
Network Observability(网络可观察性)
在 OpenShift Container Platform 中配置和使用 Network Observability Operator
摘要
第 1 章 Network Observability Operator 发行注记
Network Observability Operator 可让管理员观察和分析 OpenShift Container Platform 集群的网络流量流。
本发行注记介绍了 OpenShift Container Platform 中 Network Observability Operator 的开发。
有关 Network Observability Operator 的概述,请参阅关于 Network Observability Operator。
1.1. Network Observability Operator 1.5.0
以下公告可用于 Network Observability Operator 1.5.0:
1.1.1. 新功能及功能增强
1.1.1.1. DNS 跟踪增强
在 1.5 中,除了 UDP 外,还支持 TCP 协议。在 Network Traffic 页面的 Overview 视图中添加了新的仪表板。如需更多信息,请参阅配置 DNS 跟踪和使用 DNS 跟踪。
1.1.1.2. 往返时间 (RTT)
您可以使用从 fentry/tcp_rcv_ established Extended Berkeley Packet Filter (eBPF) hookpoint 中捕获的 TCP 握手 Round-Trip Time (RTT) 来读取平稳的往返时间(SRTT) 并分析网络流。在 web 控制台中的 Overview、Network Traffic、和 Topology 页面中,您可以监控网络流量,并使用 RTT 指标、过滤和边缘标记进行故障排除。如需更多信息,请参阅 RTT 概述和使用 RTT。
1.1.1.3. 指标、仪表板和警报增强
Observe → Dashboards → NetObserv 中的 Network Observability 指标仪表板具有可用于创建 Prometheus 警报的新指标类型。现在,您可以在 includeList 规格中定义可用指标。在以前的版本中,这些指标在 ignoreTags 规格中定义。有关这些指标的完整列表,请参阅 Network Observability Metrics。
1.1.1.4. 没有 Loki 的 Network Observability 的改进
您可以使用 DNS、Packet drop 和 RTT 指标为 Netobserv 仪表板创建 Prometheus 警报,即使您不使用 Loki。在以前的 Network Observability 版本 1.4 中,这些指标仅适用于 Network Traffic、Overview 和 Topology 视图中查询和分析,这些指标在没有 Loki 的情况下不可用。如需更多信息,请参阅 Network Observability Metrics。
1.1.1.5. 可用区
您可以配置 FlowCollector 资源来收集有关集群可用区的信息。此配置增强了使用应用到节点的 topology.kubernetes.io/zone 标签值的网络流数据。如需更多信息,请参阅使用可用区。
1.1.1.6. 主要改进
Network Observability Operator 的 1.5 发行版本为 OpenShift Container Platform Web 控制台插件和 Operator 配置添加了改进和新功能。
性能增强
spec.agent.ebpf.kafkaBatchSize的默认设置从10MB改为1MB,以便在使用 Kafka 时增强 eBPF 性能。重要当从现有安装升级时,不会在配置中自动设置这个新值。如果您在升级后发现 eBPF 代理内存消耗的性能出现回归的问题,您可以考虑将
kafkaBatchSize减少为一个新值。
Web 控制台增强:
- 在 DNS 和 RTT 的 Overview 视图中添加了新的面板:Min、Max、P90、P99。
添加了新的面板显示选项:
- 专注于一个面板,同时保持其他面板可查看但没有主要关注。
- 切换图形类型。
- 显示 Top 和 Overall。
- 自定义时间范围弹出窗口中会显示集合延迟警告。
- 增强了管理面板和管理列弹出窗口内容的可见性。
- 在 web 控制台的 Network Traffic 页面中,可以使用 egress QoS 的 Differentiated Services Code Point (DSCP) 字段来对 QoS DSCP 进行过滤。
配置增强:
-
spec.loki.mode规格中的LokiStack模式会自动设置 URL、TLS、集群角色和集群角色绑定,以及authToken值,来简化安装。Manual模式允许对这些设置进行更多控制。 -
API 版本从
flows.netobserv.io/v1beta1更新到flows.netobserv.io/v1beta2。
1.1.2. 程序错误修复
-
在以前的版本中,如果禁用了 console 插件的自动注册功能,则无法在 web 控制台界面中手动注册 console 插件。如果在
FlowCollector资源中将spec.console.register值设置为false,Operator 会覆盖并清除插件注册。在这个版本中,将spec.console.register值设置为false不会影响控制台插件注册或删除。因此,可以安全地手动注册插件。(NETOBSERV-1134) -
在以前的版本中,使用默认指标设置,NetObserv/Health 仪表板显示一个名为 Flows Overhead 的空图形。这个指标只能通过从
ignoreTags列表中删除 "namespaces-flows" 和 "namespaces" 时才可用。在这个版本中,在使用默认指标设置时,此指标可见。(NETOBSERV-1351) - 在以前的版本中,运行 eBPF 代理的节点无法使用一个特定的集群配置解析。这会导致一连串的后果,并导致无法提供一些流量指标。在这个版本中,eBPF 代理的节点 IP 由 Operator 安全提供,从 pod 状态推断出。现在,缺少的指标会被恢复。(NETOBSERV-1430)
- 在以前的版本中,Loki Operator 的 Loki 错误 'Input size too long' 错误中没有包括可以帮助进行故障排除的额外信息。在这个版本中,帮助信息在 web 控制台中的错误旁显示,并带有直接链接来获得更详细的信息。(NETOBSERV-1464)
-
在以前的版本中,控制台插件读取超时被强制为 30s。使用
FlowCollectorv1beta2API 更新,您可以配置spec.loki.readTimeout规格来根据 Loki OperatorqueryTimeout限制更新这个值。(NETOBSERV-1443) -
在以前的版本中,Operator 捆绑包不会按预期显示 CSV 注解的一些支持功能,如
features.operators.openshift.io/…。在这个版本中,这些注解会在 CSV 中按预期设置。(NETOBSERV-1305) -
在以前的版本中,在协调过程中,
FlowCollector状态有时会在DeploymentInProgress和Ready状态之间转换。在这个版本中,只有在所有底层组件都完全就绪时,状态才会变为Ready。(NETOBSERV-1293)
1.1.3. 已知问题
-
当尝试访问 web 控制台时,OCP 4.14.10 上的缓存问题会阻止访问 Observe 视图。Web 控制台显示错误消息:
Failed to get a valid plugin manifest from /api/plugins/monitoring-plugin/.推荐的解决方法是,把集群升级到最新的次版本。如果这无法解决问题,请参阅红帽知识库文章。(NETOBSERV-1493) -
由于 Network Observability Operator 的 1.3.0 发行版本,安装 Operator 会导致出现警告内核污点。此错误的原因是,Network Observability eBPF 代理具有内存限制,可防止预分配整个 hashmap 表。Operator eBPF 代理设置
BPF_F_NO_PREALLOC标志,以便在 hashmap 过内存扩展时禁用预分配。
1.2. Network Observability Operator 1.4.2
以下公告可用于 Network Observability Operator 1.4.2:
1.2.1. CVE
1.3. Network Observability Operator 1.4.1
以下公告可用于 Network Observability Operator 1.4.1:
1.3.1. CVE
1.3.2. 程序错误修复
- 在 1.4 中,向 Kafka 发送网络流数据时存在一个已知问题。Kafka 消息密钥被忽略,从而导致带有连接跟踪的错误。现在,密钥用于分区,因此来自同一连接的每个流都会发送到同一处理器。(NETOBSERV-926)
-
在 1.4 中,引入了
Inner流方向,以考虑在同一节点上运行的 pod 间的流。在生成的 Prometheus 指标中不会考虑从流派生的 Prometheus 指标中的带有Inner方向的流,从而导致出现以下字节和数据包率。现在,派生的指标包括带有Inner方向的流,提供正确的字节和数据包率。(NETOBSERV-1344)
1.4. Network Observability Operator 1.4.0
以下公告可用于 Network Observability Operator 1.4.0:
1.4.1. 频道删除
您必须将频道从 v1.0.x 切换到 stable,以接收最新的 Operator 更新。v1.0.x 频道现已被删除。
1.4.2. 新功能及功能增强
1.4.2.1. 主要改进
Network Observability Operator 的 1.4 发行版本为 OpenShift Container Platform Web 控制台插件和 Operator 配置添加了改进和新功能。
Web 控制台增强:
- 在 Query Options 中,添加了 Duplicate 流 复选框,以选择要显示重复流。
-
现在您可以使用
 One-way,
One-way,
 Back-and-forth, 和 Swap 过滤器过滤源和目标流。
Back-and-forth, 和 Swap 过滤器过滤源和目标流。
Observe → Dashboards → NetObserv 和 NetObserv / Health 中的 Network Observability 指标仪表板被修改,如下所示:
- NetObserv 仪表板显示顶级字节、数据包发送、每个节点、命名空间和工作负载接收的数据包。流图从此仪表板中删除。
- NetObserv / Health 仪表板显示流开销,以及每个节点的流率、命名空间和工作负载。
- 基础架构和应用程序指标显示在命名空间和工作负载的 split-view 中。
如需更多信息,请参阅 Network Observability 指标和快速过滤器。
配置增强:
- 现在,您可以选择为任何配置的 ConfigMap 或 Secret 引用指定不同的命名空间,如证书配置中。
-
添加
spec.processor.clusterName参数,以便集群名称出现在流数据中。这在多集群上下文中很有用。使用 OpenShift Container Platform 时,留空,使其自动决定。
