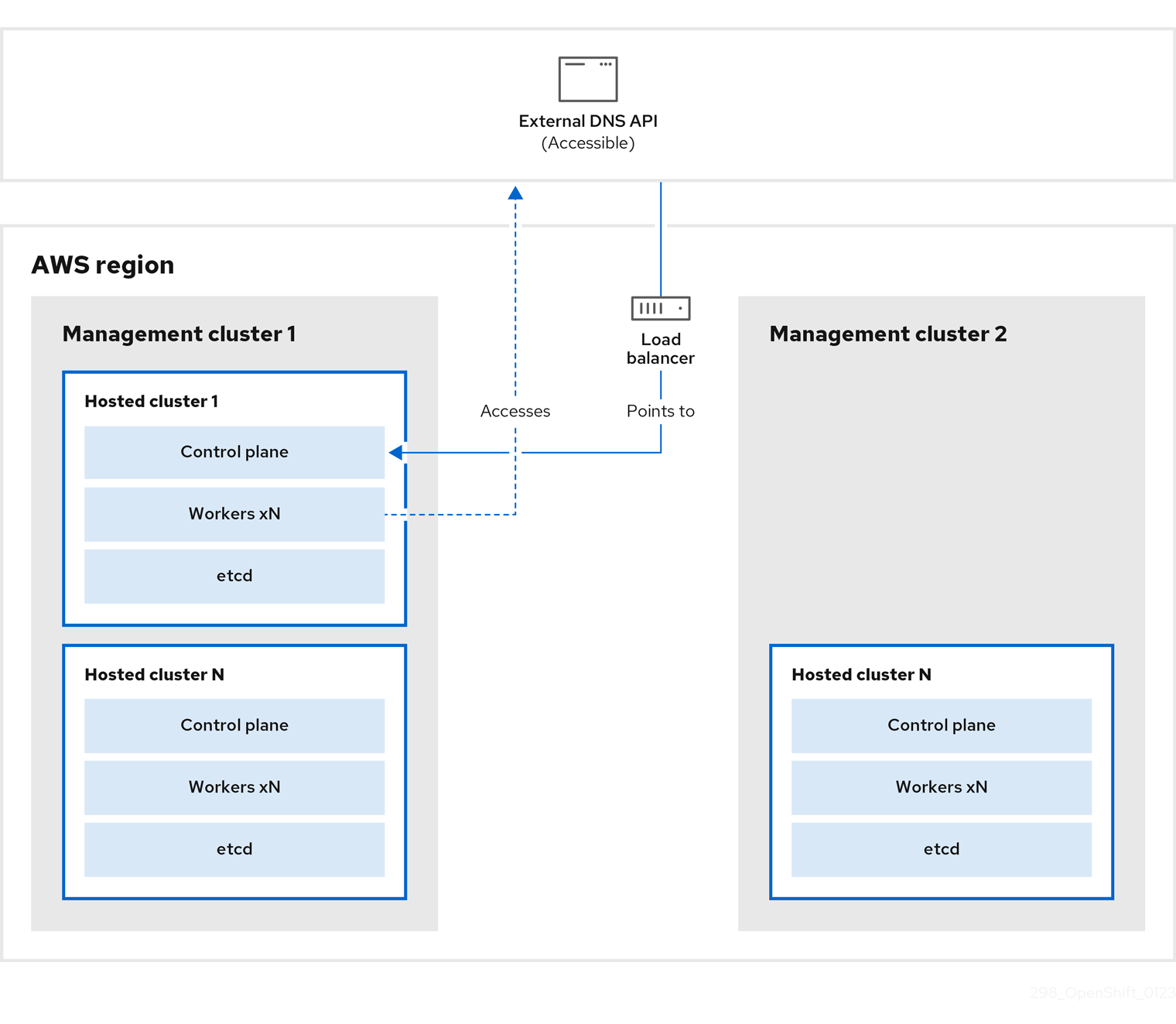
관리 클러스터 1에서 소스 관리 클러스터로 간주할 수 있는 컨트롤 플레인 및 작업자는 외부 DNS API를 사용하여 상호 작용합니다. 외부 DNS API에 액세스할 수 있으며 로드 밸런서는 관리 클러스터 간에 위치합니다.
