
Hosted Control Plane
OpenShift Container Platform で Hosted Control Plane を使用する
概要
第1章 Hosted Control Plane の概要
OpenShift Container Platform クラスターは、スタンドアロンまたは Hosted Control Plane という 2 つの異なるコントロールプレーン構成を使用してデプロイできます。スタンドアロン構成では、専用の仮想マシンまたは物理マシンを使用してコントロールプレーンをホストします。OpenShift Container Platform の Hosted Control Plane を使用すると、各コントロールプレーンに専用の仮想マシンまたは物理マシンを用意する必要なく、ホスティングクラスター上の Pod としてコントロールプレーンを作成できます。
1.1. Hosted Control Plane の概要
Red Hat OpenShift Container Platform の Hosted Control Plane を使用すると、管理コストを削減し、クラスターのデプロイ時間を最適化し、管理とワークロードの問題を分離して、アプリケーションに集中できるようになります。
Hosted Control Plane は、次のプラットフォームで Kubernetes Operator バージョン 2.0 以降のマルチクラスターエンジン を使用することで利用できます。
- Agent プロバイダーを使用したベアメタル
- OpenShift Virtualization
- Amazon Web Services (AWS) (テクノロジープレビュー機能)
- IBM Z (テクノロジープレビュー機能)
- IBM Power (テクノロジープレビュー機能)
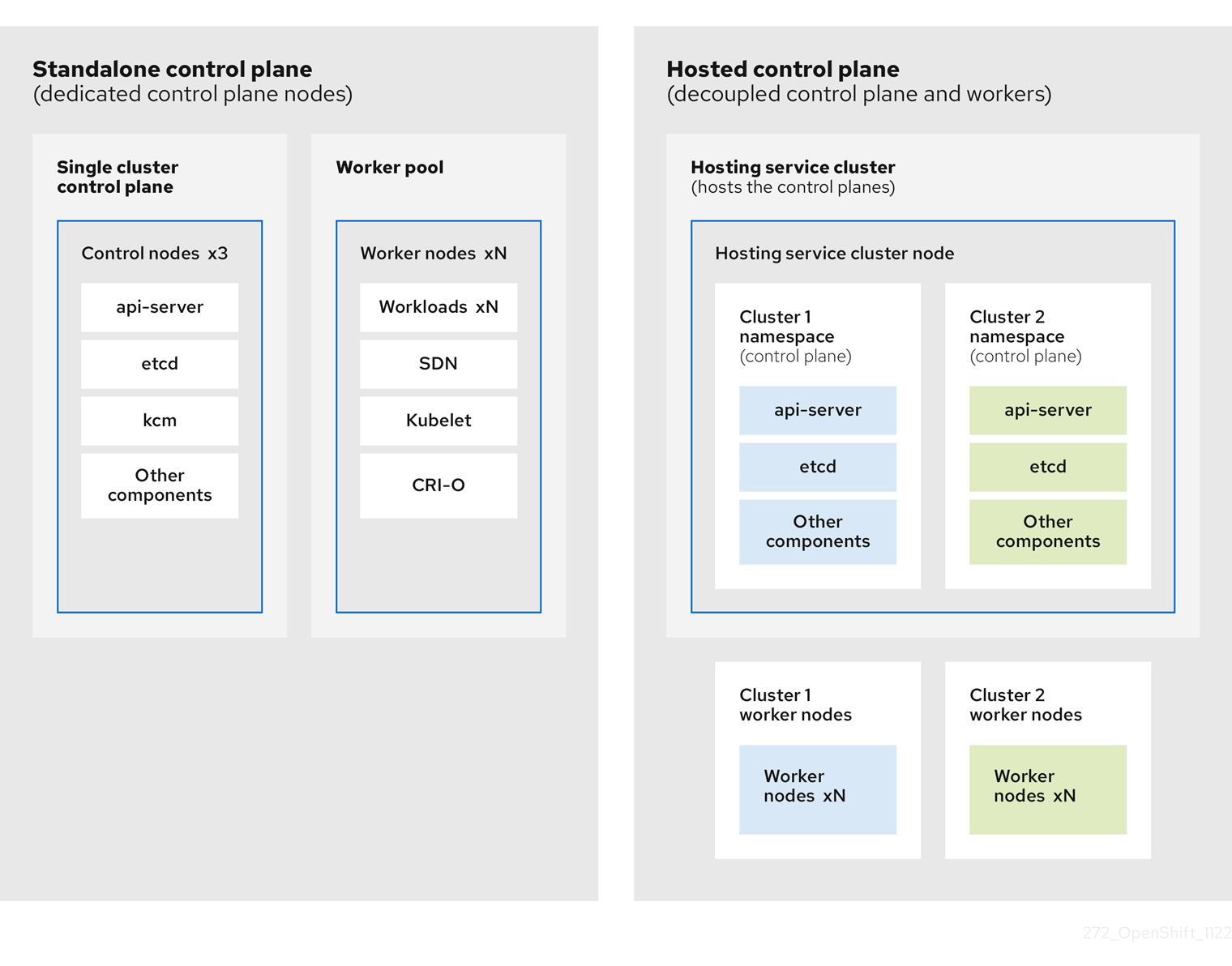
1.1.1. Hosted control plane のアーキテクチャー
OpenShift Container Platform は、多くの場合、クラスターがコントロールプレーンとデータプレーンで設定される結合モデルまたはスタンドアロンモデルでデプロイされます。コントロールプレーンには、API エンドポイント、ストレージエンドポイント、ワークロードスケジューラー、および状態を保証するアクチュエーターが含まれます。データプレーンには、ワークロードとアプリケーションが実行されるコンピューティング、ストレージ、ネットワークが含まれます。
スタンドアロンコントロールプレーンは、クォーラムを確保できる最小限の数で、物理または仮想のノードの専用グループによってホストされます。ネットワークスタックは共有されます。クラスターへの管理者アクセスにより、クラスターのコントロールプレーン、マシン管理 API、およびクラスターの状態に影響を与える他のコンポーネントを可視化できます。
スタンドアロンモデルは正常に機能しますが、状況によっては、コントロールプレーンとデータプレーンが分離されたアーキテクチャーが必要になります。そのような場合には、データプレーンは、専用の物理ホスティング環境がある別のネットワークドメインに配置されています。コントロールプレーンは、Kubernetes にネイティブなデプロイやステートフルセットなど、高レベルのプリミティブを使用してホストされます。コントロールプレーンは、他のワークロードと同様に扱われます。
1.1.2. Hosted Control Plane の利点
OpenShift Container Platform の Hosted Control Plane を使用すると、真のハイブリッドクラウドアプローチへの道が開かれ、その他のさまざまなメリットも享受できます。
- コントロールプレーンが分離され、専用のホスティングサービスクラスターでホストされるため、管理とワークロードの間のセキュリティー境界が強化されます。その結果、クラスターのクレデンシャルが他のユーザーに漏洩する可能性が低くなります。インフラストラクチャーのシークレットアカウント管理も分離されているため、クラスターインフラストラクチャーの管理者が誤ってコントロールプレーンインフラストラクチャーを削除することはありません。
- Hosted Control Plane を使用すると、より少ないノードで多数のコントロールプレーンを実行できます。その結果、クラスターはより安価になります。
- コントロールプレーンは OpenShift Container Platform で起動される Pod で設定されるため、コントロールプレーンはすぐに起動します。同じ原則が、モニタリング、ロギング、自動スケーリングなどのコントロールプレーンとワークロードに適用されます。
- インフラストラクチャーの観点からは、レジストリー、HAProxy、クラスター監視、ストレージノードなどのインフラストラクチャーをテナントのクラウドプロバイダーのアカウントにプッシュして、テナントでの使用を分離できます。
- 運用上の観点からは、マルチクラスター管理はさらに集約され、クラスターの状態と一貫性に影響を与える外部要因が少なくなります。Site Reliability Engineer は、一箇所で問題をデバッグして、クラスターのデータプレインを移動するため、解決までの時間 (TTR) が短縮され、生産性が向上します。
関連情報
1.2. Hosted control plane の一般的な概念とペルソナの用語集
OpenShift Container Platform の Hosted Control Plane を使用する場合は、その主要な概念と関連するペルソナを理解することが重要です。
1.2.1. 概念
- ホストされたクラスター
- 管理クラスター上でホストされるコントロールプレーンと API エンドポイントを備えた OpenShift Container Platform クラスター。ホストされたクラスターには、コントロールプレーンとそれに対応するデータプレーンが含まれます。
- ホストされたクラスターインフラストラクチャー
- テナントまたはエンドユーザーのクラウドアカウントに存在するネットワーク、コンピューティング、およびストレージリソース。
- Hosted Control Plane
- 管理クラスター上で実行している OpenShift Container Platform コントロールプレーン。ホストされたクラスターの API エンドポイントによって公開されます。コントロールプレーンのコンポーネントには、etcd、Kubernetes API サーバー、Kubernetes コントローラーマネージャー、および VPN が含まれます。
- ホスティングクラスター
- 管理クラスター を参照してください。
- マネージドクラスター
- ハブクラスターが管理するクラスター。この用語は、Kubernetes Operator のマルチクラスターエンジンが Red Hat Advanced Cluster Management で管理するクラスターのライフサイクルに固有のものです。マネージドクラスターは、管理クラスター とは異なります。詳細は、マネージドクラスター を参照してください。
- 管理クラスター
- HyperShift Operator がデプロイされ、ホストされたクラスターのコントロールプレーンがホストされる OpenShift Container Platform クラスター。管理クラスターは ホスティングクラスター と同義です。
- 管理クラスターインフラストラクチャー
- 管理クラスターのネットワーク、コンピューティング、およびストレージリソース。
1.2.2. ペルソナ
- クラスターインスタンス管理者
-
このロールを引き受けるユーザーは、スタンドアロン OpenShift Container Platform の管理者と同等です。このユーザーには、プロビジョニングされたクラスター内で
cluster-adminロールがありますが、クラスターがいつ、どのように更新または設定されるかを制御できない可能性があります。このユーザーは、クラスターに投影された設定を表示するための読み取り専用アクセス権を持っている可能性があります。 - クラスターインスタンスユーザー
- このロールを引き受けるユーザーは、スタンドアロン OpenShift Container Platform の開発者と同等です。このユーザーには、OperatorHub またはマシンに対するビューがありません。
- クラスターサービスコンシューマー
- このロールを引き受けるユーザーは、コントロールプレーンとワーカーノードを要求したり、更新を実行したり、外部化された設定を変更したりできます。通常、このユーザーはクラウド認証情報やインフラストラクチャー暗号化キーを管理したりアクセスしたりしません。クラスターサービスのコンシューマーペルソナは、ホストされたクラスターを要求し、ノードプールと対話できます。このロールを引き受けるユーザーには、論理境界内でホストされたクラスターとノードプールを作成、読み取り、更新、または削除するための RBAC があります。
- クラスターサービスプロバイダー
このロールを引き受けるユーザーは通常、管理クラスター上で
cluster-adminロールを持ち、HyperShift Operator とテナントのホストされたクラスターのコントロールプレーンの可用性を監視および所有するための RBAC を持っています。クラスターサービスプロバイダーのペルソナは、次の例を含むいくつかのアクティビティーを担当します。- コントロールプレーンの可用性、稼働時間、安定性を確保するためのサービスレベルオブジェクトの所有
- コントロールプレーンをホストするための管理クラスターのクラウドアカウントの設定
- ユーザーがプロビジョニングするインフラストラクチャーの設定 (利用可能なコンピュートリソースのホスト認識を含む)
1.3. Hosted Control Plane のバージョン管理
OpenShift Container Platform のメジャー、マイナー、またはパッチバージョンのリリースごとに、 Hosted Control Plane の 2 つのコンポーネントがリリースされます。
- HyperShift Operator
-
hcpコマンドラインインターフェイス(CLI)
HyperShift Operator は、HostedCluster API リソースによって表されるホストされたクラスターのライフサイクルを管理します。HyperShift Operator は、OpenShift Container Platform の各リリースでリリースされます。HyperShift Operator は、hypershift namespace に supported-versions Config Map を作成します。設定マップには、サポートされているホストされたクラスターのバージョンが含まれています。
同じ管理クラスター上で異なるバージョンのコントロールプレーンをホストできます。
supported-versions 設定マップオブジェクトの例
apiVersion: v1
data:
supported-versions: '{"versions":["4.15"]}'
kind: ConfigMap
metadata:
labels:
hypershift.openshift.io/supported-versions: "true"
name: supported-versions
namespace: hypershift
hcp CLI を使用して、ホステッドクラスターを作成できます。
HostedCluster や NodePool などの hypershift.openshift.io API リソースを使用して、スケーリング時に OpenShift Container Platform クラスターを作成および管理できます。HostedCluster リソースには、コントロールプレーンと共通データプレーンの設定が含まれます。HostedCluster リソースを作成すると、ノードが接続されていない、完全に機能するコントロールプレーンが作成されます。NodePool リソースは、HostedCluster リソースにアタッチされたスケーラブルなワーカーノードのセットです。
API バージョンポリシーは、通常、Kubernetes API のバージョン管理 のポリシーと一致します。
1.4. Hosted Control Plane のアップグレードシナリオ
アップグレードする前に、以下を考慮してください。
- ベアメタルを管理クラスタープラットフォームとして使用する。
- エージェントまたは KubeVirt をホストされたクラスタープラットフォームとして使用する。
管理クラスターは、installer-provisioned infrastructure (IPI) をベースにしています。
以下のシナリオを確認してください。
- OpenShift Container Platform 4.14 で管理クラスターを実行している場合、マルチクラスターエンジン (MCE) バージョンを 2.4 から 2.5 にアップグレードできます。その後、ホストされたクラスターおよびノードプールを OpenShift Container Platform 4.14 から OpenShift Container Platform 4.15 にアップグレードできます。
管理クラスター、MCE、ホストされたクラスター、ノードプールを最新バージョンにアップグレードする場合は、以下を実行します。
- 管理クラスターを、OpenShift Container Platform 4.14 から OpenShift Container Platform 4.15 にアップグレードします。
- MCE バージョンを、2.4 から 2.5 にアップグレードします。
- ホストされたクラスターとノードプールを、OpenShift Container Platform 4.14 から OpenShift Container Platform 4.15 にアップグレードします。
第2章 Hosted Control Plane の使用開始
OpenShift Container Platform の Hosted Control Plane の使用を開始するには、まず、使用するプロバイダーでホストされたクラスターを設定します。次に、いくつかの管理タスクを完了します。
次のプロバイダーのいずれかを選択して、手順を表示できます。
2.1. ベアメタル
- Hosted control plane のサイジングに関するガイダンス
- Hosted control plane コマンドラインインターフェイスのインストール
- ホステッドクラスターのワークロードの分散
- ベアメタルのファイアウォールとポートの要件
- ベアメタルインフラストラクチャーの要件: ベアメタル上にホストされたクラスターを作成するためのインフラストラクチャー要件を確認します。
ベアメタル上で Hosted Control Plane クラスターを設定する
- DNS を設定する
- ホストされたクラスターを作成し、クラスターの作成を確認する
-
ホストされたクラスターの
NodePoolオブジェクトをスケーリングする - ホストされたクラスターの ingress トラフィックを処理する
- ホストされたクラスターのノードの自動スケーリングを有効にする
- 非接続環境での Hosted control plane の設定
- ベアメタル上のホストされたクラスターを破棄するには、ベアメタル上のホステッドクラスターの破棄 の手順に従ってください。
- Hosted Control Plane 機能を無効にする場合は、Hosted Control Plane 機能の無効化 を参照してください。
2.2. OpenShift Virtualization