如需更多信息,请参阅 流收集器示例资源和流收集器 API 参考。
1.4.2.2. 没有 Loki 的 Network Observability
Network Observability Operator 现在可以在没有 Loki 的情况下正常工作。如果没有安装 Loki,它只能将流导出到 KAFKA 或 IPFIX 格式,并在 Network Observability 指标仪表板中提供指标。如需更多信息,请参阅没有 Loki 的网络可观察性。
1.4.2.3. DNS 跟踪
在 1.4 中,Network Observability Operator 使用 eBPF 追踪点 hook 启用 DNS 跟踪。您可以监控网络,执行安全分析,并对 web 控制台中的 Network Traffic 和 Overview 页面中的 DNS 问题进行故障排除。
1.4.2.4. SR-IOV 支持
现在,您可以使用单根 I/O 虚拟化(SR-IOV)设备从集群收集流量。如需更多信息,请参阅配置 SR-IOV 接口流量的监控。
1.4.2.5. 支持 IPFIX exporter
现在,您可以将 eBPF 丰富的网络流导出到 IPFIX 收集器。如需更多信息,请参阅导出增强的网络流数据。
1.4.2.6. 数据包丢弃
在 Network Observability Operator 的 1.4 发行版本中,eBPF 追踪点 hook 用于启用数据包丢弃跟踪。现在,您可以检测和分析数据包丢弃的原因,并做出决策来优化网络性能。在 OpenShift Container Platform 4.14 及更高版本中,会检测主机丢弃和 OVS 丢弃。在 OpenShift Container Platform 4.13 中,只检测主机丢弃。如需更多信息,请参阅配置数据包丢弃跟踪和使用数据包丢弃。
1.4.2.7. s390x 架构支持
Network Observability Operator 现在可在 s390x 构架中运行。以前,它在 amd64、ppc64le 或 arm64 上运行。
1.4.3. 程序错误修复
- 在以前的版本中,被 Network Observability 导出的 Prometheus 指标会忽略潜在的重复网络流。在相关的仪表板中,在 Observe → Dashboards 中,这可能会导致潜在的双倍率。请注意,来自 Network Traffic 视图中的仪表板不会受到影响。现在,会过滤网络流以消除指标计算前的重复项,仪表板中会显示正确的流量率。(NETOBSERV-1131)
-
在以前的版本中,当使用 Multus 或 SR-IOV (非默认网络命名空间)配置时,Network Observability Operator 代理无法捕获网络接口上的流量。现在,所有可用的网络命名空间都会被识别并用于捕获 SR-IOV 的流量。
FlowCollector和SRIOVnetwork自定义资源收集流量需要的配置。(NETOBSERV-1283) -
在以前的版本中,在 Operators → Installed Operators 的 Network Observability Operator 详情中,
FlowCollectorStatus 字段可能会报告有关部署状态的错误信息。现在,status 字段会显示正确的信息。保持的事件历史记录,按事件日期排序。(NETOBSERV-1224) -
在以前的版本中,在网络流量负载激增时,某些 eBPF pod 被 OOM 终止,并进入
CrashLoopBackOff状态。现在,eBPF代理内存占用率有所改进,因此 pod 不会被 OOM 终止,并进入CrashLoopBackOff状态。(NETOBSERV-975) -
在以前的版本中,当
processor.metrics.tls设置为PROVIDED时,insecureSkipVerify选项值被强制为true。现在,您可以将insecureSkipVerify设置为true或false,并在需要时提供 CA 证书。(NETOBSERV-1087)
1.4.4. 已知问题
-
由于 Network Observability Operator 的 1.2.0 发行版本使用 Loki Operator 5.6,Loki 证书更改会定期影响
flowlogs-pipelinepod,并导致丢弃流而不是写入 Loki 的流。一段时间后,问题会自行修正,但它仍然会在 Loki 证书更改过程中导致临时流数据丢失。此问题仅在有 120 个节点或更多节点的大型环境中观察到。(NETOBSERV-980) -
目前,当
spec.agent.ebpf.features包括 DNSTracking 时,更大的 DNS 数据包需要eBPF代理在第一套接字缓冲区(SKB)网段外查找 DNS 标头。需要实施新的eBPF代理帮助程序功能来支持它。目前,这个问题还没有临时解决方案。(NETOBSERV-1304) -
目前,当
spec.agent.ebpf.features包括 DNSTracking 时,通过 TCP 数据包的 DNS 需要eBPF代理在 1st SKB 段外查找 DNS 标头。需要实施新的eBPF代理帮助程序功能来支持它。目前,这个问题还没有临时解决方案。(NETOBSERV-1245) -
目前,在使用
KAFKA部署模型时,如果配置了对话跟踪,则对话事件可能会在 Kafka 用户间重复,导致跟踪对话不一致和不正确的 volumetric 数据。因此,不建议在deploymentModel设置为KAFKA时配置对话跟踪。(NETOBSERV-926) -
目前,当
processor.metrics.server.tls.type配置为使用PROVIDED证书时,Operator 会进入一个没有就绪的状态,该状态可能会影响其性能和资源消耗。在解决此问题解决前,建议不要使用PROVIDED证书,而是使用自动生成的证书,将processor.metrics.server.tls.type设置为AUTO。(NETOBSERV-1293 -
由于 Network Observability Operator 的 1.3.0 发行版本,安装 Operator 会导致出现警告内核污点。此错误的原因是,Network Observability eBPF 代理具有内存限制,可防止预分配整个 hashmap 表。Operator eBPF 代理设置
BPF_F_NO_PREALLOC标志,以便在 hashmap 过内存扩展时禁用预分配。
1.5. Network Observability Operator 1.3.0
以下公告可用于 Network Observability Operator 1.3.0 :
1.5.1. 频道弃用
您必须将频道从 v1.0.x 切换到 stable,以接收将来的 Operator 更新。v1.0.x 频道已弃用,计划在以后的发行版本中删除。
1.5.2. 新功能及功能增强
1.5.2.1. Network Observability 中的多租户
- 系统管理员可以将单独的用户访问或组访问权限限制为存储在 Loki 中的流。如需更多信息,请参阅 Network Observability 中的多租户。
1.5.2.2. 基于流的指标仪表板
- 此发行版本添加了一个新的仪表板,它概述了 OpenShift Container Platform 集群中的网络流。如需更多信息,请参阅 Network Observability 指标。
1.5.2.3. 使用 must-gather 工具进行故障排除
- 有关 Network Observability Operator 的信息现在可以包含在 must-gather 数据中以进行故障排除。如需更多信息,请参阅 Network Observability must-gather。
1.5.2.4. 现在支持多个构架
-
Network Observability Operator 现在可在
amd64、ppc64le或arm64架构上运行。在以前的版本中,它只在amd64上运行。
1.5.3. 已弃用的功能
1.5.3.1. 弃用的配置参数设置
Network Observability Operator 1.3 发行版本弃用了 spec.Loki.authToken HOST 设置。使用 Loki Operator 时,现在必须使用 FORWARD 设置。
1.5.4. 程序错误修复
-
在以前的版本中,当通过 CLI 安装 Operator 时,Cluster Monitoring Operator 所需的
Role和RoleBinding不会按预期安装。从 Web 控制台安装 Operator 时,不会出现这个问题。现在,安装 Operator 的任何方法都会安装所需的Role和RoleBinding。(NETOBSERV-1003) -
自版本 1.2 起,Network Observability Operator 可以在流集合出现问题时引发警报。在以前的版本中,由于一个程序错误,用于禁用警报的相关配置,
spec.processor.metrics.disableAlerts无法正常工作,有时无效。现在,此配置已被修复,可以禁用警报。(NETOBSERV-976) -
在以前的版本中,当 Network Observability 被配置为
spec.loki.authToken为DISABLED时,只有kubeadmin集群管理员才能查看网络流。其他类型的集群管理员收到授权失败。现在,任何集群管理员都可以查看网络流。(NETOBSERV-972) -
在以前的版本中,一个 bug 会阻止用户将
spec.consolePlugin.portNaming.enable设置为false。现在,此设置可以设置为false来禁用端口到服务名称转换。(NETOBSERV-971) - 在以前的版本中,Cluster Monitoring Operator (Prometheus) 不会收集由 console 插件公开的指标,因为配置不正确。现在,配置已被修复,控制台插件指标可以被正确收集并从 OpenShift Container Platform Web 控制台访问。(NETOBSERV-765)
-
在以前的版本中,当在
FlowCollector中将processor.metrics.tls设置为AUTO时,flowlogs-pipeline servicemonitor不会适应适当的 TLS 方案,且指标在 web 控制台中不可见。现在,这个问题已针对 AUTO 模式解决。(NETOBSERV-1070) -
在以前的版本中,证书配置(如 Kafka 和 Loki)不允许指定 namespace 字段,这意味着证书必须位于部署 Network Observability 的同一命名空间中。另外,当在 TLS/mTLS 中使用 Kafka 时,用户必须手动将证书复制到部署
eBPF代理 pod 的特权命名空间,并手动管理证书更新,如证书轮转时。现在,通过在FlowCollector资源中为证书添加 namespace 字段来简化 Network Observability 设置。现在,用户可以在不同的命名空间中安装 Loki 或 Kafka,而无需在 Network Observability 命名空间中手动复制其证书。原始证书会被监视,以便在需要时自动更新副本。(NETOBSERV-773) - 在以前的版本中,Network Observability 代理没有涵盖 SCTP、ICMPv4 和 ICMPv6 协议,从而导致较少的全面的网络流覆盖。现在,这些协议可以被识别以改进流覆盖。(NETOBSERV-934)
1.5.5. 已知问题
-
当
FlowCollector中的processor.metrics.tls设置为PROVIDED时,flowlogs-pipelineservicemonitor不会适应 TLS 方案。(NETOBSERV-1087) -