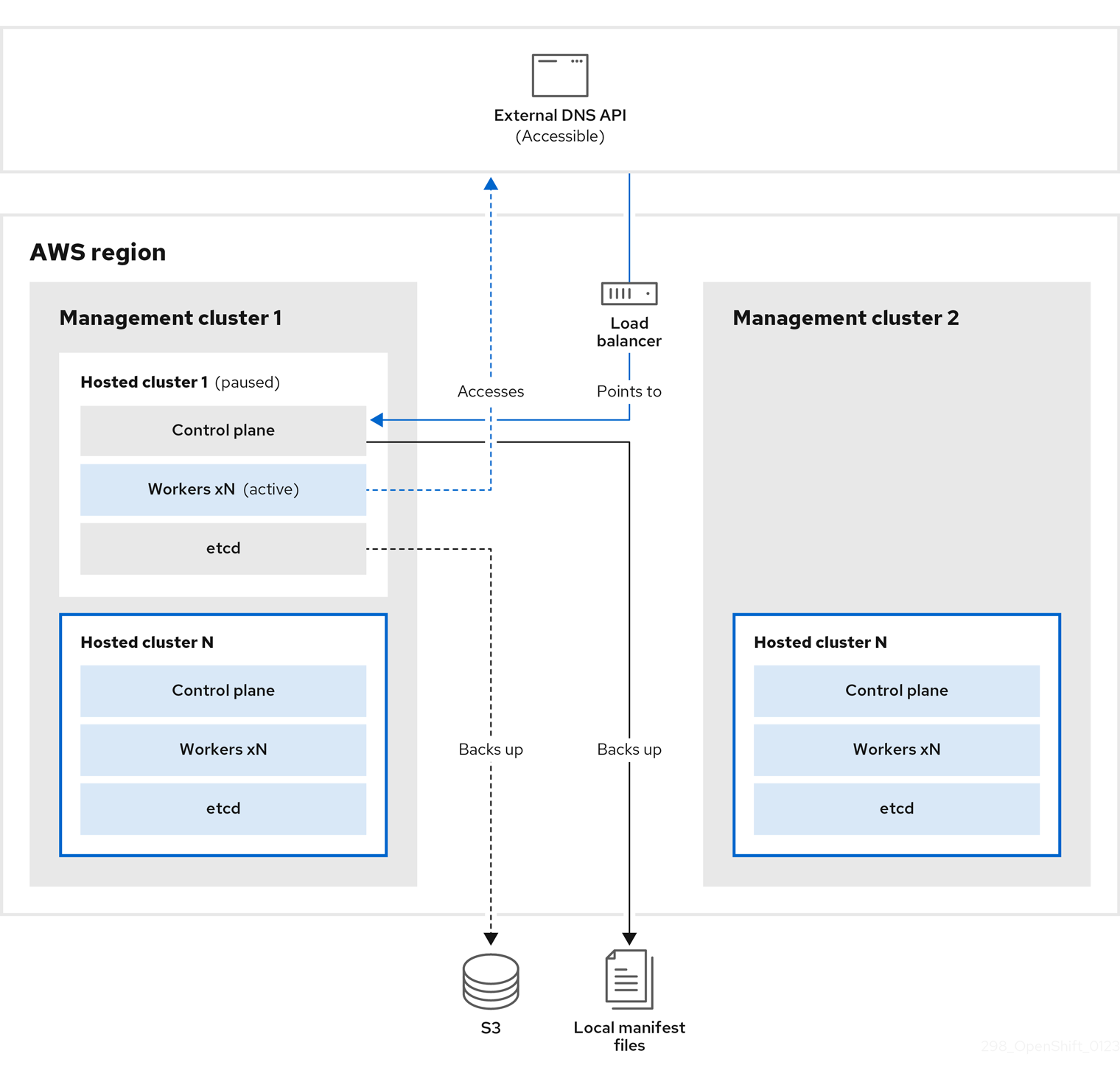
etcd, 컨트롤 플레인 및 작업자 노드가 포함된 호스팅 클러스터의 스냅샷을 생성합니다. 이 프로세스 중에 작업자 노드는 액세스할 수 없는 경우에도 외부 DNS API에 계속 액세스하려고 합니다. 워크로드가 실행 중이고 컨트롤 플레인은 로컬 매니페스트 파일에 저장되고 etcd는 S3 버킷으로 백업됩니다. 데이터 플레인이 활성 상태이고 컨트롤 플레인이 일시 중지되었습니다.