- Hosted control plane のサイジングに関するガイダンス
- Hosted control plane コマンドラインインターフェイスのインストール
- ホステッドクラスターのワークロードの分散
- OpenShift Virtualization 上での Hosted Control Plane クラスターの管理: KubeVirt 仮想マシンによってホストされたワーカーノードを使用して OpenShift Container Platform クラスターを作成します。
- 非接続環境での Hosted control plane の設定
- OpenShift Virtualization 上でホストされているクラスターを破棄するには、OpenShift Virtualization 上のホステッドクラスターの破棄 の手順に従ってください。
- Hosted Control Plane 機能を無効にする場合は、Hosted Control Plane 機能の無効化 を参照してください。
2.3. Amazon Web Services (AWS)
AWS プラットフォーム上の Hosted Control Plane は、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
- AWS インフラストラクチャー要件: AWS 上にホストされたクラスターを作成するためのインフラストラクチャー要件を確認します。
- AWS で Hosted Control Plane クラスターを設定する (テクノロジープレビュー): AWS で Hosted Control Plane クラスターを設定するタスクには、AWS S3 OIDC シークレットの作成、ルーティング可能なパブリックゾーンの作成、外部 DNS の有効化、AWS PrivateLink の有効化、ホストされたクラスターのデプロイが含まれます。
- Hosted Control Plane 用 SR-IOV Operator のデプロイ: ホスティングサービスクラスターを設定してデプロイした後、ホストされたクラスター上で Single Root I/O Virtualization (SR-IOV) Operator へのサブスクリプションを作成できます。SR-IOV Pod は、コントロールプレーンではなくワーカーマシンで実行されます。
- AWS でホストされているクラスターを破棄するには、AWS 上のホステッドクラスターの破棄 の手順に従ってください。
- Hosted Control Plane 機能を無効にする場合は、Hosted Control Plane 機能の無効化 を参照してください。
2.4. IBM Z
IBM Z プラットフォーム上の Hosted Control Plane は、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
2.5. IBM Power
IBM Power プラットフォーム上の Hosted Control Plane は、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
2.6. 非ベアメタルエージェントマシン
非ベアメタルエージェントマシンを使用する Hosted Control Plane クラスターは、テクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
- Hosted control plane コマンドラインインターフェイスのインストール
- 非ベアメタルエージェントマシンを使用した Hosted Control Plane クラスターの設定 (テクノロジープレビュー)
- ベアメタルエージェント以外のマシンでホストされているクラスターを破棄するには、非ベアメタルエージェントマシン上のホステッドクラスターの破棄 の手順に従ってください。
- Hosted Control Plane 機能を無効にする場合は、Hosted Control Plane 機能の無効化 を参照してください。
第3章 Hosted Control Plane の認証と認可
OpenShift Container Platform のコントロールプレーンには、組み込みの OAuth サーバーが含まれています。OAuth アクセストークンを取得することで、OpenShift Container Platform API に対して認証できます。ホストされたクラスターを作成した後に、アイデンティティープロバイダーを指定して OAuth を設定できます。
3.1. CLI を使用してホストされたクラスターの OAuth サーバーを設定する
OpenID Connect アイデンティティープロバイダー (oidc) を使用して、ホストされたクラスターの内部 OAuth サーバーを設定できます。
サポートされている次のアイデンティティープロバイダーに対して OAuth を設定できます。
-
oidc -
htpasswd -
keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
OAuth 設定にアイデンティティープロバイダーを追加すると、デフォルトの kubeadmin ユーザープロバイダーが削除されます。
前提条件
- ホストされたクラスターを作成した。
手順
次のコマンドを実行して、ホスティングクラスターで
HostedClusterカスタムリソース (CR) を編集します。$ oc edit <hosted_cluster_name> -n <hosted_cluster_namespace>
次の例を使用して、
HostedClusterCR に OAuth 設定を追加します。apiVersion: hypershift.openshift.io/v1alpha1 kind: HostedCluster metadata: name: <hosted_cluster_name> 1 namespace: <hosted_cluster_namespace> 2 spec: configuration: oauth: identityProviders: - openID: 3 claims: email: 4 - <email_address> name: 5 - <display_name> preferredUsername: 6 - <preferred_username> clientID: <client_id> 7 clientSecret: name: <client_id_secret_name> 8 issuer: https://example.com/identity 9 mappingMethod: lookup 10 name: IAM type: OpenID
- 1
- ホストされたクラスターの名前を指定します。
- 2
- ホストされたクラスターの namespace を指定します。
- 3
- このプロバイダー名はアイデンティティー要求の値に接頭辞として付加され、アイデンティティー名が作成されます。プロバイダー名はリダイレクト URL の構築にも使用されます。
- 4
- メールアドレスとして使用する属性のリストを定義します。
- 5
- 表示名として使用する属性のリストを定義します。
- 6
- 優先ユーザー名として使用する属性のリストを定義します。
- 7
- OpenID プロバイダーに登録されたクライアントの ID を定義します。このクライアントを URL
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>にリダイレクトできるようにする必要があります。 - 8
- OpenID プロバイダーに登録されたクライアントのシークレットを定義します。
- 9
- OpenID の仕様で説明されている Issuer Identifier。クエリーまたはフラグメントコンポーネントのない
httpsを使用する必要があります。 - 10
- このプロバイダーのアイデンティティーと
Userオブジェクトの間でマッピングを確立する方法を制御するマッピング方法を定義します。
- 変更を適用するためにファイルを保存します。
3.2. Web コンソールを使用してホストされたクラスターの OAuth サーバーを設定する
OpenShift Container Platform Web コンソールを使用して、ホストされたクラスターの内部 OAuth サーバーを設定できます。
サポートされている次のアイデンティティープロバイダーに対して OAuth を設定できます。
-
oidc -
htpasswd -
keystone -
ldap -
basic-authentication -
request-header -
github -
gitlab -
google
OAuth 設定にアイデンティティープロバイダーを追加すると、デフォルトの kubeadmin ユーザープロバイダーが削除されます。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。 - ホストされたクラスターを作成した。
手順
- Home → API Explorer に移動します。
-
Filter by kind ボックスを使用して、
HostedClusterリソースを検索します。 -
編集する
HostedClusterリソースをクリックします。 - Instances タブをクリックします。
-
ホストされたクラスター名エントリーの横にあるオプションメニュー
 をクリックし、Edit HostedCluster をクリックします。
をクリックし、Edit HostedCluster をクリックします。
YAML ファイルに OAuth 設定を追加します。
spec: configuration: oauth: identityProviders: - openID: 1 claims: email: 2 - <email_address> name: 3 - <display_name> preferredUsername: 4 - <preferred_username> clientID: <client_id> 5 clientSecret: name: <client_id_secret_name> 6 issuer: https://example.com/identity 7 mappingMethod: lookup 8 name: IAM type: OpenID- 1
- このプロバイダー名はアイデンティティー要求の値に接頭辞として付加され、アイデンティティー名が作成されます。プロバイダー名はリダイレクト URL の構築にも使用されます。
- 2
- メールアドレスとして使用する属性のリストを定義します。
- 3
- 表示名として使用する属性のリストを定義します。
- 4
- 優先ユーザー名として使用する属性のリストを定義します。
- 5
- OpenID プロバイダーに登録されたクライアントの ID を定義します。このクライアントを URL
https://oauth-openshift.apps.<cluster_name>.<cluster_domain>/oauth2callback/<idp_provider_name>にリダイレクトできるようにする必要があります。 - 6
- OpenID プロバイダーに登録されたクライアントのシークレットを定義します。
- 7
- OpenID の仕様で説明されている Issuer Identifier。クエリーまたはフラグメントコンポーネントのない
httpsを使用する必要があります。 - 8
- このプロバイダーのアイデンティティーと
Userオブジェクトの間でマッピングを確立する方法を制御するマッピング方法を定義します。
- Save をクリックします。
関連情報
- サポートされているアイデンティティープロバイダーの詳細は、認証および認可 の アイデンティティープロバイダー設定について を参照してください。
第4章 ホストされたクラスターでのフィーチャーゲートの使用
ホストされたクラスターでフィーチャーゲートを使用して、デフォルトの機能セットに含まれていない機能を有効にすることができます。ホストされたクラスターでフィーチャーゲートを使用すると、TechPreviewNoUpgrade 機能セットを有効にすることができます。
4.1. フィーチャーゲートを使用した機能セットの有効化
OpenShift CLI を使用して HostedCluster カスタムリソース (CR) を編集することにより、ホストされたクラスターで TechPreviewNoUpgrade 機能セットを有効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、ホスティングクラスターで
HostedClusterCR を編集するために開きます。$ oc edit <hosted_cluster_name> -n <hosted_cluster_namespace>
featureSetフィールドに値を入力して機能セットを定義します。以下に例を示します。apiVersion: hypershift.openshift.io/v1beta1 kind: HostedCluster metadata: name: <hosted_cluster_name> 1 namespace: <hosted_cluster_namespace> 2 spec: configuration: featureGate: featureSet: TechPreviewNoUpgrade 3
警告クラスターで
TechPreviewNoUpgrade機能セットを有効にすると、元に戻すことができず、マイナーバージョンの更新が妨げられます。この機能セットを使用すると、該当するテクノロジープレビュー機能をテストクラスターで有効にして、完全にテストすることができます。実稼働クラスターではこの機能セットを有効にしないでください。- 変更を適用するためにファイルを保存します。
検証
次のコマンドを実行して、ホストされたクラスターで
TechPreviewNoUpgradeフィーチャーゲートが有効になっていることを確認します。$ oc get featuregate cluster -o yaml
第5章 Hosted Control Plane の更新
Hosted Control Plane の更新には、ホストされたクラスターとノードプールの更新が含まれます。更新プロセス中にクラスターが完全に動作し続けるためには、コントロールプレーンとノードの更新を完了する際に、Kubernetes バージョンスキューポリシー の要件を満たす必要があります。
5.1. ホストされたクラスターの更新
spec.release 値は、コントロールプレーンのバージョンを決定します。HostedCluster オブジェクトは、意図した spec.release 値を HostedControlPlane.spec.release 値に送信し、適切なコントロールプレーン Operator バージョンを実行します。
Hosted Control Plane は、新しいバージョンの Cluster Version Operator (CVO) により、新しいバージョンのコントロールプレーンコンポーネントと OpenShift Container Platform コンポーネントのロールアウトを管理します。
5.2. ノードプールの更新
ノードプールを使用すると、spec.release および spec.config の値を公開することで、ノードで実行されているソフトウェアを設定できます。次の方法でノードプールのローリング更新を開始できます。
-
spec.releaseまたはspec.configの値を変更します。 - AWS インスタンスタイプなどのプラットフォーム固有のフィールドを変更します。結果は、新しいタイプの新規インスタンスのセットになります。