由于 Network Observability Operator 的 1.2.0 发行版本使用 Loki Operator 5.6,Loki 证书更改会定期影响
flowlogs-pipelinepod,并导致丢弃流而不是写入 Loki 的流。一段时间后,问题会自行修正,但它仍然会在 Loki 证书更改过程中导致临时流数据丢失。此问题仅在有 120 个节点或更多节点的大型环境中观察到。(NETOBSERV-980) -
安装 Operator 时,可能会出现警告内核污点。此错误的原因是,Network Observability eBPF 代理具有内存限制,可防止预分配整个 hashmap 表。Operator eBPF 代理设置
BPF_F_NO_PREALLOC标志,以便在 hashmap 过内存扩展时禁用预分配。
1.6. Network Observability Operator 1.2.0
以下公告可用于 Network Observability Operator 1.2.0 :
1.6.1. 准备下一次更新
已安装的 Operator 的订阅指定一个更新频道,用于跟踪和接收 Operator 的更新。在 Network Observability Operator 的 1.2 发布前,唯一可用的频道为 v1.0.x。Network Observability Operator 的 1.2 发行版本引入了用于跟踪和接收更新的 stable 更新频道。您必须将频道从 v1.0.x 切换到 stable,以接收将来的 Operator 更新。v1.0.x 频道已弃用,计划在以后的发行版本中删除。
1.6.2. 新功能及功能增强
1.6.2.1. 流量流视图中的直方图
- 现在,您可以选择显示一段时间内流的直方图表。histogram 可让您视觉化流历史记录,而不会达到 Loki 查询的限制。如需更多信息,请参阅使用直方图。
1.6.2.2. 对话跟踪
- 现在,您可以通过 Log Type 查询流,它允许对同一对话一部分的网络流进行分组。如需更多信息,请参阅使用对话。
1.6.2.3. Network Observability 健康警报
-
现在,如果因为写入阶段出现错误,或者达到 Loki ingestion 速率限制,Network Observability Operator 会在
flowlogs-pipeline丢弃流时自动创建自动警报。如需更多信息,请参阅查看健康信息。
1.6.3. 程序错误修复
-
在以前的版本中,在更改 FlowCollector spec 中的
namespace值后,在前一个命名空间中运行的eBPF代理 pod 没有被适当删除。现在,在上一个命名空间中运行的 pod 会被正确删除。(NETOBSERV-774) -
在以前的版本中,在更改 FlowCollector spec (如 Loki 部分)中的
caCert.name值后,FlowLogs-Pipeline pod 和 Console 插件 pod 不会重启,因此它们不知道配置更改。现在,pod 被重启,因此它们会获得配置更改。(NETOBSERV-772) - 在以前的版本中,在不同节点上运行的 pod 间的网络流有时没有正确识别为重复,因为它们由不同的网络接口捕获。这会导致控制台插件中显示过量的指标。现在,流会被正确识别为重复,控制台插件会显示准确的指标。(NETOBSERV-755)
- 控制台插件中的 "reporter" 选项用于根据源节点或目标节点的观察点过滤流。在以前的版本中,无论节点观察点是什么,这个选项都会混合流。这是因为在节点级别将网络流错误地报告为 Ingress 或 Egress。现在,网络流方向报告是正确的。源观察点的 "reporter" 选项过滤器,或目标观察点如预期。( NETOBSERV-696)
- 在以前的版本中,对于配置为直接将流作为 gRPC+protobuf 请求发送的代理,提交的有效负载可能太大,并由处理器的 GRPC 服务器拒绝。这会在有非常高负载的场景中发生,且只会发生在一些代理配置中。代理记录错误消息,例如:grpc: received message larger than max。因此,缺少有关这些流的信息丢失。现在,当大小超过阈值时,gRPC 有效负载被分成多个信息。因此,服务器可以维护连接状态。(NETOBSERV-617)
1.6.4. 已知问题
-
在 Network Observability Operator 的 1.2.0 发行版本中,使用 Loki Operator 5.6,Loki 证书转换会定期影响
flowlogs-pipelinepod,并导致丢弃流而不是写入 Loki 的流程。一段时间后,问题会自行修正,但它仍然会在 Loki 证书转换过程中导致临时流数据丢失。(NETOBSERV-980)
1.6.5. 主要的技术变化
-
在以前的版本中,您可以使用自定义命名空间安装 Network Observability Operator。此发行版本引入了
转换 Webhook,它更改了ClusterServiceVersion。由于这个变化,所有可用的命名空间不再被列出。另外,要启用 Operator 指标集合,无法使用与其他 Operator 共享的命名空间(如openshift-operators命名空间)。现在,Operator 必须安装在openshift-netobserv-operator命名空间中。如果您之前使用自定义命名空间安装 Network Observability Operator,则无法自动升级到新的 Operator 版本。如果您之前使用自定义命名空间安装 Operator,您必须删除已安装的 Operator 实例,并在openshift-netobserv-operator命名空间中重新安装 Operator。务必要注意,对于FlowCollector、Loki、Kafka 和其他插件,仍可使用自定义命名空间(如常用的netobserv命名空间)。(NETOBSERV-907)(NETOBSERV-956)
1.7. Network Observability Operator 1.1.0
以下公告可用于 Network Observability Operator 1.1.0:
Network Observability Operator 现在稳定,发行频道已升级到 v1.1.0。
1.7.1. 程序错误修复
-
在以前的版本中,除非 Loki
authToken配置被设置为FORWARD模式,否则不再强制执行身份验证,允许任何可以在 OpenShift Container Platform 集群中连接到 OpenShift Container Platform 控制台的用户,在没有身份验证的情况下检索流。现在,无论 LokiauthToken模式如何,只有集群管理员才能检索流。(BZ#2169468)
第 2 章 关于网络可观察性
红帽为集群管理员提供 Network Observability Operator 来观察 OpenShift Container Platform 集群的网络流量。Network Observability Operator 使用 eBPF 技术创建网络流。然后,OpenShift Container Platform 信息会增强网络流,并存储在 Loki 中。您可以在 OpenShift Container Platform 控制台中查看和分析所存储的 netflow 信息,以进一步洞察和故障排除。
2.1. Network Observability Operator 的可选依赖项
- Loki Operator:Loki 是用于存储所有收集的流的后端。建议您安装 Loki 与 Network Observability Operator 搭配使用。您可以选择 在没有 Loki 的情况下使用 Network Observability,但有一些注意事项,如链接部分所述。如果您选择安装 Loki,建议使用 Loki Operator,因为红帽支持它。
- Grafana Operator:您可以使用开源产品(如 Grafana Operator)安装 Grafana 以创建自定义仪表板和查询功能。红帽不支持 Grafana Operator。
- AMQ Streams Operator:Kafka 在 OpenShift Container Platform 集群中为大规模部署提供可扩展性、弹性和高可用性。如果您选择使用 Kafka,建议使用 AMQ Streams Operator,因为红帽支持它。
2.2. Network Observability Operator
Network Observability Operator 提供 Flow Collector API 自定义资源定义。流收集器实例是在安装过程中创建的,并启用网络流集合的配置。Flow Collector 实例部署 pod 和服务,它们组成一个监控管道,然后收集网络流并将其与 Kubernetes 元数据一起增强,然后再存储在 Loki 中。eBPF 代理作为 daemonset 对象部署,会创建网络流。
2.3. OpenShift Container Platform 控制台集成
OpenShift Container Platform 控制台集成提供了概述、拓扑视图和流量流表。
2.3.1. Network Observability 指标仪表板
在 OpenShift Container Platform 控制台中的 Overview 选项卡中,您可以查看集群中网络流量流的整体聚合指标。您可以选择按节点、命名空间、所有者、pod、区和服务显示信息。过滤器和显示选项可以进一步优化指标。如需更多信息,请参阅从 Overview 视图中获取网络流量。
在 Observe → Dashboards 中,Netobserv 仪表板提供了 OpenShift Container Platform 集群中网络流的快速概述。Netobserv/Health 仪表板提供有关 Operator 健康状况的指标。如需更多信息,请参阅 Network Observability Metrics 和查看健康信息。
2.3.2. Network Observability 拓扑视图
OpenShift Container Platform 控制台提供 Topology 选项卡,显示网络流的图形表示和流量数量。拓扑视图代表 OpenShift Container Platform 组件之间的流量,作为网络图。您可以使用过滤器和显示选项重新定义图形。您可以访问节点、命名空间、所有者、pod 和服务的信息。
2.3.3. 流量流表
流量流表视图为原始流、非聚合过滤选项和可配置列提供视图。OpenShift Container Platform 控制台提供 流量流 标签页,显示网络流的数据和流量数量。
第 3 章 安装 Network Observability Operator
安装 Loki 是使用 Network Observability Operator 的建议前提条件。您可以选择在没有 Loki 的情况下使用 Network Observability,但有一些注意事项。
Loki Operator 集成了通过 Loki 实现多租户和身份验证的网关,以进行数据流存储。LokiStack 资源管理 Loki,它是一个可扩展、高度可用、多租户日志聚合系统和使用 OpenShift Container Platform 身份验证的 Web 代理。LokiStack 代理使用 OpenShift Container Platform 身份验证来强制实施多租户,并方便在 Loki 日志存储中保存和索引数据。