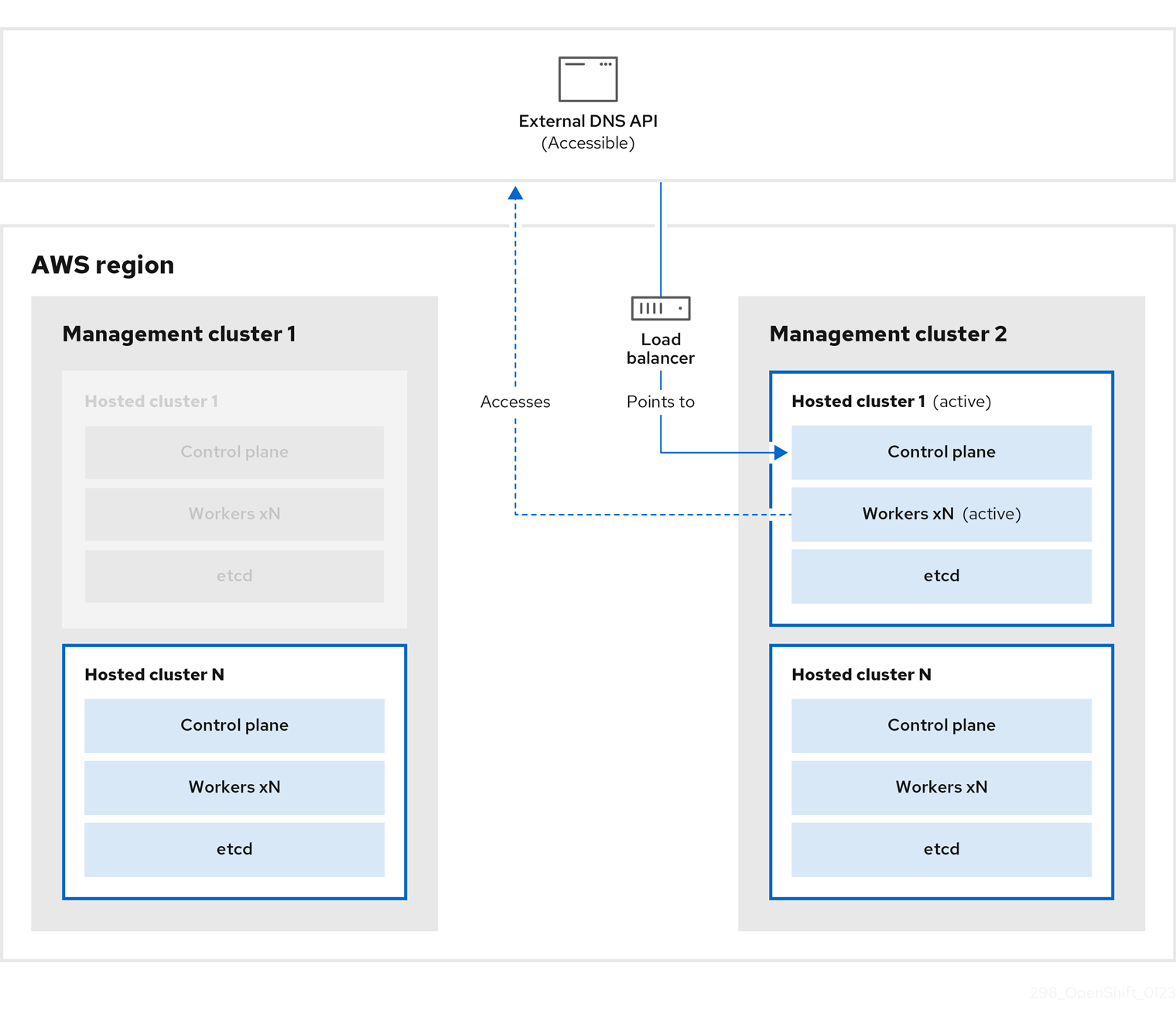
대상 관리 클러스터 2로 간주할 수 있는 관리 클러스터 2에서는 S3 버킷에서 etcd를 복원하고 로컬 매니페스트 파일에서 컨트롤 플레인을 복원합니다. 이 프로세스 중에 외부 DNS API가 중지되고 호스팅된 클러스터 API에 액세스할 수 없게 되고 API를 사용하는 모든 작업자는 매니페스트 파일을 업데이트할 수 없지만 워크로드는 여전히 실행 중입니다.
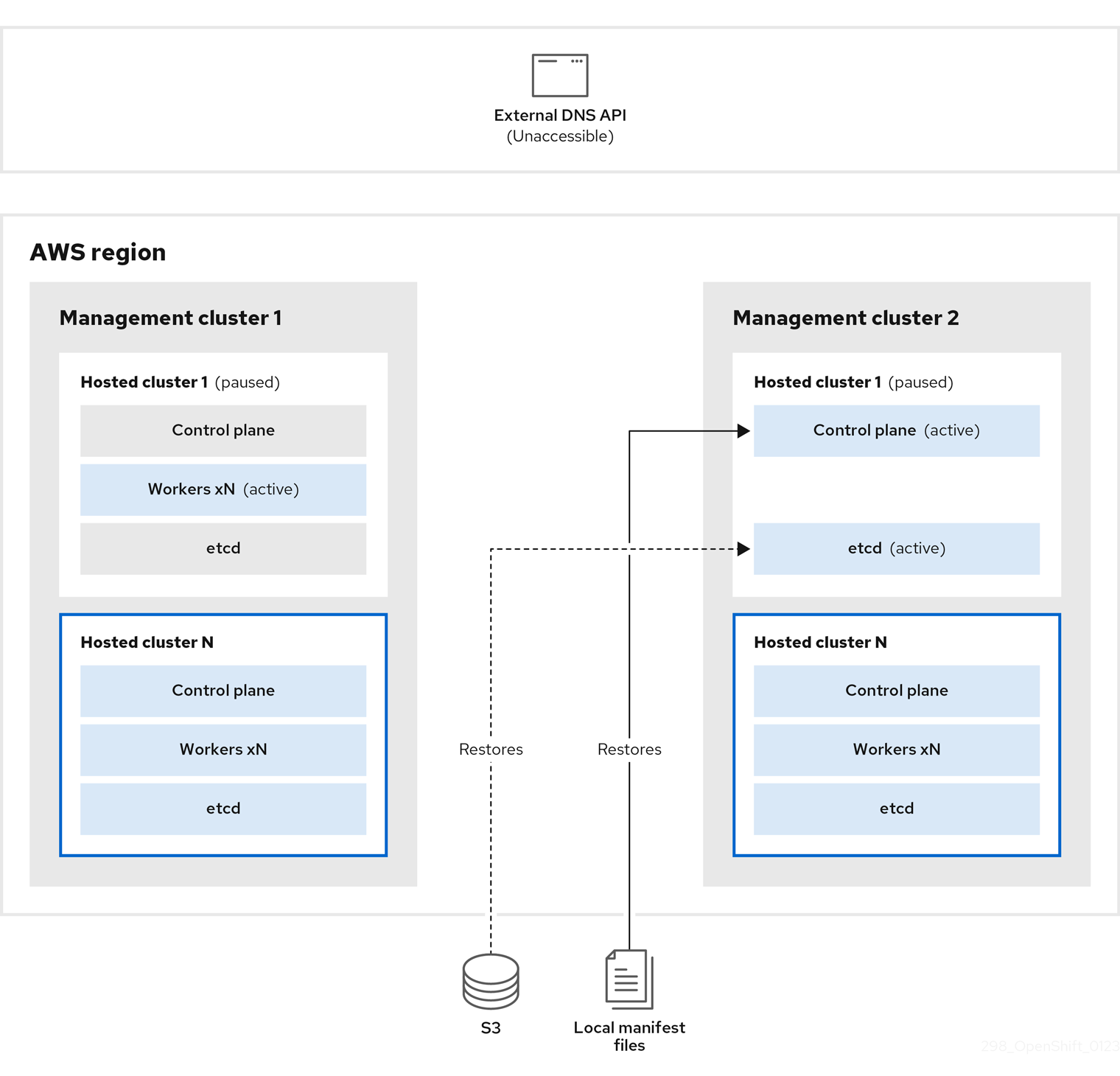