- クラスター設定を変更します (変更がノードに伝播される場合)。
ノードプールは、置換更新とインプレース更新をサポートします。nodepool.spec.release 値は、特定のノードプールのバージョンを決定します。NodePool オブジェクトは、.spec.management.upgradeType 値に従って、置換またはインプレースローリング更新を完了します。
ノードプールを作成した後は、更新タイプは変更できません。更新タイプを変更する場合は、ノードプールを作成し、他のノードプールを削除する必要があります。
5.2.1. ノードプールの置き換え更新
置き換え 更新では、以前のバージョンから古いインスタンスが削除され、新しいバージョンでインスタンスが作成されます。この更新タイプは、このレベルの不変性がコスト効率に優れているクラウド環境で効果的です。
置き換え更新では、ノードが完全に再プロビジョニングされるため、手動による変更は一切保持されません。
5.2.2. ノードプールのインプレース更新
インプレース 更新では、インスタンスのオペレーティングシステムが直接更新されます。このタイプは、ベアメタルなど、インフラストラクチャーの制約が高い環境に適しています。
インプレース更新では手動による変更を保存できますが、kubelet 証明書など、クラスターが直接管理するファイルシステムまたはオペレーティングシステムの設定に手動で変更を加えると、エラーが報告されます。
5.3. Hosted Control Plane のノードプールの更新
Hosted Control Plane では、ノードプールを更新して OpenShift Container Platform のバージョンを更新します。ノードプールのバージョンは、ホストされているコントロールプレーンのバージョンを超えないものとします。
手順
OpenShift Container Platform の新しいバージョンに更新するプロセスを開始するには、以下のコマンドを入力してノードプールの
spec.release.image値を変更します。$ oc -n <hosted_cluster_namespace> patch hostedcluster <hosted_cluster_name> --patch '{"spec":{"release":{"image": "<image_name>"}}}' --type=merge
検証
新しいバージョンがロールアウトされたことを確認するには、次のコマンドを実行して、
HostedClusterカスタムリソース (CR) の.status.version値と.status.conditions値を確認します。$ oc get hostedcluster <hosted_cluster_name> -o yaml
第6章 Hosted Control Plane の可観測性
メトリクスセットを設定することで、Hosted Control Plane のメトリクスを収集できます。HyperShift Operator は、管理対象のホストされたクラスターごとに、管理クラスター内のモニタリングダッシュボードを作成または削除できます。
6.1. Hosted Control Plane のメトリクスセットの設定
Red Hat OpenShift Container Platform の Hosted Control Plane は、各コントロールプレーンの namespace に ServiceMonitor リソースを作成します。これにより、Prometheus スタックがコントロールプレーンからメトリクスを収集できるようになります。ServiceMonitor リソースは、メトリクスの再ラベル付けを使用して、etcd や Kubernetes API サーバーなどの特定のコンポーネントにどのメトリクスを含めるか、または除外するかを定義します。コントロールプレーンによって生成されるメトリクスの数は、それらを収集する監視スタックのリソース要件に直接影響します。
すべての状況に適用される固定数のメトリクスを生成する代わりに、コントロールプレーンごとに生成するメトリクスのセットを識別するメトリクスセットを設定できます。次のメトリクスセットがサポートされています。
-
Telemetry: このメトリクスはテレメトリーに必要です。このセットはデフォルトのセットで、メトリックの最小セットです。 -
SRE: このセットには、アラートを生成し、コントロールプレーンコンポーネントのトラブルシューティングを可能にするために必要なメトリクスが含まれています。 -
All: このセットには、スタンドアロンの OpenShift Container Platform コントロールプレーンコンポーネントによって生成されるすべてのメトリクスが含まれます。
メトリクスセットを設定するには、次のコマンドを入力して、HyperShift Operator デプロイメントで METRICS_SET 環境変数を設定します。
$ oc set env -n hypershift deployment/operator METRICS_SET=All
6.1.1. SRE メトリックセットの設定
SRE メトリクスセットを指定すると、HyperShift Operator は、単一キー config を持つ sre-metric-set という名前の config map を検索します。config キーの値には、コントロールプレーンコンポーネントごとに編成された RelabelConfig のセットが含まれている必要があります。
次のコンポーネントを指定できます。
-
etcd -
kubeAPIServer -
kubeControllerManager -
openshiftAPIServer -
openshiftControllerManager -
openshiftRouteControllerManager -
cvo -
olm -
catalogOperator -
registryOperator -
nodeTuningOperator -
controlPlaneOperator -
hostedClusterConfigOperator
SRE メトリクスセットの設定を次の例に示します。
kubeAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "scheduler_(e2e_scheduling_latency_microseconds|scheduling_algorithm_predicate_evaluation|scheduling_algorithm_priority_evaluation|scheduling_algorithm_preemption_evaluation|scheduling_algorithm_latency_microseconds|binding_latency_microseconds|scheduling_latency_seconds)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_(request_count|request_latencies|request_latencies_summary|dropped_requests|storage_data_key_generation_latencies_microseconds|storage_transformation_failures_total|storage_transformation_latencies_microseconds|proxy_tunnel_sync_latency_secs)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "docker_(operations|operations_latency_microseconds|operations_errors|operations_timeout)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "reflector_(items_per_list|items_per_watch|list_duration_seconds|lists_total|short_watches_total|watch_duration_seconds|watches_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "etcd_(helper_cache_hit_count|helper_cache_miss_count|helper_cache_entry_count|request_cache_get_latencies_summary|request_cache_add_latencies_summary|request_latencies_summary)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "transformation_(transformation_latencies_microseconds|failures_total)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "network_plugin_operations_latency_microseconds|sync_proxy_rules_latency_microseconds|rest_client_request_latency_seconds"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
kubeControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "rest_client_request_latency_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
- action: "drop"
regex: "root_ca_cert_publisher_sync_duration_seconds_(bucket|count|sum)"
sourceLabels: ["__name__"]
openshiftAPIServer:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_controller_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_admission_step_admission_latencies_seconds_.*"
sourceLabels: ["__name__"]
- action: "drop"
regex: "apiserver_request_duration_seconds_bucket;(0.15|0.25|0.3|0.35|0.4|0.45|0.6|0.7|0.8|0.9|1.25|1.5|1.75|2.5|3|3.5|4.5|6|7|8|9|15|25|30|50)"
sourceLabels: ["__name__", "le"]
openshiftControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
openshiftRouteControllerManager:
- action: "drop"
regex: "etcd_(debugging|disk|request|server).*"
sourceLabels: ["__name__"]
olm:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
catalogOperator:
- action: "drop"
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]
cvo:
- action: drop
regex: "etcd_(debugging|disk|server).*"
sourceLabels: ["__name__"]6.2. ホストされたクラスターのモニタリングダッシュボードの有効化
ホストされたクラスターのモニタリングダッシュボードを有効にするには、次の手順を実行します。
手順
local-clusternamespace にhypershift-operator-install-flagsconfig map を作成します。data.installFlagsToAddセクションで--monitoring-dashboardsフラグを必ず指定してください。以下に例を示します。kind: ConfigMap apiVersion: v1 metadata: name: hypershift-operator-install-flags namespace: local-cluster data: installFlagsToAdd: "--monitoring-dashboards" installFlagsToRemove: ""
hypershiftnamespace の HyperShift Operator デプロイメントが更新され、次の環境変数が含まれるまで数分待ちます。- name: MONITORING_DASHBOARDS value: "1"モニタリングダッシュボードが有効になっている場合、HyperShift Operator が管理するホストされたクラスターごとに、HyperShift Operator が
openshift-config-managednamespace にcp-<hosted_cluster_namespace>-<hosted_cluster_name>という名前の config map を作成します。<hosted_cluster_namespace>はホストされたクラスターの namespace、<hosted_cluster_name>はホストされたクラスターの名前です。その結果、管理クラスターの管理コンソールに新しいダッシュボードが追加されます。- ダッシュボードを表示するには、管理クラスターのコンソールにログインし、Observe → Dashboards をクリックして、ホストされたクラスターのダッシュボードに移動します。
-
オプション: ホストされたクラスターのモニタリングダッシュボードを無効にするには、
hypershift-operator-install-flagsconfig map から--monitoring-dashboardsフラグを削除します。ホストされたクラスターを削除すると、対応するダッシュボードも削除されます。
6.2.1. ダッシュボードのカスタマイズ
各ホストされたクラスターのダッシュボードを生成するために、HyperShift Operator は、Operator の namespace (hypershift) の monitoring-dashboard-template config map に保存されているテンプレートを使用します。このテンプレートには、ダッシュボードのメトリクスを含む一連の Grafana パネルが含まれています。config map の内容を編集して、ダッシュボードをカスタマイズできます。
ダッシュボードが生成されると、次の文字列が特定のホストされたクラスターに対応する値に置き換えられます。
| 名前 | 説明 |
|
| ホストされたクラスターの名前 |
|
| ホストされたクラスターの名前空間 |
|
| ホストされたクラスターのコントロールプレーン Pod が配置される namespace |
|
|
ホストされたクラスターの UUID。ホストされたクラスターのメトリクスの |