Loki Operator 也可用于 配置 LokiStack 日志存储。Network Observability Operator 需要一个专用的、与日志分开的 LokiStack。
3.1. 没有 Loki 的 Network Observability
您可以通过不执行 Loki 安装步骤,直接跳过至"安装 Network Observability Operator",来使用没有 Loki 的 Network Observability。如果您只想将流导出到 Kafka 消费者或 IPFIX 收集器,或者您只需要仪表板指标,则不需要为 Loki 安装 Loki 或为 Loki 提供存储。如果没有 Loki,在 Observe 下不会有一个 Network Traffic 面板,这意味着没有概述图表、流表或拓扑。下表将可用功能与没有 Loki 进行比较:
表 3.1. 功能可用性与没有 Loki 的功能的比较
| 带有 Loki | 没有 Loki | |
|---|---|---|
| Exporters |
|
|
| 基于流的指标和仪表板 |
|
|
| 流量流概述、表和拓扑视图 |
|
|
| 快速过滤器 |
|
|
| OpenShift Container Platform 控制台 Network Traffic 标签页集成 |
|
|
其他资源
3.2. 安装 Loki Operator
Loki Operator 版本 5.7+ 是 Network Observabilty 支持的 Loki Operator 版本。这些版本提供了使用 openshift-network 租户配置模式创建 LokiStack 实例的功能,并为 Network Observability 提供完全自动的、集群内身份验证和授权支持。您可以通过几种方法安装 Loki。其中一种方法是使用 OpenShift Container Platform Web 控制台 Operator Hub。
先决条件
- 支持的日志存储(AWS S3、Google Cloud Storage、Azure、Swift、Minio、OpenShift Data Foundation)
- OpenShift Container Platform 4.10+
- Linux Kernel 4.18+
流程
- 在 OpenShift Container Platform Web 控制台中,点击 Operators → OperatorHub。
- 从可用的 Operator 列表中选择 Loki Operator,然后点 Install。
- 在 Installation Mode 下,选择 All namespaces on the cluster。
验证
- 验证您安装了 Loki Operator。访问 Operators → Installed Operators 页面,并查找 Loki Operator。
- 验证 Loki Operator 是否在所有项目中 Status 为 Succeeded。
要卸载 Loki,请参考与用来安装 Loki 的方法相关的卸载过程。您可能会有剩余的 ClusterRole 和 ClusterRoleBindings、存储在对象存储中的数据,以及需要被删除的持久性卷。
3.2.1. 为 Loki 存储创建 secret
Loki Operator 支持几个日志存储选项,如 AWS S3、Google Cloud Storage、Azure、Swift、Minio、OpenShift Data Foundation。以下示例演示了如何为 AWS S3 存储创建 secret。本例中创建的 secret loki-s3 在"Creating a LokiStack resource"中引用。您可以通过 web 控制台或 CLI 中创建此 secret。
-
使用 Web 控制台,进入到 Project → All Projects 下拉菜单,再选择 Create Project。将项目命名为
netobserv,再点 Create。 使用右上角的 Import 图标 +。将 YAML 文件粘贴到编辑器中。
下面显示了一个 S3 存储的 secret YAML 文件示例:
apiVersion: v1 kind: Secret metadata: name: loki-s3 namespace: netobserv 1 stringData: access_key_id: QUtJQUlPU0ZPRE5ON0VYQU1QTEUK access_key_secret: d0phbHJYVXRuRkVNSS9LN01ERU5HL2JQeFJmaUNZRVhBTVBMRUtFWQo= bucketnames: s3-bucket-name endpoint: https://s3.eu-central-1.amazonaws.com region: eu-central-1- 1
- 本文档中的安装示例在所有组件中使用相同的命名空间
netobserv。您可以选择将不同的命名空间用于不同的组件
验证
- 创建 secret 后,您应该会在 web 控制台的 Workloads → Secrets 下看到它。
其他资源
3.2.2. 创建 LokiStack 自定义资源
您可以使用 Web 控制台或 OpenShift CLI (oc) 部署 LokiStack 自定义资源(CR)来创建命名空间或新项目。
流程
- 进入到 Operators → Installed Operators,从 Project 下拉菜单查看 All projects。
- 查找 Loki Operator。在详情的 Provided APIs 下,选择 LokiStack。
- 点 Create LokiStack。
确保在 Form View 或 YAML 视图中指定以下字段:
apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv 1 spec: size: 1x.small 2 storage: schemas: - version: v12 effectiveDate: '2022-06-01' secret: name: loki-s3 type: s3 storageClassName: gp3 3 tenants: mode: openshift-network
- 点 Create。
3.2.3. 为 cluster-admin 用户角色创建新组
以 cluster-admin 用户身份查询多个命名空间的应用程序日志,其中集群中所有命名空间的字符总和大于 5120,会导致错误 Parse error: input size too long (XXXX > 5120)。为了更好地控制 LokiStack 中日志的访问,请使 cluster-admin 用户成为 cluster-admin 组的成员。如果 cluster-admin 组不存在,请创建它并将所需的用户添加到其中。
使用以下步骤为具有 cluster-admin 权限的用户创建新组。
流程
输入以下命令创建新组:
$ oc adm groups new cluster-admin
输入以下命令将所需的用户添加到
cluster-admin组中:$ oc adm groups add-users cluster-admin <username>
输入以下命令在组中添加
cluster-admin用户角色:$ oc adm policy add-cluster-role-to-group cluster-admin cluster-admin
3.2.4. 自定义 admin 组访问
如果您的部署有很多需要更广泛的用户,您可以使用 adminGroup 字段创建自定义组。属于 LokiStack CR 的 adminGroups 字段中指定的任何组的成员的用户被视为 admin。如果还被分配了 cluster-logging-application-view 角色,则管理员用户有权访问所有命名空间中的所有应用程序日志。
LokiStack CR 示例
apiVersion: loki.grafana.com/v1
kind: LokiStack
metadata:
name: logging-loki
namespace: openshift-logging
spec:
tenants:
mode: openshift-network 1
openshift:
adminGroups: 2
- cluster-admin
- custom-admin-group 3
3.2.5. Loki 部署大小
Loki 的大小使用 1x.<size> 格式,其中值 1x 是实例数量,<size> 指定性能功能。
对于部署大小,无法更改 1x 值。
表 3.2. Loki 大小
| 1x.demo | 1x.extra-small | 1x.small | 1x.medium | |
|---|---|---|---|---|
| 数据传输 | 只用于演示 | 100GB/day | 500GB/day | 2TB/day |
| 每秒查询数 (QPS) | 只用于演示 | 1-25 QPS at 200ms | 25-50 QPS at 200ms | 25-75 QPS at 200ms |
| 复制因子 | None | 2 | 2 | 2 |
| 总 CPU 请求 | None | 14 个 vCPU | 34 个 vCPU | 54 个 vCPU |
| 内存请求总数 | None | 31Gi | 67Gi | 139Gi |
| 磁盘请求总数 | 40Gi | 430Gi | 430Gi | 590Gi |
3.2.6. LokiStack ingestion 限制和健康警报
LokiStack 实例会根据配置的大小带有默认设置。您可以覆盖其中的一些设置,如 ingestion 和查询限制。如果您在 Console 插件中或 flowlogs-pipeline 日志中发现 Loki 错误,则可能需要更新它们。Web 控制台中的自动警报会在达到这些限制时通知您。
以下是配置的限制示例:
spec:
limits:
global:
ingestion:
ingestionBurstSize: 40
ingestionRate: 20
maxGlobalStreamsPerTenant: 25000
queries:
maxChunksPerQuery: 2000000
maxEntriesLimitPerQuery: 10000
maxQuerySeries: 3000有关这些设置的更多信息,请参阅 LokiStack API 参考。
3.2.7. 在网络可观察性中启用多租户
Network Observability Operator 中的多租户允许并将单独的用户访问或组访问限制为存储在 Loki 中的流。项目 admins 启用了访问权限。对某些命名空间具有有限访问权限的项目管理员只能访问这些命名空间的流。
前提条件
- 您至少安装了 Loki Operator 版本 5.7
- 您必须以项目管理员身份登录
流程
运行以下命令,授权
user1的读权限:$ oc adm policy add-cluster-role-to-user netobserv-reader user1
现在,数据仅限于允许的用户命名空间。例如,可以访问单个命名空间的用户可以查看此命名空间内部的所有流,以及从到这个命名空间流进入这个命名空间。项目管理员有权访问 OpenShift Container Platform 控制台中的 Administrator 视角,以访问 Network Flows Traffic 页面。
3.3. 安装 Network Observability Operator