외부 DNS API에 다시 액세스할 수 있으며 작업자 노드는 이를 사용하여 관리 클러스터 2로 이동합니다. 외부 DNS API는 컨트롤 플레인을 가리키는 로드 밸런서에 액세스할 수 있습니다.
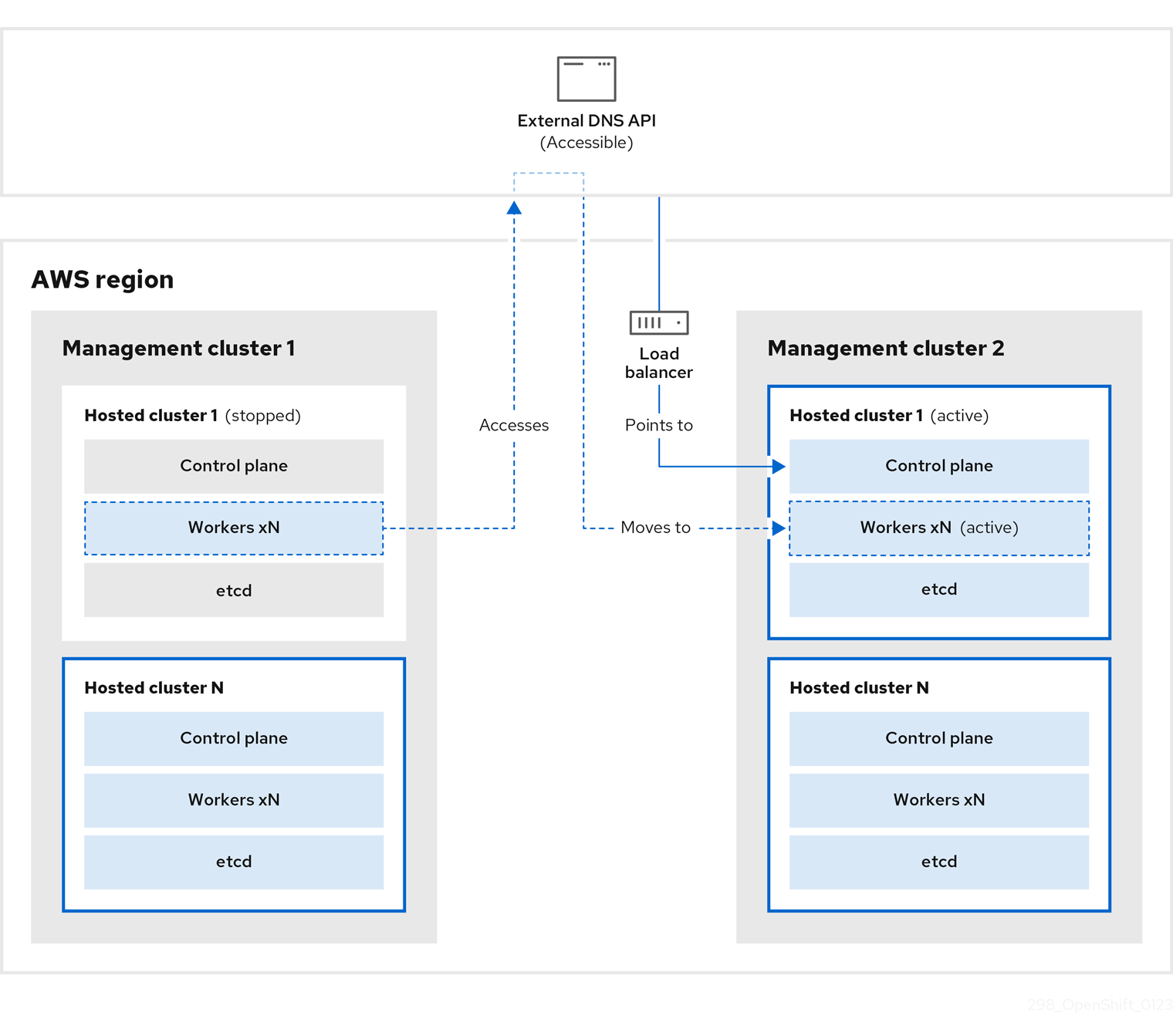
관리 클러스터 2에서 컨트롤 플레인 및 작업자 노드는 외부 DNS API를 사용하여 상호 작용합니다. etcd의 S3 백업을 제외하고 관리 클러스터 1에서 리소스가 삭제됩니다. 관리 클러스터 1에서 호스트 클러스터를 다시 설정하려고 하면 작동하지 않습니다.