第7章 Hosted control plane のバックアップ、復元、障害復旧
ホストされたクラスターで etcd をバックアップおよび復元する必要がある場合、またはホストされたクラスターの障害復旧を行う必要がある場合は、次の手順を確認してください。
7.1. ホストされたクラスターの etcd Pod の回復
ホストされたクラスターでは、etcd Pod はステートフルセットの一部として実行されます。ステートフルセットは、永続ストレージに依存して各メンバーの etcd データを保存します。高可用性コントロールプレーンでは、ステートフルセットのサイズは 3 Pod で、各メンバーには独自の永続ボリューム要求があります。
7.1.1. ホストされたクラスターのステータスの確認
ホストされたクラスターのステータスを確認するには、次の手順を実行します。
手順
次のコマンドを入力して、確認する実行中の etcd Pod を入力します。
$ oc rsh -n <control_plane_namespace> -c etcd <etcd_pod_name>
次のコマンドを入力して、etcdctl 環境をセットアップします。
sh-4.4$ export ETCDCTL_API=3
sh-4.4$ export ETCDCTL_CACERT=/etc/etcd/tls/etcd-ca/ca.crt
sh-4.4$ export ETCDCTL_CERT=/etc/etcd/tls/client/etcd-client.crt
sh-4.4$ export ETCDCTL_KEY=/etc/etcd/tls/client/etcd-client.key
sh-4.4$ export ETCDCTL_ENDPOINTS=https://etcd-client:2379
次のコマンドを入力して、各クラスターメンバーのエンドポイントステータスを出力します。
sh-4.4$ etcdctl endpoint health --cluster -w table
7.1.2. ホストされたクラスターの etcd メンバーの回復
3 ノードクラスターの etcd メンバーは、データの破損または欠落が原因で失敗する可能性があります。etcd メンバーを回復するには、次の手順を実行します。
手順
etcd メンバーが失敗していることを確認する必要がある場合は、次のコマンドを入力します。
$ oc get pods -l app=etcd -n <control_plane_namespace>
etcd メンバーが失敗している場合、出力は次の例のようになります。
出力例
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 64m etcd-1 2/2 Running 0 45m etcd-2 1/2 CrashLoopBackOff 1 (5s ago) 64m
次のコマンドを入力して、障害が発生した etcd メンバーと Pod の永続ボリューム要求を削除します。
$ oc delete pvc/<pvc_name> pod/<etcd_pod_name> --wait=false
Pod が再起動したら、次のコマンドを入力して、etcd メンバーが etcd クラスターに追加されて正しく機能していることを確認します。
$ oc get pods -l app=etcd -n <control_plane_namespace>
出力例
NAME READY STATUS RESTARTS AGE etcd-0 2/2 Running 0 67m etcd-1 2/2 Running 0 48m etcd-2 2/2 Running 0 2m2s
7.2. AWS 上ホストされたクラスターで etcd のバックアップと復元を行う
OpenShift Container Platform の Hosted Control Plane を使用する場合、etcd をバックアップおよび復元するプロセスが 通常の etcd バックアッププロセス と異なります。
以下の手順は、AWS 上の Hosted Control Plane に固有のものです。
AWS プラットフォーム上の Hosted Control Plane は、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
7.2.1. ホストされたクラスターでの etcd のスナップショットの作成
ホストされたクラスターの etcd をバックアップするプロセスの一環として、etcd のスナップショットを作成します。スナップショットを作成した後、たとえば障害復旧操作の一部として復元できます。
この手順には、API のダウンタイムが必要です。
手順
このコマンドを入力して、ホストされたクラスターの調整を一時停止します。
$ oc patch -n clusters hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"true"}}' --type=mergeこのコマンドを入力して、すべての etcd-writer デプロイメントを停止します。
$ oc scale deployment -n <hosted_cluster_namespace> --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver
etcd スナップショットを取得するには、次のコマンドを実行して、各 etcd コンテナーで
execコマンドを使用します。$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db
スナップショットのステータスを確認するには、次のコマンドを実行して、各 etcd コンテナーで
execコマンドを使用します。$ oc exec -it <etcd_pod_name> -n <hosted_cluster_namespace> -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db
次の例に示すように、S3 バケットなど、後で取得できる場所にスナップショットデータをコピーします。
注記次の例では、署名バージョン 2 を使用しています。署名バージョン 4 をサポートするリージョン (例: us-east-2 リージョン) にいる場合は、署名バージョン 4 を使用してください。それ以外の場合は、署名バージョン 2 を使用してスナップショットを S3 バケットにコピーすると、アップロードは失敗し、署名バージョン 2 は非推奨になります。
例
BUCKET_NAME=somebucket FILEPATH="/${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" ACCESS_KEY=accesskey SECRET_KEY=secret SIGNATURE_HASH=`echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac ${SECRET_KEY} -binary | base64` oc exec -it etcd-0 -n ${HOSTED_CLUSTER_NAMESPACE} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${CLUSTER_NAME}-snapshot.db後で新しいクラスターでスナップショットを復元できるようにする場合は、この例に示すように、ホストされたクラスターが参照する暗号化シークレットを保存します。
例
oc get hostedcluster $CLUSTER_NAME -o=jsonpath='{.spec.secretEncryption.aescbc}' {"activeKey":{"name":"CLUSTER_NAME-etcd-encryption-key"}} # Save this secret, or the key it contains so the etcd data can later be decrypted oc get secret ${CLUSTER_NAME}-etcd-encryption-key -o=jsonpath='{.data.key}'
次のステップ
etcd スナップショットを復元します。
7.2.2. ホストされたクラスターでの etcd スナップショットの復元
ホストされたクラスターからの etcd のスナップショットがある場合は、それを復元できます。現在、クラスターの作成中にのみ etcd スナップショットを復元できます。
etcd スナップショットを復元するには、create cluster --render コマンドからの出力を変更し、HostedCluster 仕様の etcd セクションで restoreSnapshotURL 値を定義します。
前提条件
ホストされたクラスターで etcd スナップショットを作成している。
手順
awsコマンドラインインターフェイス (CLI) で事前に署名された URL を作成し、認証情報を etcd デプロイメントに渡さずに S3 から etcd スナップショットをダウンロードできるようにします。ETCD_SNAPSHOT=${ETCD_SNAPSHOT:-"s3://${BUCKET_NAME}/${CLUSTER_NAME}-snapshot.db"} ETCD_SNAPSHOT_URL=$(aws s3 presign ${ETCD_SNAPSHOT})次の URL を参照するように
HostedCluster仕様を変更します。spec: etcd: managed: storage: persistentVolume: size: 4Gi type: PersistentVolume restoreSnapshotURL: - "${ETCD_SNAPSHOT_URL}" managementType: Managed-
spec.secretEncryption.aescbc値から参照したシークレットに、前の手順で保存したものと同じ AES キーが含まれていることを確認します。
7.3. オンプレミス環境のホストされたクラスターでの etcd のバックアップと復元
ホストされたクラスターで etcd をバックアップおよび復元することで、3 ノードクラスターの etcd メンバー内にあるデータの破損や欠落などの障害を修正できます。etcd クラスターの複数メンバーでデータの損失や CrashLoopBackOff ステータスが発生する場合、このアプローチにより etcd クォーラムの損失を防ぐことができます。
この手順には、API のダウンタイムが必要です。
前提条件
-
ocおよびjqバイナリーがインストールされている。
手順
まず環境変数を設定し、API サーバーをスケールダウンします。
必要に応じて値を置き換えて次のコマンドを入力し、ホストされたクラスターの環境変数を設定します。
$ CLUSTER_NAME=my-cluster
$ HOSTED_CLUSTER_NAMESPACE=clusters
$ CONTROL_PLANE_NAMESPACE="${HOSTED_CLUSTER_NAMESPACE}-${CLUSTER_NAME}"必要に応じて値を置き換えて次のコマンドを入力し、ホストされたクラスターの調整を一時停止します。
$ oc patch -n ${HOSTED_CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":"true"}}' --type=merge次のコマンドを入力して、API サーバーをスケールダウンします。
kube-apiserverをスケールダウンします。$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/kube-apiserver --replicas=0openshift-apiserverをスケールダウンします。$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/openshift-apiserver --replicas=0openshift-oauth-apiserverをスケールダウンします。$ oc scale -n ${CONTROL_PLANE_NAMESPACE} deployment/openshift-oauth-apiserver --replicas=0
次に、次のいずれかの方法を使用して etcd のスナップショットを取得します。
- 以前にバックアップした etcd のスナップショットを使用します。
使用可能な etcd Pod がある場合は、次の手順を実行して、アクティブな etcd Pod からスナップショットを取得します。
次のコマンドを入力して、etcd Pod をリスト表示します。
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd次のコマンドを入力して、Pod データベースのスナップショットを取得し、マシンのローカルに保存します。
$ ETCD_POD=etcd-0
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- env ETCDCTL_API=3 /usr/bin/etcdctl \ --cacert /etc/etcd/tls/etcd-ca/ca.crt \ --cert /etc/etcd/tls/client/etcd-client.crt \ --key /etc/etcd/tls/client/etcd-client.key \ --endpoints=https://localhost:2379 \ snapshot save /var/lib/snapshot.db次のコマンドを入力して、スナップショットが成功したことを確認します。
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} -c etcd -t ${ETCD_POD} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/snapshot.db
次のコマンドを入力して、スナップショットのローカルコピーを作成します。
$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/snapshot.db /tmp/etcd.snapshot.dbetcd 永続ストレージからスナップショットデータベースのコピーを作成します。
次のコマンドを入力して、etcd Pod をリスト表示します。
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd実行中の Pod を検索し、その名前を
ETCD_POD: ETCD_POD=etcd-0の値として設定し、次のコマンドを入力してそのスナップショットデータベースをコピーします。$ oc cp -c etcd ${CONTROL_PLANE_NAMESPACE}/${ETCD_POD}:/var/lib/data/member/snap/db /tmp/etcd.snapshot.db
次のコマンドを入力して、etcd statefulset をスケールダウンします。
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=0次のコマンドを入力して、2 番目と 3 番目のメンバーのボリュームを削除します。
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} pvc/data-etcd-1 pvc/data-etcd-2最初の etcd メンバーのデータにアクセスする Pod を作成します。
