
Red Hat Insights guidelines for deployment at scale
Insights guidelines for deployment at scale
Insights usage varies from customer to customer so there is no real "one size fits all" template. However it is worth highlighting some of the features Red Hat has in place to assist with large sized deployments. This is not intended to be a best-practices guide, just some things to consider.
Deployment
I typically emphasize how easy it is to deploy insights - with its minimal steps, because it is a SaaS solution. See the getting started guide. If a customer happens to be also managing these systems via a version of Satellite with Insights integration, mass registration of Insights is built in (via the bootstrap script provided with Satellite).
Proxy
A proxy is not required to be used for Insights, but typically the systems of customers with larger scale deployments are already set up to communicate with Red Hat via a proxy, rather than being individually connected (or in disconnected environments). Insights also supports this infrastructure model via proxy support as an option within our client, so there are no changes that you as the customer need to make to how your systems communicate with our servers.
If you are using a version of Satellite with Insights integration, it can be used as the proxy.
Frequency
By default, Insights sends information once daily. We find that this default frequency fits the needs of most accounts.
However, one may have concerns about the impact, at scale, of all these clients checking in and transmitting a payload on your network. To help with this, we have implemented a default feature to make the Insights client automatically stagger its check-in time; so rather than all checking in at once, they'll check in individually or in random groups. All out of the box!
And if you want to take it a step further and have full control of your own schedule, the Insights client can be customized via cron (when using RHEL 6) or via systemd (when using RHEL 7.5+).
Remediation
Setting up the systems is one thing to consider at scale, but once Insights is setup and detecting all those problems now on 1000+ systems, how do you take action at scale?
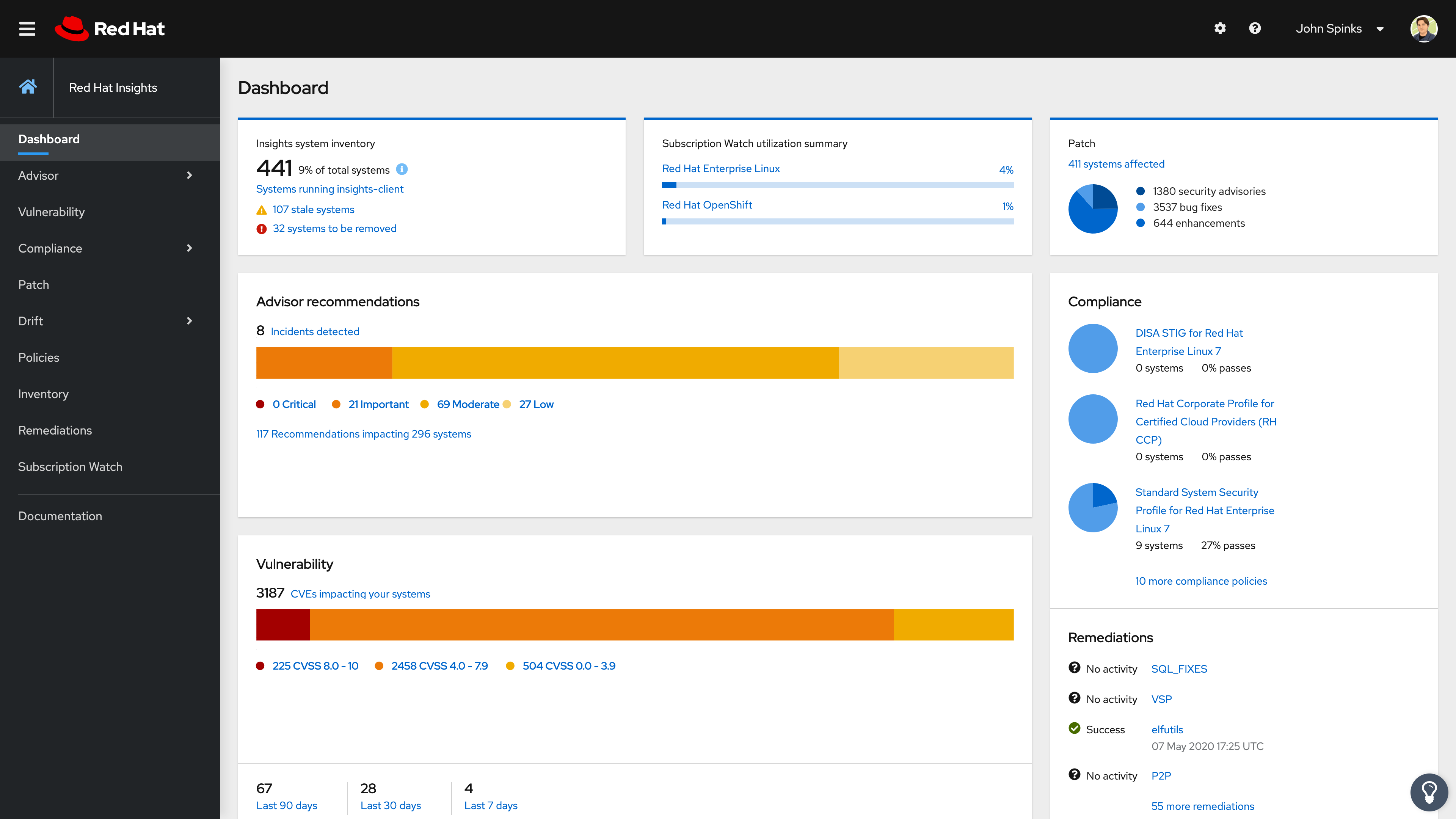
A few recommendations in this regard would be:
* Use Ansible remediation with Insights-generated playbooks to coordinate a fix for one or multiple issues impacting your infrastructure.
-
Use Remediations to help coordinate planned remediations for actions and systems.
-
Address by severity - Insights applies one of 4 severity (risk) levels to all actions to help you focus on the most important ones.
-
Attack the low hanging fruit - Insights also provides a "Risk of Change" rating for actions depending on the impact of the change on the environment. Remediating actions with the lowest Risk of Change generally won't require any downtime or coordination.
About The Author
 Red Hat
Community Member
65 points
Red Hat
Community Member
65 points
Comments