호스팅된 클러스터를 수동으로 백업 및 복원하거나 스크립트를 실행하여 프로세스를 완료할 수 있습니다. 스크립트에 대한 자세한 내용은 "호스트된 클러스터를 백업하고 복원하기 위한 스크립트 실행"을 참조하십시오.
7.4.3. 호스팅된 클러스터 백업
대상 관리 클러스터에서 호스팅된 클러스터를 복구하려면 먼저 모든 관련 데이터를 백업해야 합니다.
절차
다음 명령을 입력하여 소스 관리 클러스터를 선언할 configmap 파일을 생성합니다.
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}다음 명령을 입력하여 호스팅된 클러스터 및 노드 풀에서 조정을 종료합니다.
PAUSED_UNTIL="true" oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operatorPAUSED_UNTIL="true" oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator이 bash 스크립트를 실행하여 etcd를 백업하고 S3 버킷에 데이터를 업로드합니다.
작은 정보이 스크립트를 함수로 래핑하고 기본 함수에서 호출합니다.
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneetcd 백업에 대한 자세한 내용은 "호스트 클러스터에서 etcd 백업 및 복원"을 참조하십시오.
다음 명령을 입력하여 Kubernetes 및 OpenShift Container Platform 오브젝트를 백업합니다. 다음 오브젝트를 백업해야 합니다.
-
HostedCluster 네임스페이스의
HostedCluster및NodePool오브젝트 -
HostedCluster 네임스페이스의
HostedCluster시크릿 -
HostedControl Plane 네임 스페이스의
HostedControlPlane -
호스팅 컨트롤 플레인 네임스페이스의
Cluster -
호스팅된 컨트롤 플레인 네임스페이스에서
AWSCluster,AWSMachineTemplate,AWSMachine -
Hosted Control Plane 네임스페이스에서
MachineDeployments,MachineSets,Machines 호스팅된 컨트롤 플레인 네임스페이스의
ControlPlane시크릿mkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster echo "Backing Up HostedCluster Objects:" oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml echo "--> HostedCluster" sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml echo "--> NodePool" sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane echo "--> HostedControlPlane:" oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster echo "--> Cluster:" CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster echo "--> AWS Cluster:" oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate echo "--> AWS Machine Template:" oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines echo "--> AWS Machine:" CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
HostedCluster 네임스페이스의
다음 명령을 입력하여
ControlPlane경로를 정리합니다.$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all해당 명령을 입력하면 ExternalDNS Operator가 Route53 항목을 삭제할 수 있습니다.
이 스크립트를 실행하여 Route53 항목이 정리되었는지 확인합니다.
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
검증
모든 OpenShift Container Platform 오브젝트 및 S3 버킷을 확인하여 모든 것이 예상대로 표시되는지 확인합니다.
다음 단계
호스팅된 클러스터를 복원합니다.
7.4.4. 호스팅된 클러스터 복원
백업한 모든 오브젝트를 수집하고 대상 관리 클러스터에 복원합니다.
사전 요구 사항
소스 관리 클러스터에서 데이터를 백업합니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정되거나 스크립트를 사용하는 경우 MGMT2_KUBECONFIG 변수에 배치되었는지 확인합니다. export KUBECONFIG=<Kubeconfig FilePath>를 사용하거나 스크립트를 사용하는 경우 export KUBECONFIG=$MGMT2_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여 복원 중인 클러스터의 네임스페이스가 새 관리 클러스터에 포함되어 있지 않은지 확인합니다.
# Just in case export KUBECONFIG=${MGMT2_KUBECONFIG} BACKUP_DIR=${HC_CLUSTER_DIR}/backup # Namespace deletion in the destination Management cluster $ oc delete ns ${HC_CLUSTER_NS} || true $ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true다음 명령을 입력하여 삭제된 네임스페이스를 다시 생성합니다.