您可以使用 OpenShift Container Platform Web 控制台 Operator Hub 安装 Network Observability Operator。安装 Operator 时,它提供 FlowCollector 自定义资源定义 (CRD)。在创建 FlowCollector 时,您可以在 web 控制台中设置规格。
Operator 的实际内存消耗取决于集群大小和部署的资源数量。可能需要调整内存消耗。如需更多信息,请参阅"重要流收集器配置注意事项"部分中的"网络 Observability 控制器管理器 pod 内存不足"。
先决条件
- 如果您选择使用 Loki,请安装 Loki Operator 版本 5.7+。
-
您必须具有
cluster-admin权限。 -
需要以下支持的架构之一:
amd64,ppc64le,arm64, 或s390x。 - Red Hat Enterprise Linux (RHEL) 9 支持的任何 CPU。
- 必须使用 OVN-Kubernetes 或 OpenShift SDN 配置为主网络插件,并可以选择使用二级接口,如 Multus 和 SR-IOV。
另外,这个安装示例使用 netobserv 命名空间,该命名空间在所有组件中使用。您可以选择使用不同的命名空间。
流程
- 在 OpenShift Container Platform Web 控制台中,点击 Operators → OperatorHub。
- 从 OperatorHub 中的可用 Operator 列表中选择 Network Observability Operator,然后点 Install。
-
选中
Enable Operator recommended cluster monitoring on this Namespace的复选框。 - 导航到 Operators → Installed Operators。在 Provided APIs for Network Observability 下, 选择 Flow Collector 链接。
进入 Flow Collector 选项卡,然后点 Create FlowCollector。在表单视图中进行以下选择:
-
spec.agent.ebpf.Sampling :指定流的抽样大小。较低的抽样大小会对资源利用率造成负面影响。如需更多信息,请参阅 "FlowCollector API 参考",
spec.agent.ebpf。 如果使用 Loki,请设置以下规格:
-
spec.loki.mode:将其设置为
LokiStack模式,它会自动设置 URL、TLS、集群角色和集群角色绑定,以及authToken值。或者,使用Manual模式对这些设置的配置进行更多控制。 -
spec.loki.lokistack.name :将其设置为您的
LokiStack资源的名称。在本文档中,我们使用loki。
-
spec.loki.mode:将其设置为
-
可选: 如果您在大型环境中,请考虑使用 Kafka 配置
FlowCollector以更具弹性且可扩展的方式转发数据。请参阅"Important Flow Collector 配置注意事项"部分的"使用 Kafka 存储配置流收集器资源"。 -
可选:在创建
FlowCollector前配置其他可选设置。例如,如果您选择不使用 Loki,您可以将导出流配置为 Kafka 或 IPFIX。请参阅"重要流收集器配置注意事项"一节中的"导出增强的网络流数据到 Kafka 和 IPFIX"。
-
spec.agent.ebpf.Sampling :指定流的抽样大小。较低的抽样大小会对资源利用率造成负面影响。如需更多信息,请参阅 "FlowCollector API 参考",
- 点 Create。
验证
要确认这一点,当您进入到 Observe 时,您应该看到选项中列出的 Network Traffic。
如果 OpenShift Container Platform 集群中没有应用程序流量,默认过滤器可能会显示"No results",这会导致没有视觉流。在过滤器选择旁边,选择 Clear all filters 来查看流。
3.4. 重要的流收集器配置注意事项
创建 FlowCollector 实例后,您可以重新配置它,但 pod 被终止并重新创建,这可能会具有破坏性。因此,您可以考虑在第一次创建 FlowCollector 时配置以下选项:
其他资源
有关流收集器规格和 Network Observability Operator 架构和资源使用的常规信息,请参阅以下资源:
3.5. 安装 Kafka (可选)
Kafka Operator 支持大规模环境。Kafka 提供高吞吐量和低延迟数据源,以便以更具弹性且可扩展的方式转发网络流数据。您可以从 Operator Hub 将 Kafka Operator 作为 Red Hat AMQ Streams 安装,就像 Loki Operator 和 Network Observability Operator 安装一样。请参阅"使用 Kafka 配置 FlowCollector 资源"以将 Kafka 配置为存储选项。
要卸载 Kafka,请参考与用来安装的方法对应的卸载过程。
3.6. 卸载 Network Observability Operator
您可以使用 OpenShift Container Platform Web 控制台 Operator Hub 来卸载 Network Observability Operator,在 Operators → Installed Operators 区域中工作。
流程
删除
FlowCollector自定义资源。- 点 Provided APIs 列中的 Network Observability Operator 旁边的 Flow Collector。
-
为集群点选项菜单
 ,然后选择 Delete FlowCollector。
,然后选择 Delete FlowCollector。
卸载 Network Observability Operator。
- 返回到 Operators → Installed Operators 区。
-
点 Network Observability Operator 旁边的选项菜单
并选择 Uninstall Operator。
-
Home → Projects 并选择
openshift-netobserv-operator - 进入到 Actions,再选择 Delete Project
删除
FlowCollector自定义资源定义 (CRD)。- 进入到 Administration → CustomResourceDefinitions。
-
查找 FlowCollector 并点选项菜单
。
选择 Delete CustomResourceDefinition。
重要如果已安装,Loki Operator 和 Kafka 会保留,需要被独立删除。另外,在一个对象存储中可能会有剩余的数据,以及持久性卷,这需要被删除。
第 4 章 OpenShift Container Platform 中的 Cluster Network Operator
Network Observability 是一个 OpenShift 操作器,它部署一个监控管道,以收集并增强网络流量流,由 Network Observability eBPF 代理生成。
4.1. 查看状态
Network Observability Operator 提供 Flow Collector API。创建 Flow Collector 资源时,它会部署 pod 和服务,以在 Loki 日志存储中创建和存储网络流,并在 OpenShift Container Platform Web 控制台中显示仪表板、指标和流。
流程
运行以下命令来查看
Flowcollector的状态:$ oc get flowcollector/cluster
输出示例
NAME AGENT SAMPLING (EBPF) DEPLOYMENT MODEL STATUS cluster EBPF 50 DIRECT Ready
输入以下命令检查在
netobserv命名空间中运行的 pod 状态:$ oc get pods -n netobserv
输出示例
NAME READY STATUS RESTARTS AGE flowlogs-pipeline-56hbp 1/1 Running 0 147m flowlogs-pipeline-9plvv 1/1 Running 0 147m flowlogs-pipeline-h5gkb 1/1 Running 0 147m flowlogs-pipeline-hh6kf 1/1 Running 0 147m flowlogs-pipeline-w7vv5 1/1 Running 0 147m netobserv-plugin-cdd7dc6c-j8ggp 1/1 Running 0 147m
flowlogs-pipeline pod 收集流,增强收集的流,然后将流发送到 Loki 存储。netobserv-plugin pod 为 OpenShift Container Platform 控制台创建一个视觉化插件。
输入以下命令检查在
netobserv-privileged命名空间中运行的 pod 状态:$ oc get pods -n netobserv-privileged
输出示例
NAME READY STATUS RESTARTS AGE netobserv-ebpf-agent-4lpp6 1/1 Running 0 151m netobserv-ebpf-agent-6gbrk 1/1 Running 0 151m netobserv-ebpf-agent-klpl9 1/1 Running 0 151m netobserv-ebpf-agent-vrcnf 1/1 Running 0 151m netobserv-ebpf-agent-xf5jh 1/1 Running 0 151m
netobserv-ebpf-agent pod 监控节点的网络接口以获取流并将其发送到 flowlogs-pipeline pod。
如果使用 Loki Operator,请输入以下命令检查在
openshift-operators-redhat命名空间中运行的 pod 状态:$ oc get pods -n openshift-operators-redhat
输出示例
NAME READY STATUS RESTARTS AGE loki-operator-controller-manager-5f6cff4f9d-jq25h 2/2 Running 0 18h lokistack-compactor-0 1/1 Running 0 18h lokistack-distributor-654f87c5bc-qhkhv 1/1 Running 0 18h lokistack-distributor-654f87c5bc-skxgm 1/1 Running 0 18h lokistack-gateway-796dc6ff7-c54gz 2/2 Running 0 18h lokistack-index-gateway-0 1/1 Running 0 18h lokistack-index-gateway-1 1/1 Running 0 18h lokistack-ingester-0 1/1 Running 0 18h lokistack-ingester-1 1/1 Running 0 18h lokistack-ingester-2 1/1 Running 0 18h lokistack-querier-66747dc666-6vh5x 1/1 Running 0 18h lokistack-querier-66747dc666-cjr45 1/1 Running 0 18h lokistack-querier-66747dc666-xh8rq 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-b2xfb 1/1 Running 0 18h lokistack-query-frontend-85c6db4fbd-jm94f 1/1 Running 0 18h