次のコマンドを入力して、etcd イメージを取得します。
$ ETCD_IMAGE=$(oc get -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd -o jsonpath='{ .spec.template.spec.containers[0].image }')etcd データへのアクセスを許可する Pod を作成します。
$ cat << EOF | oc apply -n ${CONTROL_PLANE_NAMESPACE} -f - apiVersion: apps/v1 kind: Deployment metadata: name: etcd-data spec: replicas: 1 selector: matchLabels: app: etcd-data template: metadata: labels: app: etcd-data spec: containers: - name: access image: $ETCD_IMAGE volumeMounts: - name: data mountPath: /var/lib command: - /usr/bin/bash args: - -c - |- while true; do sleep 1000 done volumes: - name: data persistentVolumeClaim: claimName: data-etcd-0 EOF次のコマンドを入力して、
etcd-dataPod のステータスを確認し、実行されるまで待ちます。$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd-data次のコマンドを入力して、
etcd-dataPod の名前を取得します。$ DATA_POD=$(oc get -n ${CONTROL_PLANE_NAMESPACE} pods --no-headers -l app=etcd-data -o name | cut -d/ -f2)
次のコマンドを入力して、etcd スナップショットを Pod にコピーします。
$ oc cp /tmp/etcd.snapshot.db ${CONTROL_PLANE_NAMESPACE}/${DATA_POD}:/var/lib/restored.snap.db次のコマンドを入力して、
etcd-dataPod から古いデータを削除します。$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm -rf /var/lib/data$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- mkdir -p /var/lib/data次のコマンドを入力して、etcd スナップショットを復元します。
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- etcdutl snapshot restore /var/lib/restored.snap.db \ --data-dir=/var/lib/data --skip-hash-check \ --name etcd-0 \ --initial-cluster-token=etcd-cluster \ --initial-cluster etcd-0=https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-1=https://etcd-1.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380,etcd-2=https://etcd-2.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380 \ --initial-advertise-peer-urls https://etcd-0.etcd-discovery.${CONTROL_PLANE_NAMESPACE}.svc:2380次のコマンドを入力して、Pod から一時的な etcd スナップショットを削除します。
$ oc exec -n ${CONTROL_PLANE_NAMESPACE} ${DATA_POD} -- rm /var/lib/restored.snap.db次のコマンドを入力して、データアクセスデプロイメントを削除します。
$ oc delete -n ${CONTROL_PLANE_NAMESPACE} deployment/etcd-data次のコマンドを入力して、etcd クラスターをスケールアップします。
$ oc scale -n ${CONTROL_PLANE_NAMESPACE} statefulset/etcd --replicas=3次のコマンドを入力して、etcd メンバー Pod が返され、使用可能であると報告されるのを待ちます。
$ oc get -n ${CONTROL_PLANE_NAMESPACE} pods -l app=etcd -w次のコマンドを入力して、すべての etcd-writer デプロイメントをスケールアップします。
$ oc scale deployment -n ${CONTROL_PLANE_NAMESPACE} --replicas=3 kube-apiserver openshift-apiserver openshift-oauth-apiserver
次のコマンドを入力して、ホストされたクラスターの調整を復元します。
$ oc patch -n ${CLUSTER_NAMESPACE} hostedclusters/${CLUSTER_NAME} -p '{"spec":{"pausedUntil":""}}' --type=merge
7.4. AWS リージョン内のホストされたクラスターの障害復旧
ホストされたクラスターの障害復旧 (DR) が必要な状況では、ホストされたクラスターを AWS 内の同じリージョンに回復できます。たとえば、管理クラスターのアップグレードが失敗し、ホストされているクラスターが読み取り専用状態になっている場合、DR が必要です。
Hosted Control Plane は、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビューの機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
DR プロセスには、次の 3 つの主要な手順が含まれます。
- ソース管理クラスターでのホストされたクラスターのバックアップ
- 宛先管理クラスターでのホストされたクラスターの復元
- ホストされたクラスターのソース管理クラスターからの削除
プロセス中、ワークロードは引き続き実行されます。クラスター API は一定期間使用できない場合がありますが、ワーカーノードで実行されているサービスには影響しません。
次の例に示すように、ソース管理クラスターと宛先管理クラスターの両方に --external-dns フラグを設定して、API サーバー URL を維持する必要があります。
例: 外部 DNS フラグ
--external-dns-provider=aws \ --external-dns-credentials=<AWS Credentials location> \ --external-dns-domain-filter=<DNS Base Domain>
これにより、サーバー URL は https://api-sample-hosted.sample-hosted.aws.openshift.com で終わります。
API サーバー URL を維持するために --external-dns フラグを含めない場合、ホストされたクラスターを移行することはできません。
7.4.1. 環境とコンテキストの例
復元するクラスターが 3 つあるシナリオを考えてみます。2 つは管理クラスターで、1 つはホストされたクラスターです。コントロールプレーンのみ、またはコントロールプレーンとノードのいずれかを復元できます。開始する前に、以下の情報が必要です。
- ソース MGMT namespace: ソース管理 namespace
- ソース MGMT ClusterName: ソース管理クラスター名
-
ソース MGMT Kubeconfig: ソース管理
kubeconfigファイル -
宛先 MGMT Kubeconfig: 宛先管理
kubeconfigファイル -
HC Kubeconfig: ホストされたクラスターの
kubeconfigファイル - SSH 鍵ファイル: SSH 公開鍵
- プルシークレット: リリースイメージにアクセスするためのプルシークレットファイル
- AWS 認証情報
- AWS リージョン
- ベースドメイン: 外部 DNS として使用する DNS ベースドメイン
- S3 バケット名: etcd バックアップをアップロードする予定の AWS リージョンのバケット
この情報は、次の環境変数の例に示されています。
環境変数の例
SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub
BASE_PATH=${HOME}/hypershift
BASE_DOMAIN="aws.sample.com"
PULL_SECRET_FILE="${HOME}/pull_secret.json"
AWS_CREDS="${HOME}/.aws/credentials"
AWS_ZONE_ID="Z02718293M33QHDEQBROL"
CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica
HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift
HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift
HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"}
NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2}
# MGMT Context
MGMT_REGION=us-west-1
MGMT_CLUSTER_NAME="${USER}-dev"
MGMT_CLUSTER_NS=${USER}
MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}"
MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig"
# MGMT2 Context
MGMT2_CLUSTER_NAME="${USER}-dest"
MGMT2_CLUSTER_NS=${USER}
MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}"
MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig"
# Hosted Cluster Context
HC_CLUSTER_NS=clusters
HC_REGION=us-west-1
HC_CLUSTER_NAME="${USER}-hosted"
HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}"
HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig"
BACKUP_DIR=${HC_CLUSTER_DIR}/backup
BUCKET_NAME="${USER}-hosted-${MGMT_REGION}"
# DNS
AWS_ZONE_ID="Z07342811SH9AA102K1AC"
EXTERNAL_DNS_DOMAIN="hc.jpdv.aws.kerbeross.com"
7.4.2. バックアップおよび復元プロセスの概要
バックアップと復元のプロセスは、以下のような仕組みとなっています。
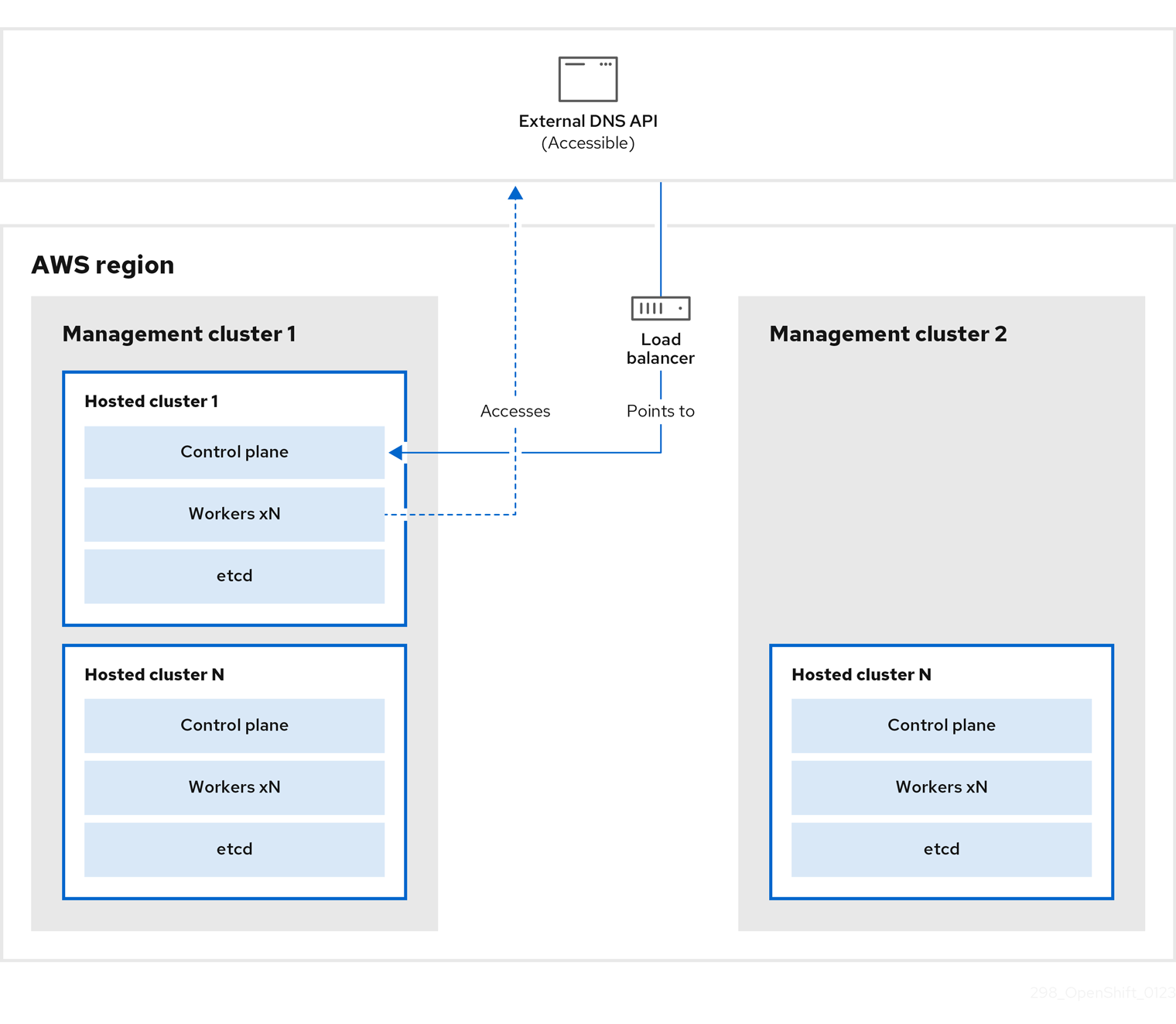
管理クラスター 1 (ソース管理クラスターと見なすことができます) では、コントロールプレーンとワーカーが 外部 DNS API を使用して対話します。外部 DNS API はアクセス可能で、管理クラスター間にロードバランサーが配置されています。
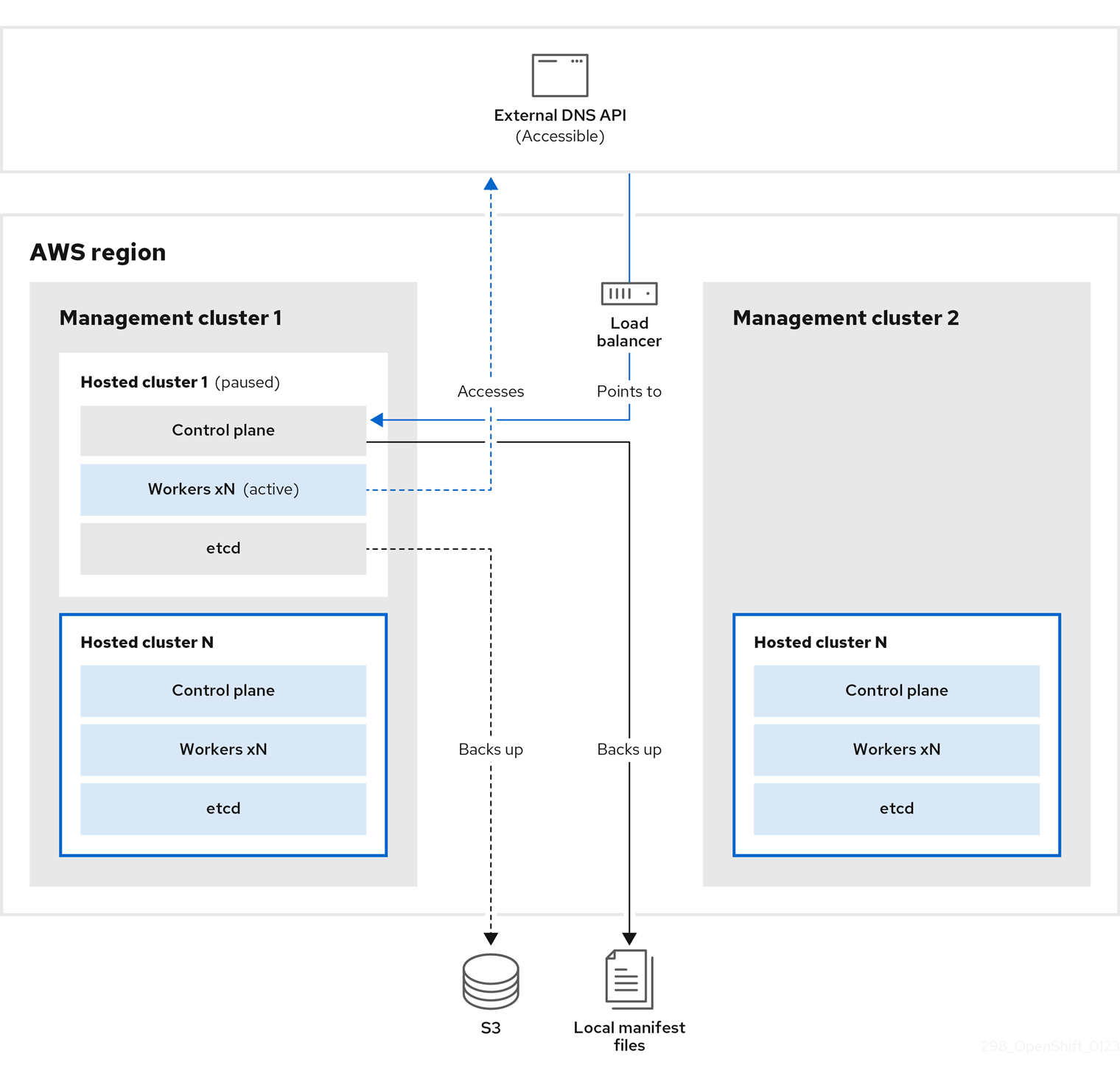
ホストされたクラスターのスナップショットを作成します。これには、etcd、コントロールプレーン、およびワーカーノードが含まれます。このプロセスの間、ワーカーノードは外部 DNS API にアクセスできなくても引き続きアクセスを試みます。また、ワークロードが実行され、コントロールプレーンがローカルマニフェストファイルに保存され、etcd が S3 バケットにバックアップされます。データプレーンはアクティブで、コントロールプレーンは一時停止しています。
管理クラスター 2 (宛先管理クラスターと見なすことができます) では、S3 バケットから etcd を復元し、ローカルマニフェストファイルからコントロールプレーンを復元します。このプロセスの間、外部 DNS API は停止し、ホストされたクラスター API にアクセスできなくなり、API を使用するワーカーはマニフェストファイルを更新できなくなりますが、ワークロードは引き続き実行されます。
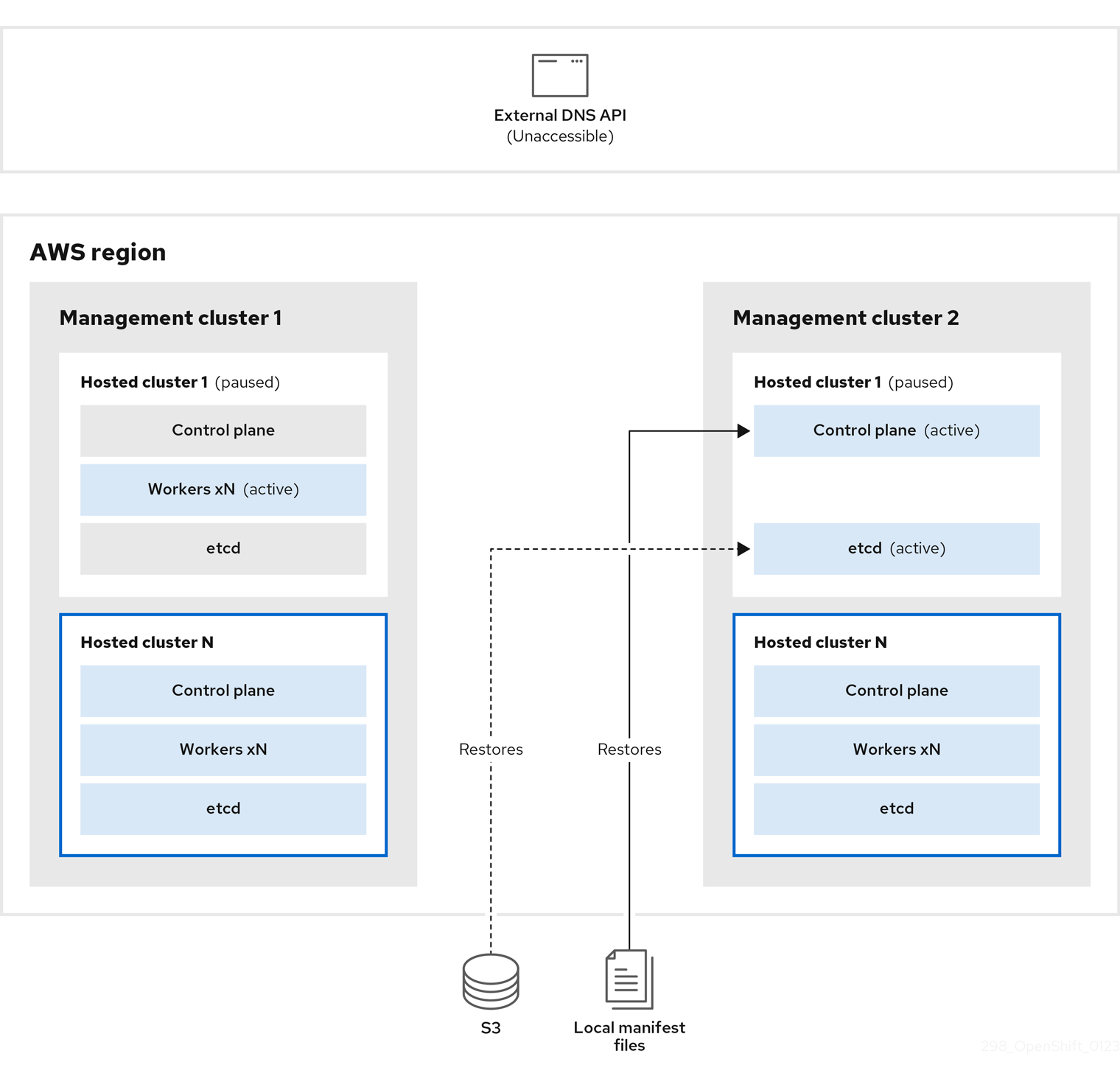
外部 DNS API に再びアクセスできるようになり、ワーカーノードはそれを使用して管理クラスター 2 に移動します。外部 DNS API は、コントロールプレーンを参照するロードバランサーにアクセスできます。
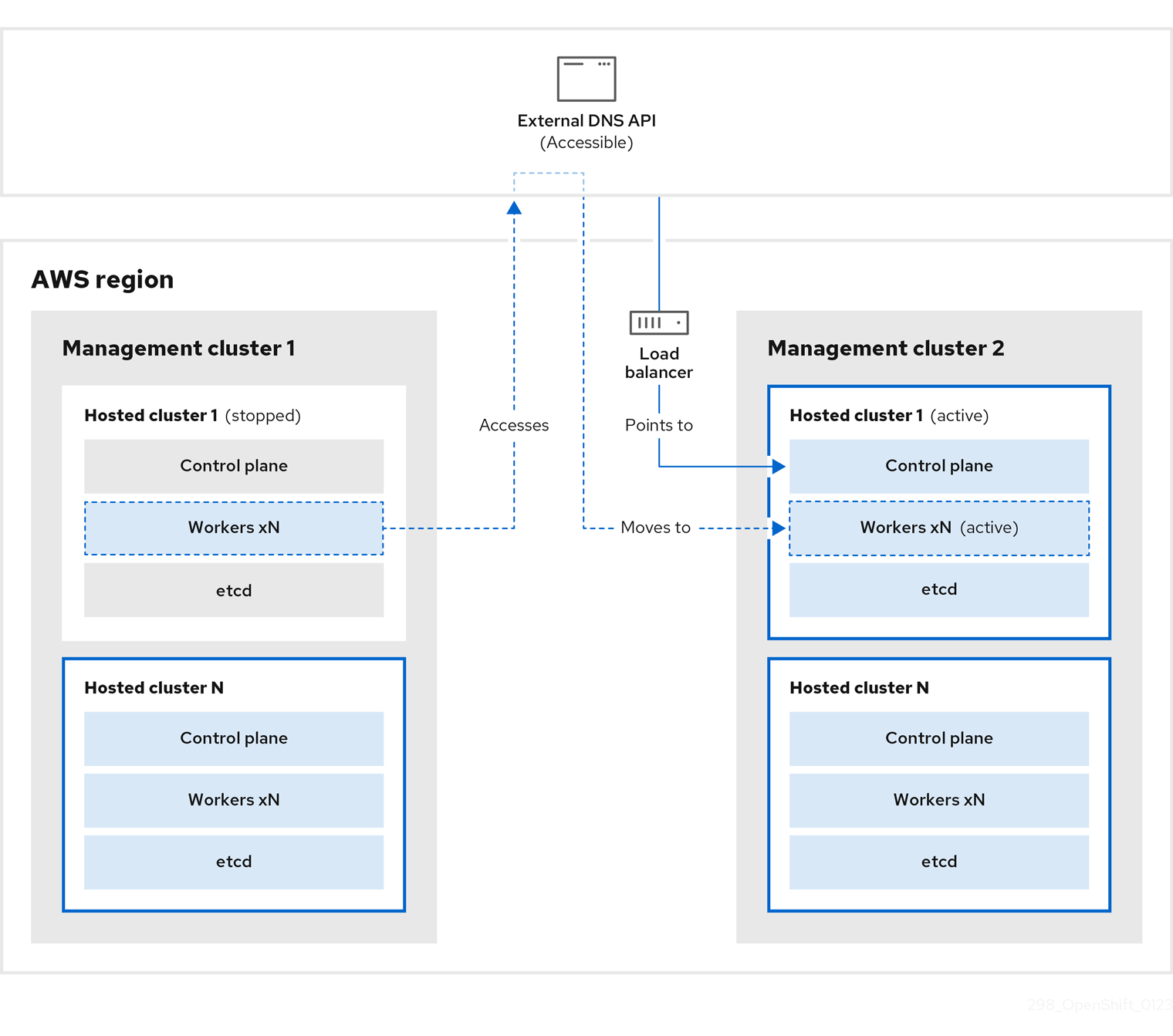
管理クラスター 2 では、コントロールプレーンとワーカーノードが外部 DNS API を使用して対話します。リソースは、etcd の S3 バックアップを除いて、管理クラスター 1 から削除されます。ホストされたクラスターを管理クラスター 1 で再度設定しようとしても、機能しません。
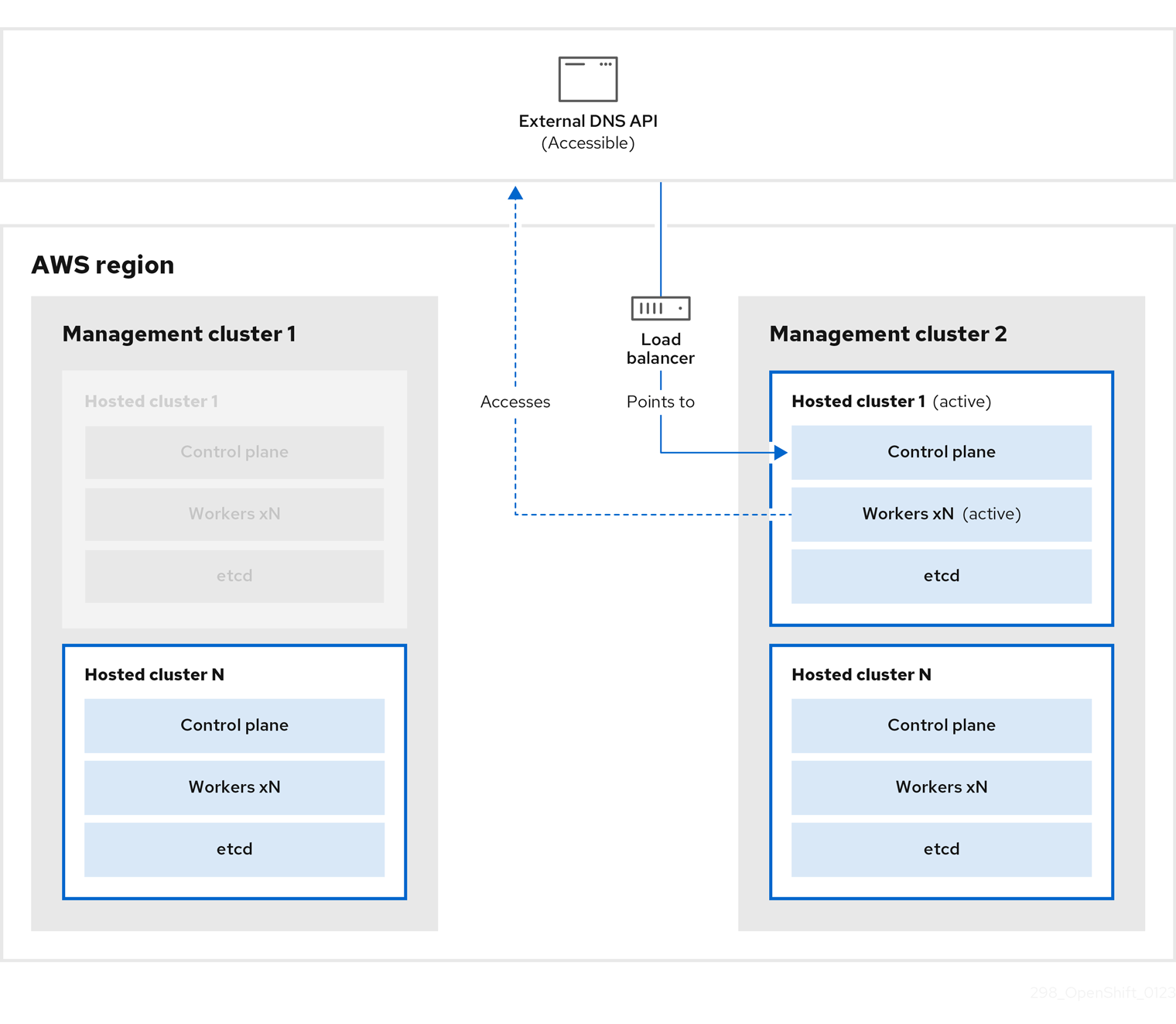
ホストされたクラスターを手動でバックアップおよび復元するか、スクリプトを実行してプロセスを完了することができます。スクリプトの詳細については、「ホストされたクラスターをバックアップおよび復元するためのスクリプトの実行」を参照してください。
7.4.3. ホストされたクラスターのバックアップ
ターゲット管理クラスターでホストされたクラスターを復元するには、最初にすべての関連データをバックアップする必要があります。
手順
以下のコマンドを入力して、configmap ファイルを作成し、ソース管理クラスターを宣言します。
$ oc create configmap mgmt-parent-cluster -n default --from-literal=from=${MGMT_CLUSTER_NAME}以下のコマンドを入力して、ホストされたクラスターとノードプールの調整をシャットダウンします。