# Namespace creation $ oc new-project ${HC_CLUSTER_NS} $ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}다음 명령을 입력하여 HC 네임스페이스에 보안을 복원합니다.
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*다음 명령을 입력하여
HostedCluster컨트롤 플레인 네임스페이스에서 오브젝트를 복원합니다.# Secrets $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-* # Cluster $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*노드와 노드 풀을 복구하여 AWS 인스턴스를 재사용하는 경우 다음 명령을 입력하여 HC 컨트롤 플레인 네임스페이스에서 오브젝트를 복원합니다.
# AWS $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-* # Machines $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*이 bash 스크립트를 실행하여 etcd 데이터 및 호스팅 클러스터를 복원합니다.
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fi노드와 노드 풀을 복구하여 AWS 인스턴스를 재사용하는 경우 다음 명령을 입력하여 노드 풀을 복원합니다.
oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
검증
노드가 완전히 복원되었는지 확인하려면 다음 기능을 사용합니다.
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
다음 단계
클러스터를 종료하고 삭제합니다.
7.4.5. 소스 관리 클러스터에서 호스트된 클러스터 삭제
호스팅된 클러스터를 백업하고 대상 관리 클러스터로 복원한 후 소스 관리 클러스터에서 호스팅된 클러스터를 종료하고 삭제합니다.
사전 요구 사항
데이터를 백업하고 소스 관리 클러스터에 복원했습니다.
대상 관리 클러스터의 kubeconfig 파일이 KUBECONFIG 변수에 설정되거나 스크립트를 사용하는 경우 MGMT_KUBECONFIG 변수에 배치되었는지 확인합니다. export KUBECONFIG=<Kubeconfig FilePath>를 사용하거나 스크립트를 사용하는 경우 export KUBECONFIG=$MGMT_KUBECONFIG} 를 사용합니다.
절차
다음 명령을 입력하여
deployment및statefulset오브젝트를 확장합니다.중요spec.persistentVolumeClaimRetentionPolicy.whenScaled필드의 값이Delete로 설정된 경우 데이터 손실이 발생할 수 있으므로 상태 저장 세트를 스케일링하지 마십시오.이 문제를 해결하려면
spec.persistentVolumeClaimRetentionPolicy.whenScaled필드의 값을Retain으로 업데이트합니다. 상태 저장 세트를 조정하는 컨트롤러가 없는지 확인하고 값을Delete로 다시 반환하여 데이터가 손실될 수 있습니다.# Just in case export KUBECONFIG=${MGMT_KUBECONFIG} # Scale down deployments oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all sleep 15다음 명령을 입력하여
NodePool오브젝트를 삭제합니다.NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi다음 명령을 입력하여
machine및machineset오브젝트를 삭제합니다.# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true다음 명령을 입력하여 클러스터 오브젝트를 삭제합니다.
# Cluster C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all이러한 명령을 입력하여 AWS 머신(Kubernetes 오브젝트)을 삭제합니다. 실제 AWS 머신 삭제에 대해 우려하지 마십시오. 클라우드 인스턴스는 영향을 받지 않습니다.
# AWS Machines for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done다음 명령을 입력하여
HostedControlPlane및ControlPlaneHC 네임스페이스 오브젝트를 삭제합니다.# Delete HCP and ControlPlane HC NS oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true다음 명령을 입력하여
HostedCluster및 HC 네임스페이스 오브젝트를 삭제합니다.# Delete HC and HC Namespace oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true oc delete ns ${HC_CLUSTER_NS} || true
검증
모든 것이 작동하는지 확인하려면 다음 명령을 입력합니다.
# Validations export KUBECONFIG=${MGMT2_KUBECONFIG} oc get hc -n ${HC_CLUSTER_NS} oc get np -n ${HC_CLUSTER_NS} oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} # Inside the HostedCluster export KUBECONFIG=${HC_KUBECONFIG} oc get clusterversion oc get nodes
다음 단계
새 관리 클러스터에서 실행되는 새 OVN 컨트롤 플레인에 연결할 수 있도록 호스팅 클러스터에서 OVN Pod를 삭제합니다.
-
호스팅 클러스터의 kubeconfig 경로를 사용하여
KUBECONFIG환경 변수를 로드합니다. 다음 명령을 입력합니다.
$ oc delete pod -n openshift-ovn-kubernetes --all
7.4.6. 스크립트를 실행하여 호스트 클러스터를 백업 및 복원
프로세스를 가속화하여 호스팅 클러스터를 백업하고 AWS의 동일한 리전 내에서 복원하려면 스크립트를 수정하고 실행할 수 있습니다.
절차
다음 스크립트의 변수를 자체 정보로 교체합니다.