4.2. Network Observablity Operator 架构
Network Observability Operator 提供 FlowCollector API,它在安装时实例化,并配置为协调 eBPF 代理、flowlogs-pipeline 和 netobserv-plugin 组件。只支持每个集群有一个 FlowCollector。
eBPF 代理 在每个集群节点上运行,具有一些特权来收集网络流。flowlogs-pipeline 接收网络流数据,并使用 Kubernetes 标识符增强数据。如果使用 Loki,flowlogs-pipeline 会将流日志数据发送到 Loki 以存储和索引。netobserv-plugin,它是一个动态 OpenShift Container Platform Web 控制台插件,查询 Loki 来获取网络流数据。Cluster-admins 可以在 web 控制台中查看数据。
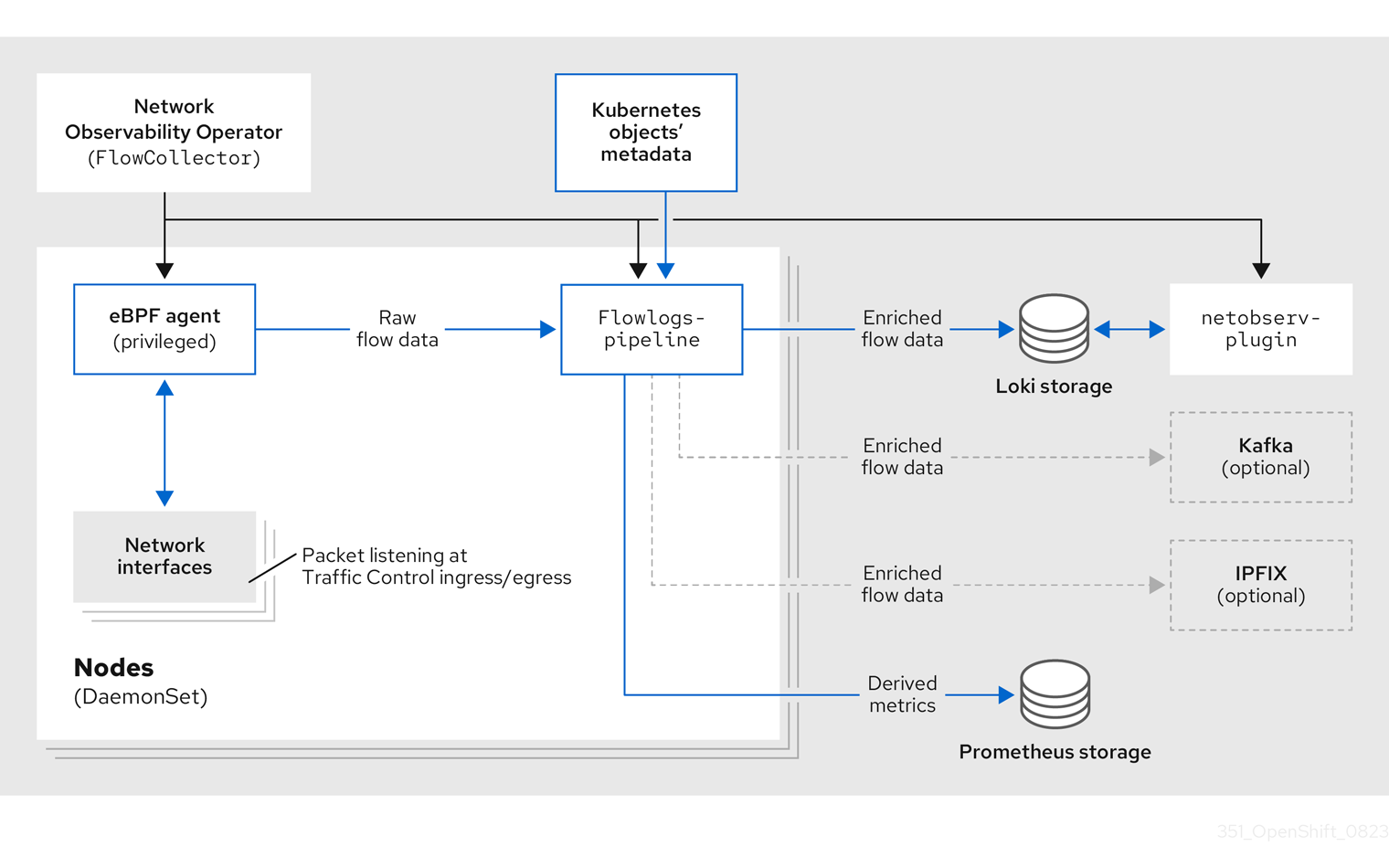
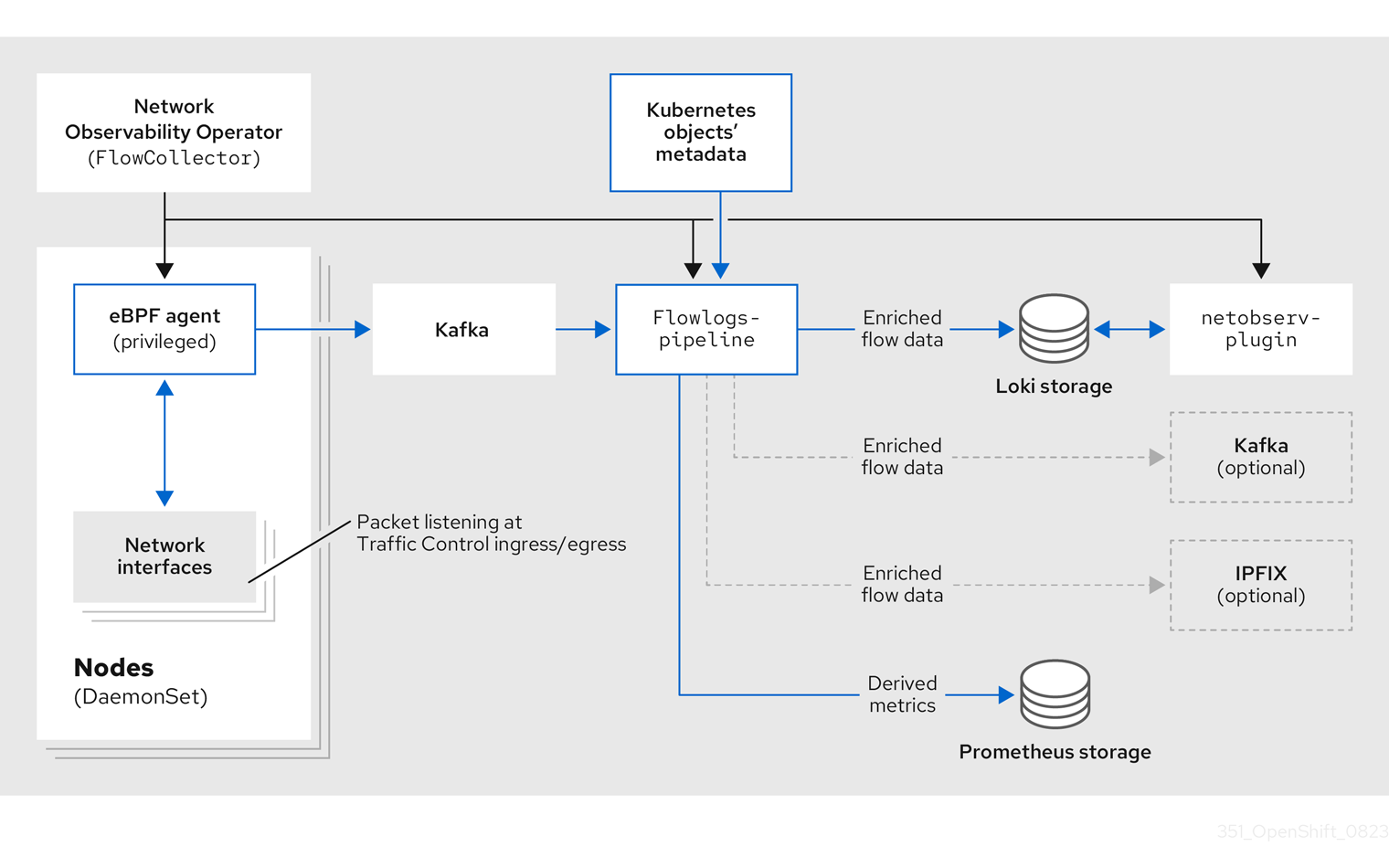
如果您使用 Kafka 选项,eBPF 代理将网络流数据发送到 Kafka,并且 flowlogs-pipeline 在发送到 Loki 前从 Kafka 主题读取,如下图所示。
4.3. 查看 Network Observability Operator 的状态和配置
您可以使用 oc describe 命令来检查 FlowCollector 的状态并查看其详情。
流程
运行以下命令,以查看 Network Observability Operator 的状态和配置:
$ oc describe flowcollector/cluster
第 5 章 配置 Network Observability Operator
您可以更新 Flow Collector API 资源,以配置 Network Observability Operator 及其受管组件。流收集器在安装过程中显式创建。由于此资源在集群范围内运行,因此只允许一个 FlowCollector,它必须被命名为 cluster。
5.1. 查看 FlowCollector 资源
您可以在 OpenShift Container Platform Web 控制台中直接查看和编辑 YAML。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题下,选择 Flow Collector。
-
选择 cluster,然后选择 YAML 选项卡。在这里,您可以修改
FlowCollector资源来配置 Network Observability operator。
以下示例显示了 OpenShift Container Platform Network Observability operator 的 FlowCollector 资源示例:
抽样 FlowCollector 资源
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: Direct
agent:
type: eBPF 1
ebpf:
sampling: 50 2
logLevel: info
privileged: false
resources:
requests:
memory: 50Mi
cpu: 100m
limits:
memory: 800Mi
processor: 3
logLevel: info
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 800Mi
logTypes: Flows
advanced:
conversationEndTimeout: 10s
conversationHeartbeatInterval: 30s
loki: 4
mode: LokiStack 5
consolePlugin:
register: true
logLevel: info
portNaming:
enable: true
portNames:
"3100": loki
quickFilters: 6
- name: Applications
filter:
src_namespace!: 'openshift-,netobserv'
dst_namespace!: 'openshift-,netobserv'
default: true
- name: Infrastructure
filter:
src_namespace: 'openshift-,netobserv'
dst_namespace: 'openshift-,netobserv'
- name: Pods network
filter:
src_kind: 'Pod'
dst_kind: 'Pod'
default: true
- name: Services network
filter:
dst_kind: 'Service'
- 1
- Agent 规格
spec.agent.type必须是EBPF。eBPF 是唯一的 OpenShift Container Platform 支持的选项。 - 2
- 您可以设置 Sampling 规格
spec.agent.ebpf.sampling,以管理资源。低抽样值可能会消耗大量计算、内存和存储资源。您可以通过指定一个抽样比率值来缓解这个问题。100 表示每 100 个流进行 1 个抽样。值 0 或 1 表示捕获所有流。数值越低,返回的流和派生指标的准确性会增加。默认情况下,eBPF 抽样设置为 50,因此每 50 个流抽样 1 个。请注意,更多抽样流也意味着需要更多存储。建议以默认值开始,并逐渐进行调整,以决定您的集群可以管理哪些设置。 - 3
- Processor 规格
spec.processor.可以设置为启用对话跟踪。启用后,可在 web 控制台中查询对话事件。spec.processor.logTypes的值为Flows。spec.processor.advanced的值为Conversations,EndedConversations, 或ALL。All对于存储的请求最高,EndedConversations对于存储的要求最低。 - 4
- Loki 规格
spec.loki指定 Loki 客户端。默认值与安装 Loki Operator 部分中提到的 Loki 安装路径匹配。如果您为 Loki 使用另一个安装方法,请为安装指定适当的客户端信息。 - 5
LokiStack模式会自动设置几个配置:querierUrl,ingesterUrl和statusUrl,tenantID,以及对应的 TLS 配置。创建集群角色和集群角色绑定用于读取和写入日志到 Loki。将authToken设置为Forward。您可以使用Manual模式手动设置它们。- 6
spec.quickFilters规范定义了在 web 控制台中显示的过滤器。Application过滤器键src_namespace和dst_namespace是负的 (!),因此Application过滤器显示不是来自、或目的地是openshift-或netobserv命名空间的所有流量。如需更多信息,请参阅配置快速过滤器。
其他资源
有关对话跟踪的更多信息,请参阅使用对话。
5.2. 使用 Kafka 配置流收集器资源
您可以将 FlowCollector 资源配置为使用 Kafka 进行高吞吐量和低延迟数据源。需要运行一个 Kafka 实例,并在该实例中创建专用于 OpenShift Container Platform Network Observability 的 Kafka 主题。如需更多信息,请参阅 AMQ Streams 的 Kafka 文档。
先决条件
- Kafka 已安装。红帽支持使用 AMQ Streams Operator 的 Kafka。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 Network Observability Operator 的 Provided APIs 标题下,选择 Flow Collector。
- 选择集群,然后点 YAML 选项卡。
-
修改 OpenShift Container Platform Network Observability Operator 的
FlowCollector资源以使用 Kafka,如下例所示:
FlowCollector 资源中的 Kafka 配置示例
apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: deploymentModel: Kafka 1 kafka: address: "kafka-cluster-kafka-bootstrap.netobserv" 2 topic: network-flows 3 tls: enable: false 4
- 1
- 将
spec.deploymentModel设置为Kafka,而不是Direct来启用 Kafka 部署模型。 - 2
spec.kafka.address是指 Kafka bootstrap 服务器地址。如果需要,您可以指定一个端口,如kafka-cluster-kafka-bootstrap.netobserv:9093,以便在端口 9093 上使用 TLS。- 3
spec.kafka.topic应与 Kafka 中创建的主题名称匹配。- 4
spec.kafka.tls可用于加密所有与带有 TLS 或 mTLS 的 Kafka 的通信。启用后,Kafka CA 证书必须作为 ConfigMap 或 Secret 提供,两者都位于部署了flowlogs-pipeline处理器组件的命名空间中(默认为netobserv)以及 eBPF 代理被部署的位置(默认为netobserv-privileged)。它必须通过spec.kafka.tls.caCert引用。使用 mTLS 时,客户端 secret 还必须在这些命名空间中可用(它们也可以使用 AMQ Streams User Operator 生成并使用spec.kafka.tls.userCert)。
5.3. 导出增强的网络流数据
您可以同时将网络流发送到 Kafka、IPFIX 或这两者。任何支持 Kafka 或 IPFIX 输入的处理器或存储(如 Splunk、Elasticsearch 或 Fluentd)都可以使用增强的网络流数据。
先决条件
-
您的 Kafka 或 IPFIX 收集器端点可从 Network Observability
flowlogs-pipelinepod 中提供。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题下,选择 Flow Collector。
- 选择 cluster,然后选择 YAML 选项卡。
编辑
FlowCollector以配置spec.exporters,如下所示:apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: exporters: - type: Kafka 1 kafka: address: "kafka-cluster-kafka-bootstrap.netobserv" topic: netobserv-flows-export 2 tls: enable: false 3 - type: IPFIX 4 ipfix: targetHost: "ipfix-collector.ipfix.svc.cluster.local" targetPort: 4739 transport: tcp or udp 5