PAUSED_UNTIL="true" oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operatorPAUSED_UNTIL="true" oc patch -n ${HC_CLUSTER_NS} hostedclusters/${HC_CLUSTER_NAME} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge oc patch -n ${HC_CLUSTER_NS} nodepools/${NODEPOOLS} -p '{"spec":{"pausedUntil":"'${PAUSED_UNTIL}'"}}' --type=merge oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 kube-apiserver openshift-apiserver openshift-oauth-apiserver control-plane-operator以下の bash スクリプトを実行して、etcd をバックアップし、データを S3 バケットにアップロードします。
ヒントこのスクリプトを関数でラップし、メイン関数から呼び出します。
# ETCD Backup ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi for POD in ${ETCD_PODS}; do # Create an etcd snapshot oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl --cacert /etc/etcd/tls/client/etcd-client-ca.crt --cert /etc/etcd/tls/client/etcd-client.crt --key /etc/etcd/tls/client/etcd-client.key --endpoints=localhost:2379 snapshot save /var/lib/data/snapshot.db oc exec -it ${POD} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- env ETCDCTL_API=3 /usr/bin/etcdctl -w table snapshot status /var/lib/data/snapshot.db FILEPATH="/${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" CONTENT_TYPE="application/x-compressed-tar" DATE_VALUE=`date -R` SIGNATURE_STRING="PUT\n\n${CONTENT_TYPE}\n${DATE_VALUE}\n${FILEPATH}" set +x ACCESS_KEY=$(grep aws_access_key_id ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SECRET_KEY=$(grep aws_secret_access_key ${AWS_CREDS} | head -n1 | cut -d= -f2 | sed "s/ //g") SIGNATURE_HASH=$(echo -en ${SIGNATURE_STRING} | openssl sha1 -hmac "${SECRET_KEY}" -binary | base64) set -x # FIXME: this is pushing to the OIDC bucket oc exec -it etcd-0 -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -- curl -X PUT -T "/var/lib/data/snapshot.db" \ -H "Host: ${BUCKET_NAME}.s3.amazonaws.com" \ -H "Date: ${DATE_VALUE}" \ -H "Content-Type: ${CONTENT_TYPE}" \ -H "Authorization: AWS ${ACCESS_KEY}:${SIGNATURE_HASH}" \ https://${BUCKET_NAME}.s3.amazonaws.com/${HC_CLUSTER_NAME}-${POD}-snapshot.db doneetcd のバックアップの詳細については、「ホストされたクラスターでの etcd のバックアップと復元」を参照してください。
以下のコマンドを入力して、Kubernetes および OpenShift Container Platform オブジェクトをバックアップします。次のオブジェクトをバックアップする必要があります。
-
HostedCluster namespace の
HostedClusterおよびNodePoolオブジェクト -
HostedCluster namespace の
HostedClusterシークレット -
Hosted Control Plane namespace の
HostedControlPlane -
Hosted Control Plane namespace の
Cluster -
Hosted Control Plane namespace の
AWSCluster、AWSMachineTemplate、およびAWSMachine -
Hosted Control Plane namespace の
MachineDeployments、MachineSets、およびMachines Hosted Control Plane namespace の
ControlPlaneシークレットmkdir -p ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS} ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} chmod 700 ${BACKUP_DIR}/namespaces/ # HostedCluster echo "Backing Up HostedCluster Objects:" oc get hc ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml echo "--> HostedCluster" sed -i '' -e '/^status:$/,$d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml # NodePool oc get np ${NODEPOOLS} -n ${HC_CLUSTER_NS} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml echo "--> NodePool" sed -i '' -e '/^status:$/,$ d' ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-${NODEPOOLS}.yaml # Secrets in the HC Namespace echo "--> HostedCluster Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS} | grep "^${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-${s}.yaml done # Secrets in the HC Control Plane Namespace echo "--> HostedCluster ControlPlane Secrets:" for s in $(oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} | egrep -v "docker|service-account-token|oauth-openshift|NAME|token-${HC_CLUSTER_NAME}" | awk '{print $1}'); do oc get secret -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-${s}.yaml done # Hosted Control Plane echo "--> HostedControlPlane:" oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-${HC_CLUSTER_NAME}.yaml # Cluster echo "--> Cluster:" CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) oc get cluster ${CL_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-${HC_CLUSTER_NAME}.yaml # AWS Cluster echo "--> AWS Cluster:" oc get awscluster ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-${HC_CLUSTER_NAME}.yaml # AWS MachineTemplate echo "--> AWS Machine Template:" oc get awsmachinetemplate ${NODEPOOLS} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-${HC_CLUSTER_NAME}.yaml # AWS Machines echo "--> AWS Machine:" CL_NAME=$(oc get hcp ${HC_CLUSTER_NAME} -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o jsonpath={.metadata.labels.\*} | grep ${HC_CLUSTER_NAME}) for s in $(oc get awsmachines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --no-headers | grep ${CL_NAME} | cut -f1 -d\ ); do oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} awsmachines $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-${s}.yaml done # MachineDeployments echo "--> HostedCluster MachineDeployments:" for s in $(oc get machinedeployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do mdp_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-${mdp_name}.yaml done # MachineSets echo "--> HostedCluster MachineSets:" for s in $(oc get machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do ms_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-${ms_name}.yaml done # Machines echo "--> HostedCluster Machine:" for s in $(oc get machine -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do m_name=$(echo ${s} | cut -f 2 -d /) oc get -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} $s -o yaml > ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-${m_name}.yaml done
-
HostedCluster namespace の
次のコマンドを入力して、
ControlPlaneルートをクリーンアップします。$ oc delete routes -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --allこのコマンドを入力すると、ExternalDNS Operator が Route53 エントリーを削除できるようになります。
次のスクリプトを実行して、Route53 エントリーがクリーンであることを確認します。
function clean_routes() { if [[ -z "${1}" ]];then echo "Give me the NS where to clean the routes" exit 1 fi # Constants if [[ -z "${2}" ]];then echo "Give me the Route53 zone ID" exit 1 fi ZONE_ID=${2} ROUTES=10 timeout=40 count=0 # This allows us to remove the ownership in the AWS for the API route oc delete route -n ${1} --all while [ ${ROUTES} -gt 2 ] do echo "Waiting for ExternalDNS Operator to clean the DNS Records in AWS Route53 where the zone id is: ${ZONE_ID}..." echo "Try: (${count}/${timeout})" sleep 10 if [[ $count -eq timeout ]];then echo "Timeout waiting for cleaning the Route53 DNS records" exit 1 fi count=$((count+1)) ROUTES=$(aws route53 list-resource-record-sets --hosted-zone-id ${ZONE_ID} --max-items 10000 --output json | grep -c ${EXTERNAL_DNS_DOMAIN}) done } # SAMPLE: clean_routes "<HC ControlPlane Namespace>" "<AWS_ZONE_ID>" clean_routes "${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" "${AWS_ZONE_ID}"
検証
すべての OpenShift Container Platform オブジェクトと S3 バケットをチェックし、すべてが想定どおりであることを確認します。
次のステップ
ホストされたクラスターを復元します。
7.4.4. ホストされたクラスターの復元
バックアップしたすべてのオブジェクトを収集し、宛先管理クラスターに復元します。
前提条件
ソース管理クラスターからデータをバックアップしている。
宛先管理クラスターの kubeconfig ファイルが、KUBECONFIG 変数に設定されているとおりに、あるいは、スクリプトを使用する場合は MGMT2_KUBECONFIG 変数に設定されているとおりに配置されていることを確認します。export KUBECONFIG=<Kubeconfig FilePath> を使用するか、スクリプトを使用する場合は export KUBECONFIG=${MGMT2_KUBECONFIG} を使用します。