# Fill the Common variables to fit your environment, this is just a sample SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub BASE_PATH=${HOME}/hypershift BASE_DOMAIN="aws.sample.com" PULL_SECRET_FILE="${HOME}/pull_secret.json" AWS_CREDS="${HOME}/.aws/credentials" CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"} NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2} # MGMT Context MGMT_REGION=us-west-1 MGMT_CLUSTER_NAME="${USER}-dev" MGMT_CLUSTER_NS=${USER} MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}" MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig" # MGMT2 Context MGMT2_CLUSTER_NAME="${USER}-dest" MGMT2_CLUSTER_NS=${USER} MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}" MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig" # Hosted Cluster Context HC_CLUSTER_NS=clusters HC_REGION=us-west-1 HC_CLUSTER_NAME="${USER}-hosted" HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig" BACKUP_DIR=${HC_CLUSTER_DIR}/backup BUCKET_NAME="${USER}-hosted-${MGMT_REGION}" # DNS AWS_ZONE_ID="Z026552815SS3YPH9H6MG" EXTERNAL_DNS_DOMAIN="guest.jpdv.aws.kerbeross.com"- 스크립트를 로컬 파일 시스템에 저장합니다.
다음 명령을 입력하여 스크립트를 실행합니다.
source <env_file>
여기서:
env_file은 스크립트를 저장한 파일의 이름입니다.마이그레이션 스크립트는 다음 리포지토리에서 유지 관리됩니다. https://github.com/openshift/hypershift/blob/main/contrib/migration/migrate-hcp.sh.
8장. 호스트된 컨트롤 플레인 문제 해결
호스트된 컨트롤 플레인에 문제가 있는 경우 다음 정보를 참조하여 문제 해결을 안내하십시오.
8.1. 호스트된 컨트롤 플레인 문제를 해결하기 위한 정보 수집
호스팅된 컨트롤 플레인 클러스터 문제를 해결해야 하는 경우 hypershift dump cluster 명령을 실행하여 정보를 수집할 수 있습니다. 명령은 관리 클러스터 및 호스팅 클러스터에 대한 출력을 생성합니다.
관리 클러스터의 출력에는 다음 내용이 포함됩니다.
- 클러스터 범위 리소스: 이러한 리소스는 관리 클러스터의 노드 정의입니다.
-
hypershift-dump압축 파일: 이 파일은 다른 사용자와 콘텐츠를 공유해야 하는 경우에 유용합니다. - 네임스페이스 리소스: 이러한 리소스에는 구성 맵, 서비스, 이벤트 및 로그와 같은 관련 네임스페이스의 모든 오브젝트가 포함됩니다.
- 네트워크 로그: 이 로그에는 OVN northbound 및 southbound 데이터베이스와 각각에 대한 상태가 포함됩니다.
- 호스트 클러스터: 이 수준의 출력에는 호스팅된 클러스터 내부의 모든 리소스가 포함됩니다.
호스팅 클러스터의 출력에는 다음 내용이 포함됩니다.
- 클러스터 범위 리소스: 이러한 리소스에는 노드 및 CRD와 같은 모든 클러스터 전체 오브젝트가 포함됩니다.
- 네임스페이스 리소스: 이러한 리소스에는 구성 맵, 서비스, 이벤트 및 로그와 같은 관련 네임스페이스의 모든 오브젝트가 포함됩니다.
출력에 클러스터의 보안 오브젝트가 포함되어 있지 않지만 보안 이름에 대한 참조를 포함할 수 있습니다.
사전 요구 사항
-
관리 클러스터에 대한
cluster-admin액세스 권한이 있어야 합니다. -
HostedCluster리소스의name값과 CR이 배포된 네임스페이스가 필요합니다. -
hcp명령줄 인터페이스가 설치되어 있어야 합니다. 자세한 내용은 호스팅된 컨트롤 플레인 명령줄 인터페이스 설치를 참조하십시오. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다. -
kubeconfig파일이 로드되고 관리 클러스터를 가리키는지 확인해야 합니다.
프로세스
문제 해결을 위해 출력을 수집하려면 다음 명령을 입력합니다.
$ hypershift dump cluster \ --name <hosted_cluster_name> \1 --namespace <hosted_cluster_namespace> \ 2 --dump-guest-cluster \ --artifact-dir clusterDump-<hosted_cluster_namespace>-<hosted_cluster_name>출력 예
2023-06-06T12:18:20+02:00 INFO Archiving dump {"command": "tar", "args": ["-cvzf", "hypershift-dump.tar.gz", "cluster-scoped-resources", "event-filter.html", "namespaces", "network_logs", "timestamp"]} 2023-06-06T12:18:21+02:00 INFO Successfully archived dump {"duration": "1.519376292s"}사용자 이름 또는 서비스 계정을 사용하여 관리 클러스터에 대한 모든 쿼리를 가장하도록 명령줄 인터페이스를 구성하려면
--as플래그를 사용하여hypershift dump cluster명령을 입력합니다.서비스 계정에는 네임스페이스에서 모든 오브젝트를 쿼리할 수 있는 충분한 권한이 있어야 하므로 충분한 권한이 있는지 확인하려면
cluster-admin역할을 사용하는 것이 좋습니다. 서비스 계정은HostedControlPlane리소스의 네임스페이스를 쿼리할 수 있는 권한이 있거나 있어야 합니다.사용자 이름 또는 서비스 계정에 충분한 권한이 없는 경우 출력에는 액세스할 수 있는 권한이 있는 오브젝트만 포함됩니다. 이 과정에서
forbidden오류가 표시될 수 있습니다.서비스 계정을 사용하여 가장을 사용하려면 다음 명령을 입력합니다.