- 2
- Network Observability Operator 将所有流导出到配置的 Kafka 主题。
- 3
- 您可以加密所有使用 SSL/TLS 或 mTLS 的 Kafka 的通信。启用后,Kafka CA 证书必须作为 ConfigMap 或 Secret 提供,两者都位于部署了
flowlogs-pipeline处理器组件的命名空间中(默认为 netobserv)。它必须使用spec.exporters.tls.caCert引用。使用 mTLS 时,客户端 secret 还必须在这些命名空间中可用(它们也可以使用 AMQ Streams User Operator 生成并使用spec.exporters.tls.userCert引用)。 - 1 4
- 您可以将流导出到 IPFIX,而不是或与将流导出到 Kafka。
- 5
- 您可以选择指定传输。默认值为
tcp,但您也可以指定udp。
- 配置后,网络流数据可以以 JSON 格式发送到可用输出。如需更多信息,请参阅 网络流格式参考。
其他资源
有关指定流格式的更多信息,请参阅网络流格式参考。
5.4. 更新流收集器资源
作为在 OpenShift Container Platform Web 控制台中编辑 YAML 的替代方法,您可以通过修补 flowcollector 自定义资源 (CR) 来配置规格,如 eBPF 抽样:
流程
运行以下命令来修补
flowcollectorCR 并更新spec.agent.ebpf.sampling值:$ oc patch flowcollector cluster --type=json -p "[{"op": "replace", "path": "/spec/agent/ebpf/sampling", "value": <new value>}] -n netobserv"
5.5. 配置快速过滤器
您可以修改 FlowCollector 资源中的过滤器。可以使用双引号对值进行完全匹配。否则,会对文本值进行部分匹配。感叹号(!)字符放置在键的末尾,表示负效果。有关修改 YAML 的更多信息,请参阅示例 FlowCollector 资源。
匹配类型"all"或"any of"的过滤器是用户可从查询选项进行修改的 UI 设置。它不是此资源配置的一部分。
以下是所有可用过滤器键的列表:
表 5.1. 过滤键
| Universal* | Source | 目的地 | 描述 |
|---|---|---|---|
| namespace |
|
| 过滤与特定命名空间相关的流量。 |
| name |
|
| 过滤与给定叶资源名称相关的流量,如特定 pod、服务或节点(用于 host-network 流量)。 |
| kind |
|
| 过滤与给定资源类型相关的流量。资源类型包括叶资源 (Pod、Service 或 Node) 或所有者资源(Deployment 和 StatefulSet)。 |
| owner_name |
|
| 过滤与给定资源所有者相关的流量;即工作负载或一组 pod。例如,它可以是 Deployment 名称、StatefulSet 名称等。 |
| resource |
|
|
过滤与特定资源相关的流量,它们通过其规范名称表示,以唯一标识它。规范表示法是 |
| address |
|
| 过滤与 IP 地址相关的流量。支持 IPv4 和 IPv6。还支持 CIDR 范围。 |
| mac |
|
| 过滤与 MAC 地址相关的流量。 |
| port |
|
| 过滤与特定端口相关的流量。 |
| host_address |
|
| 过滤与运行 pod 的主机 IP 地址相关的流量。 |
| protocol | N/A | N/A | 过滤与协议相关的流量,如 TCP 或 UDP。 |
-
任何源或目的地的通用密钥过滤器。例如,过滤
name: 'my-pod'表示从my-pod和所有流量到my-pod的所有流量,无论使用的匹配类型是什么,无论是 匹配所有 还是 匹配任何。
5.6. 为 SR-IOV 接口流量配置监控
要使用单根 I/O 虚拟化(SR-IOV)设备从集群收集流量,您必须将 FlowCollector spec.agent.ebpf.privileged 字段设置为 true。然后,eBPF 代理除主机网络命名空间外监控其他网络命名空间,这些命名空间会被默认监控。当创建具有虚拟功能(VF)接口的 pod 时,会创建一个新的网络命名空间。指定 SRIOVNetwork 策略 IPAM 配置后,VF 接口从主机网络命名空间迁移到 pod 网络命名空间。
先决条件
- 使用 SR-IOV 设备访问 OpenShift Container Platform 集群。
-
SRIOVNetwork自定义资源(CR)spec.ipam配置必须使用接口列表或其他插件范围内的 IP 地址设置。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题下,选择 Flow Collector。
- 选择 cluster,然后选择 YAML 选项卡。
-
配置
FlowCollector自定义资源。示例配置示例如下:
为 SR-IOV 监控配置 FlowCollector
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
namespace: netobserv
deploymentModel: Direct
agent:
type: eBPF
ebpf:
privileged: true 1
- 1
spec.agent.ebpf.privileged字段值必须设置为true以启用 SR-IOV 监控。
其他资源
有关创建 SriovNetwork 自定义资源的更多信息,请参阅使用 CNI VRF 插件创建额外的 SR-IOV 网络附加。
5.7. 资源管理和性能注意事项
Network Observability 所需的资源量取决于集群的大小以及集群要存储可观察数据的要求。要管理集群的资源并设置性能标准,请考虑配置以下设置。配置这些设置可能会满足您的最佳设置和可观察性需求。
以下设置可帮助您管理 outset 中的资源和性能:
- eBPF Sampling
-
您可以设置 Sampling 规格
spec.agent.ebpf.sampling,以管理资源。较小的抽样值可能会消耗大量计算、内存和存储资源。您可以通过指定一个抽样比率值来缓解这个问题。100表示每 100 个流进行 1 个抽样。值0或1表示捕获所有流。较小的值会导致返回的流和派生指标的准确性增加。默认情况下,eBPF 抽样设置为 50,因此每 50 个流抽样 1 个。请注意,更多抽样流也意味着需要更多存储。考虑以默认值开始,并逐步优化,以确定您的集群可以管理哪些设置。 - 限制或排除接口
-
通过为
spec.agent.ebpf.interfaces和spec.agent.ebpf.excludeInterfaces设置值来减少观察到的流量。默认情况下,代理获取系统中的所有接口,但excludeInterfaces和lo(本地接口)中列出的接口除外。请注意,接口名称可能会因使用的 Container Network Interface (CNI) 而异。
以下设置可用于在 Network Observability 运行后对性能进行微调:
- 资源要求和限制
-
使用
spec.agent.ebpf.resources和spec.processor.resources规格,将资源要求和限制调整为集群中预期的负载和内存用量。800MB 的默认限制可能足以满足大多数中型集群。 - 缓存最大流超时
-
使用 eBPF 代理的
spec.agent.ebpf.cacheMaxFlows和spec.agent.ebpf.cacheActiveTimeout规格来控制代理报告的频率。较大的值会导致代理生成较少的流量,与较低 CPU 负载相关联。但是,较大的值会导致内存消耗稍有更高的,并可能会在流集合中生成更多延迟。
5.7.1. 资源注意事项
下表概述了具有特定工作负载的集群的资源注意事项示例。
表中概述的示例演示了为特定工作负载量身定制的场景。每个示例仅作为基准,可以进行调整以适应您的工作负载需求。
表 5.2. 资源建议
| Extra small (10 个节点) | Small (25 个节点) | Medium (65 个节点) [2] | Large (120 个节点) [2] | |
|---|---|---|---|---|
| Worker 节点 vCPU 和内存 | 4 个 vCPU| 16GiB 内存 [1] | 16 个 vCPU| 64GiB 内存 [1] | 16 个 vCPU| 64GiB 内存 [1] | 16 个 vCPU| 64GiB Mem [1] |
| LokiStack 大小 |
|
|
|
|
| Network Observability 控制器内存限值 | 400Mi (默认) | 400Mi (默认) | 400Mi (默认) | 400Mi (默认) |
| eBPF 抽样率 | 50 (默认) | 50 (默认) | 50 (默认) | 50 (默认) |
| eBPF 内存限值 | 800Mi (默认) | 800Mi (默认) | 800Mi (默认) | 1600Mi |
| FLP 内存限制 | 800Mi (默认) | 800Mi (默认) | 800Mi (默认) | 800Mi (默认) |
| FLP Kafka 分区 | N/A | 48 | 48 | 48 |
| Kafka 消费者副本 | N/A | 24 | 24 | 24 |
| Kafka 代理 | N/A | 3 (默认) | 3 (默认) | 3 (默认) |
- 使用 AWS M6i 实例测试。
-
除了此 worker 及其控制器外,还会测试 3 infra 节点 (size
M6i.12xlarge) 和 1 个工作负载节点 (sizeM6i.8xlarge)。
第 6 章 Network Policy
作为具有 admin 角色的用户,您可以为 netobserv 命名空间创建一个网络策略,以保护对 Network Observability Operator 的入站访问。
6.1. 为 Network Observability 创建网络策略
您可能需要创建一个网络策略来保护到 netobserv 命名空间的入口流量。在 Web 控制台中,您可以使用表单视图创建网络策略。
流程
- 进入到 Networking → NetworkPolicies。
-
从 Project 下拉菜单中选择
netobserv项目。 -
为策略命名。在本例中,策略名为
allow-ingress。 - 点 Add ingress rule 三次来创建三个入站规则。
指定以下内容:
对第一个 Ingress 规则设置以下规格:
- 从 Add allowed source 下拉菜单中选择 Allow pods。
为第二个 Ingress 规则设置以下规格 :
- 从 Add allowed source 下拉菜单中选择 Allow pods。
- 点 + Add namespace selector。
-
添加标签
kubernetes.io/metadata.name,以及选择器openshift-console。
为第三个 Ingress 规则设置以下规格 :
- 从 Add allowed source 下拉菜单中选择 Allow pods。
- 点 + Add namespace selector。
-
添加标签