手順
以下のコマンドを入力して、新しい管理クラスターに、復元するクラスターの namespace が含まれていないことを確認します。
# Just in case export KUBECONFIG=${MGMT2_KUBECONFIG} BACKUP_DIR=${HC_CLUSTER_DIR}/backup # Namespace deletion in the destination Management cluster $ oc delete ns ${HC_CLUSTER_NS} || true $ oc delete ns ${HC_CLUSTER_NS}-{HC_CLUSTER_NAME} || true以下のコマンドを入力して、削除された namespace を再作成します。
# Namespace creation $ oc new-project ${HC_CLUSTER_NS} $ oc new-project ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}次のコマンドを入力して、HC namespace のシークレットを復元します。
$ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/secret-*以下のコマンドを入力して、
HostedClusterコントロールプレーン namespace のオブジェクトを復元します。# Secrets $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/secret-* # Cluster $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/hcp-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/cl-*ノードとノードプールを復元して AWS インスタンスを再利用する場合は、次のコマンドを入力して、HC コントロールプレーン namespace のオブジェクトを復元します。
# AWS $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awscl-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsmt-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/awsm-* # Machines $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machinedeployment-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machineset-* $ oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}/machine-*次の bash スクリプトを実行して、etcd データとホストされたクラスターを復元します。
ETCD_PODS="etcd-0" if [ "${CONTROL_PLANE_AVAILABILITY_POLICY}" = "HighlyAvailable" ]; then ETCD_PODS="etcd-0 etcd-1 etcd-2" fi HC_RESTORE_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-restore.yaml HC_BACKUP_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}.yaml HC_NEW_FILE=${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/hc-${HC_CLUSTER_NAME}-new.yaml cat ${HC_BACKUP_FILE} > ${HC_NEW_FILE} cat > ${HC_RESTORE_FILE} <<EOF restoreSnapshotURL: EOF for POD in ${ETCD_PODS}; do # Create a pre-signed URL for the etcd snapshot ETCD_SNAPSHOT="s3://${BUCKET_NAME}/${HC_CLUSTER_NAME}-${POD}-snapshot.db" ETCD_SNAPSHOT_URL=$(AWS_DEFAULT_REGION=${MGMT2_REGION} aws s3 presign ${ETCD_SNAPSHOT}) # FIXME no CLI support for restoreSnapshotURL yet cat >> ${HC_RESTORE_FILE} <<EOF - "${ETCD_SNAPSHOT_URL}" EOF done cat ${HC_RESTORE_FILE} if ! grep ${HC_CLUSTER_NAME}-snapshot.db ${HC_NEW_FILE}; then sed -i '' -e "/type: PersistentVolume/r ${HC_RESTORE_FILE}" ${HC_NEW_FILE} sed -i '' -e '/pausedUntil:/d' ${HC_NEW_FILE} fi HC=$(oc get hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} -o name || true) if [[ ${HC} == "" ]];then echo "Deploying HC Cluster: ${HC_CLUSTER_NAME} in ${HC_CLUSTER_NS} namespace" oc apply -f ${HC_NEW_FILE} else echo "HC Cluster ${HC_CLUSTER_NAME} already exists, avoiding step" fiノードとノードプールを復元して AWS インスタンスを再利用する場合は、次のコマンドを入力してノードプールを復元します。
oc apply -f ${BACKUP_DIR}/namespaces/${HC_CLUSTER_NS}/np-*
検証
ノードが完全に復元されたことを確認するには、次の関数を使用します。
timeout=40 count=0 NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 while [ ${NODE_POOL_REPLICAS} != ${NODE_STATUS} ] do echo "Waiting for Nodes to be Ready in the destination MGMT Cluster: ${MGMT2_CLUSTER_NAME}" echo "Try: (${count}/${timeout})" sleep 30 if [[ $count -eq timeout ]];then echo "Timeout waiting for Nodes in the destination MGMT Cluster" exit 1 fi count=$((count+1)) NODE_STATUS=$(oc get nodes --kubeconfig=${HC_KUBECONFIG} | grep -v NotReady | grep -c "worker") || NODE_STATUS=0 done
次のステップ
クラスターをシャットダウンして削除します。
7.4.5. ホストされたクラスターのソース管理クラスターからの削除
ホストされたクラスターをバックアップして宛先管理クラスターに復元した後、ソース管理クラスターのホストされたクラスターをシャットダウンして削除します。
前提条件
データをバックアップし、ソース管理クラスターに復元している。
宛先管理クラスターの kubeconfig ファイルが、KUBECONFIG 変数に設定されているとおりに、あるいは、スクリプトを使用する場合は MGMT_KUBECONFIG 変数に設定されているとおりに配置されていることを確認します。export KUBECONFIG=<Kubeconfig FilePath> を使用するか、スクリプトを使用する場合は export KUBECONFIG=${MGMT_KUBECONFIG} を使用します。
手順
以下のコマンドを入力して、
deploymentおよびstatefulsetオブジェクトをスケーリングします。重要spec.persistentVolumeClaimRetentionPolicy.whenScaledフィールドの値がDeleteに設定されている場合は、データの損失につながる可能性があるため、ステートフルセットをスケーリングしないでください。回避策として、
spec.persistentVolumeClaimRetentionPolicy.whenScaledフィールドの値をRetainに更新します。ステートフルセットを調整し、値をDeleteに返すコントローラーが存在しないことを確認してください。これにより、データの損失が発生する可能性があります。# Just in case export KUBECONFIG=${MGMT_KUBECONFIG} # Scale down deployments oc scale deployment -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all oc scale statefulset.apps -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --replicas=0 --all sleep 15次のコマンドを入力して、
NodePoolオブジェクトを削除します。NODEPOOLS=$(oc get nodepools -n ${HC_CLUSTER_NS} -o=jsonpath='{.items[?(@.spec.clusterName=="'${HC_CLUSTER_NAME}'")].metadata.name}') if [[ ! -z "${NODEPOOLS}" ]];then oc patch -n "${HC_CLUSTER_NS}" nodepool ${NODEPOOLS} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete np -n ${HC_CLUSTER_NS} ${NODEPOOLS} fi次のコマンドを入力して、
machineおよびmachinesetオブジェクトを削除します。# Machines for m in $(oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name); do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done oc delete machineset -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all || true次のコマンドを入力して、クラスターオブジェクトを削除します。
# Cluster C_NAME=$(oc get cluster -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${C_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete cluster.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all次のコマンドを入力して、AWS マシン (Kubernetes オブジェクト) を削除します。実際の AWS マシンの削除について心配する必要はありません。クラウドインスタンスへの影響はありません。
# AWS Machines for m in $(oc get awsmachine.infrastructure.cluster.x-k8s.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} -o name) do oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' || true oc delete -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} ${m} || true done次のコマンドを入力して、
HostedControlPlaneおよびControlPlaneHC namespace オブジェクトを削除します。# Delete HCP and ControlPlane HC NS oc patch -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} hostedcontrolplane.hypershift.openshift.io ${HC_CLUSTER_NAME} --type=json --patch='[ { "op":"remove", "path": "/metadata/finalizers" }]' oc delete hostedcontrolplane.hypershift.openshift.io -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} --all oc delete ns ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} || true次のコマンドを入力して、
HostedClusterおよび HC namespace オブジェクトを削除します。# Delete HC and HC Namespace oc -n ${HC_CLUSTER_NS} patch hostedclusters ${HC_CLUSTER_NAME} -p '{"metadata":{"finalizers":null}}' --type merge || true oc delete hc -n ${HC_CLUSTER_NS} ${HC_CLUSTER_NAME} || true oc delete ns ${HC_CLUSTER_NS} || true
検証
すべてが機能することを確認するには、次のコマンドを入力します。
# Validations export KUBECONFIG=${MGMT2_KUBECONFIG} oc get hc -n ${HC_CLUSTER_NS} oc get np -n ${HC_CLUSTER_NS} oc get pod -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} oc get machines -n ${HC_CLUSTER_NS}-${HC_CLUSTER_NAME} # Inside the HostedCluster export KUBECONFIG=${HC_KUBECONFIG} oc get clusterversion oc get nodes
次のステップ
ホストされたクラスター内の OVN Pod を削除して、新しい管理クラスターで実行される新しい OVN コントロールプレーンに接続できるようにします。
-
ホストされたクラスターの kubeconfig パスを使用して
KUBECONFIG環境変数を読み込みます。 以下のコマンドを入力します。