$ hypershift dump cluster \ --name <hosted_cluster_name> \1 --namespace <hosted_cluster_namespace> \2 --dump-guest-cluster \ --as "system:serviceaccount:<service_account_namespace>:<service_account_name>" \ 3 --artifact-dir clusterDump-<hosted_cluster_namespace>-<hosted_cluster_name>사용자 이름을 사용하여 가장을 사용하려면 다음 명령을 입력합니다.
$ hypershift dump cluster \ --name <hosted_cluster_name> \1 --namespace <hosted_cluster_namespace> \2 --dump-guest-cluster \ --as "<cluster_user_name>" \ 3 --artifact-dir clusterDump-<hosted_cluster_namespace>-<hosted_cluster_name>
8.2. 호스트 클러스터 및 호스팅된 컨트롤 플레인의 조정 일시 중지
클러스터 인스턴스 관리자인 경우 호스트 클러스터 및 호스팅된 컨트롤 플레인의 조정을 일시 중지할 수 있습니다. etcd 데이터베이스를 백업 및 복원하거나 호스팅된 클러스터 또는 호스팅된 컨트롤 플레인 문제를 디버깅해야 하는 경우 조정을 일시 중지해야 할 수 있습니다.
프로세스
호스트 클러스터 및 호스팅된 컨트롤 플레인에 대한 조정을 일시 중지하려면
HostedCluster리소스의pausedUntil필드를 채웁니다.특정 시간까지 조정을 일시 중지하려면 다음 명령을 입력합니다.
$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"<timestamp>"}}' --type=merge 1- 1
- RFC339 형식으로 타임스탬프를 지정합니다(예:
2024-03-03T03:28:48Z). 지정된 시간이 전달될 때까지 조정이 일시 중지됩니다.
조정을 무기한 일시 중지하려면 다음 명령을 입력합니다.
$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"true"}}' --type=mergeHostedCluster리소스에서 필드를 제거할 때까지 조정이 일시 중지됩니다.HostedCluster리소스에 대한 일시 중지 조정 필드가 채워지면 관련HostedControlPlane리소스에 필드가 자동으로 추가됩니다.
pausedUntil필드를 제거하려면 다음 패치 명령을 입력합니다.$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":null}}' --type=merge
8.3. 데이터 플레인을 0으로 축소
호스팅된 컨트롤 플레인을 사용하지 않는 경우 리소스 및 비용을 절약하기 위해 데이터 플레인을 0으로 축소할 수 있습니다.
데이터 플레인을 0으로 축소할 준비가 되었는지 확인합니다. 작업자 노드의 워크로드는 축소 후 사라집니다.
프로세스
다음 명령을 실행하여 호스팅 클러스터에 액세스하도록
kubeconfig파일을 설정합니다.$ export KUBECONFIG=<install_directory>/auth/kubeconfig
다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스의 이름을 가져옵니다.$ oc get nodepool --namespace <HOSTED_CLUSTER_NAMESPACE>
선택 사항: Pod가 드레이닝되지 않도록 다음 명령을 실행하여
NodePool리소스에nodeDrainTimeout필드를 추가합니다.$ oc edit NodePool <nodepool> -o yaml --namespace <HOSTED_CLUSTER_NAMESPACE>
출력 예
apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: arch: amd64 clusterName: clustername 1 management: autoRepair: false replace: rollingUpdate: maxSurge: 1 maxUnavailable: 0 strategy: RollingUpdate upgradeType: Replace nodeDrainTimeout: 0s 2 # ...
참고노드 드레이닝 프로세스가 일정 기간 동안 계속될 수 있도록
nodeDrainTimeout필드의 값을 적절하게 설정할 수 있습니다(예:nodeDrainTimeout: 1m).다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스를 축소합니다.$ oc scale nodepool/<NODEPOOL_NAME> --namespace <HOSTED_CLUSTER_NAMESPACE> --replicas=0
참고데이터 계획을 0으로 축소한 후 컨트롤 플레인의 일부 Pod는
Pending상태를 유지하고 호스팅된 컨트롤 플레인은 계속 실행 중입니다. 필요한 경우NodePool리소스를 확장할 수 있습니다.선택 사항: 다음 명령을 실행하여 호스팅된 클러스터에 연결된
NodePool리소스를 확장합니다.$ oc scale nodepool/<NODEPOOL_NAME> --namespace <HOSTED_CLUSTER_NAMESPACE> --replicas=1
NodePool리소스를 다시 확장한 후NodePool리소스가Ready상태에서 사용 가능하게 될 때까지 몇 분 정도 기다립니다.
검증
다음 명령을 실행하여
nodeDrainTimeout필드의 값이0s보다 큰지 확인합니다.$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -ojsonpath='{.spec.nodeDrainTimeout}'
추가 리소스