$ oc delete pod -n openshift-ovn-kubernetes --all
7.4.6. ホストされたクラスターをバックアップおよび復元するためのスクリプトの実行
ホストされたクラスターをバックアップし、AWS の同じリージョン内で復元するプロセスを迅速化するために、スクリプトを修正して実行できます。
手順
次のスクリプトの変数を独自の情報に置き換えます。
# Fill the Common variables to fit your environment, this is just a sample SSH_KEY_FILE=${HOME}/.ssh/id_rsa.pub BASE_PATH=${HOME}/hypershift BASE_DOMAIN="aws.sample.com" PULL_SECRET_FILE="${HOME}/pull_secret.json" AWS_CREDS="${HOME}/.aws/credentials" CONTROL_PLANE_AVAILABILITY_POLICY=SingleReplica HYPERSHIFT_PATH=${BASE_PATH}/src/hypershift HYPERSHIFT_CLI=${HYPERSHIFT_PATH}/bin/hypershift HYPERSHIFT_IMAGE=${HYPERSHIFT_IMAGE:-"quay.io/${USER}/hypershift:latest"} NODE_POOL_REPLICAS=${NODE_POOL_REPLICAS:-2} # MGMT Context MGMT_REGION=us-west-1 MGMT_CLUSTER_NAME="${USER}-dev" MGMT_CLUSTER_NS=${USER} MGMT_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT_CLUSTER_NS}-${MGMT_CLUSTER_NAME}" MGMT_KUBECONFIG="${MGMT_CLUSTER_DIR}/kubeconfig" # MGMT2 Context MGMT2_CLUSTER_NAME="${USER}-dest" MGMT2_CLUSTER_NS=${USER} MGMT2_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${MGMT2_CLUSTER_NS}-${MGMT2_CLUSTER_NAME}" MGMT2_KUBECONFIG="${MGMT2_CLUSTER_DIR}/kubeconfig" # Hosted Cluster Context HC_CLUSTER_NS=clusters HC_REGION=us-west-1 HC_CLUSTER_NAME="${USER}-hosted" HC_CLUSTER_DIR="${BASE_PATH}/hosted_clusters/${HC_CLUSTER_NS}-${HC_CLUSTER_NAME}" HC_KUBECONFIG="${HC_CLUSTER_DIR}/kubeconfig" BACKUP_DIR=${HC_CLUSTER_DIR}/backup BUCKET_NAME="${USER}-hosted-${MGMT_REGION}" # DNS AWS_ZONE_ID="Z026552815SS3YPH9H6MG" EXTERNAL_DNS_DOMAIN="guest.jpdv.aws.kerbeross.com"- スクリプトをローカルファイルシステムに保存します。
次のコマンドを入力して、スクリプトを実行します。
source <env_file>
ここの
env_fileは、スクリプトを保存したファイルの名前になります。移行スクリプトは、https://github.com/openshift/hypershift/blob/main/contrib/migration/migrate-hcp.sh のリポジトリーで管理されています。
第8章 Hosted Control Plane のトラブルシューティング
Hosted Control Plane で問題が発生した場合は、次の情報を参照してトラブルシューティングを行ってください。
8.1. Hosted Control Plane のトラブルシューティング用の情報収集
Hosted Control Plane クラスターの問題のトラブルシューティングが必要な場合は、hypershift dump cluster コマンドを実行して情報を収集できます。このコマンドは、管理クラスターとホストされたクラスターの出力を生成します。
管理クラスターの出力には次の内容が含まれます。
- クラスタースコープのリソース: これらのリソースは、管理クラスターのノード定義です。
-
hypershift-dump圧縮ファイル: このファイルは、コンテンツを他の人と共有する必要がある場合に役立ちます。 - namespace リソース: これらのリソースには、config map、サービス、イベント、ログなど、関連する namespace のすべてのオブジェクトが含まれます。
- ネットワークログ: これらのログには、OVN ノースバウンドデータベースとサウスバウンドデータベース、およびそれぞれのステータスが含まれます。
- ホストされたクラスター: このレベルの出力には、ホストされたクラスター内のすべてのリソースが含まれます。
ホストされたクラスターの出力には、次の内容が含まれます。
- クラスタースコープのリソース: これらのリソースには、ノードや CRD などのクラスター全体のオブジェクトがすべて含まれます。
- namespace リソース: これらのリソースには、config map、サービス、イベント、ログなど、関連する namespace のすべてのオブジェクトが含まれます。
出力にはクラスターからのシークレットオブジェクトは含まれませんが、シークレットの名前への参照が含まれる可能性があります。
前提条件
-
管理クラスターへの
cluster-adminアクセス権がある。 -
HostedClusterリソースのname値と、CR がデプロイされる namespace がある。 -
hcpコマンドラインインターフェイスがインストールされている。詳細は、Hosted Control Plane のコマンドラインインターフェイスをインストールする を参照してください。 -
OpenShift CLI (
oc) がインストールされている。 -
kubeconfigファイルがロードされ、管理クラスターを指している。
手順
トラブルシューティングのために出力を収集するには、次のコマンドを入力します。
$ hypershift dump cluster \ --name <hosted_cluster_name> \1 --namespace <hosted_cluster_namespace> \ 2 --dump-guest-cluster \ --artifact-dir clusterDump-<hosted_cluster_namespace>-<hosted_cluster_name>出力例
2023-06-06T12:18:20+02:00 INFO Archiving dump {"command": "tar", "args": ["-cvzf", "hypershift-dump.tar.gz", "cluster-scoped-resources", "event-filter.html", "namespaces", "network_logs", "timestamp"]} 2023-06-06T12:18:21+02:00 INFO Successfully archived dump {"duration": "1.519376292s"}ユーザー名またはサービスアカウントを使用して管理クラスターに対するすべてのクエリーを偽装するようにコマンドラインインターフェイスを設定するには、
--asフラグを指定してhypershift dump clusterコマンドを入力します。サービスアカウントには、namespace のすべてのオブジェクトをクエリーするための十分な権限が必要です。そのため、十分な権限があることを確認するために、
cluster-adminロールを使用することを推奨します。サービスアカウントは、HostedControlPlaneリソースに存在するか、HostedControlPlane リソースの namespace をクエリーする権限を持っている必要があります。ユーザー名またはサービスアカウントに十分な権限がない場合、出力にはアクセス権限のあるオブジェクトのみが含まれます。そのプロセス中に、
forbiddenエラーが表示される場合があります。サービスアカウントを使用して偽装を使用するには、次のコマンドを入力します。
$ hypershift dump cluster \ --name <hosted_cluster_name> \1 --namespace <hosted_cluster_namespace> \2 --dump-guest-cluster \ --as "system:serviceaccount:<service_account_namespace>:<service_account_name>" \ 3 --artifact-dir clusterDump-<hosted_cluster_namespace>-<hosted_cluster_name>ユーザー名を使用して偽装を使用するには、次のコマンドを入力します。
$ hypershift dump cluster \ --name <hosted_cluster_name> \1 --namespace <hosted_cluster_namespace> \2 --dump-guest-cluster \ --as "<cluster_user_name>" \ 3 --artifact-dir clusterDump-<hosted_cluster_namespace>-<hosted_cluster_name>
8.2. ホストされたクラスターと Hosted Control Plane の調整の一時停止
クラスターインスタンス管理者は、ホストされたクラスターと Hosted Control Plane の調整を一時停止できます。etcd データベースをバックアップおよび復元するときや、ホストされたクラスターまたは Hosted Control Plane の問題をデバッグする必要があるときは、調整を一時停止することができます。
手順
ホストされたクラスターと Hosted Control Plane の調整を一時停止するには、
HostedClusterリソースのpausedUntilフィールドを設定します。特定の時刻まで調整を一時停止するには、次のコマンドを入力します。
$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"<timestamp>"}}' --type=merge 1- 1
- RFC339 形式でタイムスタンプを指定します (例:
2024-03-03T03:28:48Z)。指定の時間が経過するまで、調整が一時停止します。
調整を無期限に一時停止するには、次のコマンドを入力します。
$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":"true"}}' --type=mergeHostedClusterリソースからフィールドを削除するまで、調整は一時停止されます。HostedClusterリソースの一時停止調整フィールドが設定されると、そのフィールドは関連付けられたHostedControlPlaneリソースに自動的に追加されます。
pausedUntilフィールドを削除するには、次の patch コマンドを入力します。$ oc patch -n <hosted_cluster_namespace> hostedclusters/<hosted_cluster_name> -p '{"spec":{"pausedUntil":null}}' --type=merge
8.3. データプレーンをゼロにスケールダウンする
Hosted Control Plane を使用していない場合は、リソースとコストを節約するために、データプレーンをゼロにスケールダウンできます。
データプレーンをゼロにスケールダウンする準備ができていることを確認してください。スケールダウンするとワーカーノードからのワークロードがなくなるためです。
手順
次のコマンドを実行して、ホストされたクラスターにアクセスするように
kubeconfigファイルを設定します。$ export KUBECONFIG=<install_directory>/auth/kubeconfig
次のコマンドを実行して、ホストされたクラスターに関連付けられた
NodePoolリソースの名前を取得します。$ oc get nodepool --namespace <HOSTED_CLUSTER_NAMESPACE>
オプション: Pod のドレインを防止するには、次のコマンドを実行して、
NodePoolリソースにnodeDrainTimeoutフィールドを追加します。$ oc edit NodePool <nodepool> -o yaml --namespace <HOSTED_CLUSTER_NAMESPACE>
出力例
apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: # ... name: nodepool-1 namespace: clusters # ... spec: arch: amd64 clusterName: clustername 1 management: autoRepair: false replace: rollingUpdate: maxSurge: 1 maxUnavailable: 0 strategy: RollingUpdate upgradeType: Replace nodeDrainTimeout: 0s 2 # ...
注記ノードドレインプロセスを一定期間継続できるようにするには、それに応じて、
nodeDrainTimeoutフィールドの値を設定できます (例:nodeDrainTimeout: 1m)。次のコマンドを実行して、ホストされたクラスターに関連付けられた
NodePoolリソースをスケールダウンします。$ oc scale nodepool/<NODEPOOL_NAME> --namespace <HOSTED_CLUSTER_NAMESPACE> --replicas=0
注記データプランをゼロにスケールダウンした後、コントロールプレーン内の一部の Pod は
Pendingステータスのままになり、ホストされているコントロールプレーンは稼働したままになります。必要に応じて、NodePoolリソースをスケールアップできます。オプション: 次のコマンドを実行して、ホストされたクラスターに関連付けられた
NodePoolリソースをスケールアップします。$ oc scale nodepool/<NODEPOOL_NAME> --namespace <HOSTED_CLUSTER_NAMESPACE> --replicas=1
NodePoolリソースを再スケーリングした後、NodePoolリソースが準備Ready状態で使用可能になるまで数分間待ちます。
検証
次のコマンドを実行して、
nodeDrainTimeoutフィールドの値が0sより大きいことを確認します。$ oc get nodepool -n <hosted_cluster_namespace> <nodepool_name> -ojsonpath='{.spec.nodeDrainTimeout}'