kubernetes.io/metadata.name,和选择器openshift-monitoring。
验证
- 进入到 Observe → Network Traffic。
- 查看 Traffic Flows 选项卡,或任何标签页,以验证是否显示数据。
- 进入到 Observe → Dashboards。在 NetObserv/Health 选择中,验证流是否嵌套并发送到 Loki,这在第一个图形中表示。
6.2. 网络策略示例
以下注解了 netobserv 命名空间的 NetworkPolicy 对象示例:
网络策略示例
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-ingress
namespace: netobserv
spec:
podSelector: {} 1
ingress:
- from:
- podSelector: {} 2
namespaceSelector: 3
matchLabels:
kubernetes.io/metadata.name: openshift-console
- podSelector: {}
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: openshift-monitoring
policyTypes:
- Ingress
status: {}
其他资源
第 7 章 观察网络流量
作为管理员,您可以观察 OpenShift Container Platform 控制台中的网络流量,以了解故障排除和分析的详细故障排除和分析。此功能帮助您从不同的流量流的图形表示获得见解。观察网络流量有几种可用的视图。
7.1. 从 Overview 视图观察网络流量
Overview 视图显示集群中网络流量流的整体聚合指标。作为管理员,您可以使用可用的显示选项监控统计信息。
7.1.1. 使用 Overview 视图
作为管理员,您可以进入到 Overview 视图来查看流速率统计的图形表示。
流程
- 进入到 Observe → Network Traffic。
- 在 Network Traffic 页面中,点 Overview 选项卡。
您可以通过点菜单图标来配置每个流速率数据的范围。
7.1.2. 为 Overview 视图配置高级选项
您可以使用高级选项自定义图形视图。要访问高级选项,点 Show advanced options。您可以使用 Display options 下拉菜单在图形中配置详情。可用的选项如下:
- Scope :选择查看网络流量流在其中进行的组件。您可以将范围设置为 Node,Namespace,Owner,Zones,Cluster 或 Resource。Owner 是一个资源聚合。Resource 可以是一个 pod、服务、节点(主机网络流量),或未知 IP 地址。默认值为 Namespace。
- Truncate labels:从下拉列表中选择标签所需的宽度。默认值为 M。
7.1.2.1. 管理面板和显示
您可以选择显示所需的面板,对它们进行重新排序,并专注于特定的面板。要添加或删除面板,请点 Manage panels。
默认情况下会显示以下面板:
- 顶级 X 平均字节率
- 顶级 X 字节率堆栈总计
在 Manage panels 中可以添加其他面板:
- 顶级 X 平均数据包率
- 顶级 X 数据包速率堆栈总计
通过 查询选项,您可以选择是否显示 Top 5、Top 10 或 Top 15 率。
7.1.3. 数据包丢弃跟踪
您可以在 Overview 视图中使用数据包丢失来配置网络流记录的图形表示。通过使用 eBPF 追踪点 hook,您可以获得对 TCP、UDP、SCTP、ICMPv4 和 ICMPv6 协议的数据包丢弃的宝贵见解,这可能会导致以下操作:
- 身份识别:指定发生数据包丢弃的确切位置和网络路径。确定特定设备、接口或路由是否更易于丢弃。
- 根本原因分析:检查 eBPF 程序收集的数据,以了解数据包丢弃的原因。例如,它们是拥塞、缓冲区问题还是特定的网络事件的结果?
- 性能优化:通过数据包丢弃的清晰了解,您可以采取步骤来优化网络性能,如调整缓冲区大小、重新配置路由路径或实施服务质量(QoS)测量。
启用数据包丢弃跟踪后,您可以在 Overview 中默认看到以下面板:
- 顶级 X 数据包丢弃状态的堆栈为总计
- 顶级 X 数据包丢弃会导致堆栈总计
- 顶级 X 平均丢弃的数据包率
- 顶级 X 丢弃的数据包速率堆栈为总计
可以在管理面板中添加其他数据包丢弃面板 :
- 顶级 X 平均丢弃的字节率
- 顶级 X 丢弃的字节速率堆栈为总计
7.1.3.1. 数据包丢弃的类型
Network Observability 检测到两种类型的数据包丢弃:host drops 和 OVS drops。主机丢弃的带有 SKB_DROP 前缀,OVS drops 带有 OVS_DROP 前缀。丢弃流在 流量流 表的侧面面板中显示,以及指向每个丢弃类型的描述的链接。主机丢弃原因示例如下:
-
SKB_DROP_REASON_NO_SOCKET:由于缺少套接字而丢弃数据包。 -
SKB_DROP_REASON_TCP_CSUM:由于 TCP checksum 错误而丢弃的数据包。
OVS 丢弃原因示例如下:
-
OVS_DROP_LAST_ACTION:OVS 数据包因为隐式丢弃操作而丢弃,例如因为配置了网络策略。 -
OVS_DROP_IP_TTL:由于 IP TTL 已过期的 OVS 数据包丢弃。
有关启用和使用数据包丢弃跟踪的更多信息,请参阅本节的附加资源。
7.1.4. DNS 跟踪
您可以在 Overview 视图中配置对网络流的域名系统(DNS)跟踪的图形表示。使用带有扩展 Berkeley Packet Filter (eBPF)追踪点 hook 的 DNS 跟踪可以满足各种目的:
- 网络监控 :深入了解 DNS 查询和响应,帮助网络管理员识别异常模式、潜在瓶颈或性能问题。
- 安全分析:拒绝 DNS 活动,如恶意软件使用的域名生成算法(DGA),或者识别可能指示安全漏洞的未授权 DNS 解析。
- 故障排除:通过追踪 DNS 解析步骤、跟踪延迟和识别错误配置来调试与 DNS 相关的问题。
默认情况下,当启用 DNS 跟踪时,您可以在 Overview 中的 donut 或 line chart 中看到以下非空指标:
- 顶级 X DNS 响应代码
- 顶级 X 平均 DNS 延迟数
- 顶部 X 90th percentile DNS 延迟
可以在管理面板中添加其他 DNS 跟踪面板:
- 底部 X 最小 DNS 延迟
- 顶级 X 最大 DNS 延迟
- 顶级 X 99th percentile DNS latencies
IPv4 和 IPv6 UDP 和 TCP 协议支持此功能。
有关启用和使用此视图的更多信息,请参阅本节中的附加资源。
7.1.5. 往返时间 (RTT)
您可以使用 TCP 握手 Round-Trip Time (RTT) 来分析网络流。您可以使用 fentry/tcp_rcv_ established eBPF hookpoint 捕获的 RTT 来从 TCP 套接字中读取 SRTT,以帮助:
- 网络监控 :深入了解 TCP 握手,帮助网络管理员识别异常模式、潜在瓶颈或性能问题。
- 故障排除:通过跟踪延迟和识别错误配置来调试与 TCP 相关的问题。
默认情况下,当启用 RTT 时,您可以看到 Overview 中代表的以下 TCP 握手 RTT 指标:
- 顶级 X 90th percentile TCP 握手 Round Trip 时间
- 顶级 X 平均 TCP 握手 Round Trip 时间
- 底部 X 最小 TCP 握手 Round Trip 时间
在管理面板中可以添加其他 RTT 面板:
- 顶级 X 最大 TCP 握手 Round Trip 时间,总时间
- 总的 X 99th percentile TCP 握手 Round Trip Time
有关启用和使用此视图的更多信息,请参阅本节中的附加资源。
其他资源
7.2. 从流量流视图观察网络流量
流量流 视图显示网络流的数据以及表中的流量数量。作为管理员,您可以使用流量流表监控应用程序间的流量数量。
7.2.1. 使用流量流视图
作为管理员,您可以进入 流量流 表来查看网络流信息。
流程
- 进入到 Observe → Network Traffic。
- 在 Network Traffic 页面中,点 流量流 选项卡。
您可以点击每行来获取对应的流信息。
7.2.2. 为流量流视图配置高级选项
您可以使用 Show advanced options 自定义和导出视图。您可以使用 Display options 下拉菜单设置行大小。默认值为 Normal。
7.2.2.1. 管理列
您可以选择显示所需的列,并对它们进行重新排序。若要管理列,可点 Manage 列。
7.2.2.2. 导出流量流数据
您可以从流量流视图导出数据。
流程
- 点 Export data。
- 在弹出窗口中,您可以选择 Export all data 复选框,以导出所有数据,然后清除复选框以选择要导出的必填字段。
- 单击 Export。
7.2.3. 使用对话跟踪
作为管理员,您可以对属于同一对话的网络流进行分组。对话被定义为一组由 IP 地址、端口和协议标识的对等点,从而产生唯一的 Conversation Id。您可以在 web 控制台中查询对话事件。这些事件在 web 控制台中表示,如下所示:
- Conversation start :连接启动或 TCP 标记被截获时发生此事件
-
Conversation tick:此事件在连接处于活跃状态时根据
FlowCollectorspec.processor.conversationHeartbeatInterval参数中定义的每个指定间隔发生。 -
Conversation end :当达到
FlowCollectorspec.processor.conversationEndTimeout参数或 TCP 标志被截获时,会发生此事件。 - Flow :这是在指定间隔内的网络流量流。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题下,选择 Flow Collector。
- 选择 cluster,然后选择 YAML 选项卡。
配置
FlowCollector自定义资源,以便根据您的观察需求设置spec.processor.logTypes,conversationEndTimeout, 和conversationHeartbeatInterval参数。示例配置示例如下:配置
FlowCollector以对话跟踪apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: logTypes: Flows 1 advanced: conversationEndTimeout: 10s 2 conversationHeartbeatInterval: 30s 3
- 1
- 当
logTypes设置为Flows时,只会导出 Flow 事件。如果将值设为All,则会在 Network Traffic 页面中导出并看到对话和流事件。要只专注于对话事件,您可以指定Conversations,它会导出 Conversation start, Conversation tick and Conversation end 事件;或指定EndedConversations,它只导出 Conversation end 事件。All对于存储的请求最高,EndedConversations对于存储的要求最低。 - 2
- Conversation end 事件表示达到了
conversationEndTimeout,或 TCP 标志被截获。 - 3
- Conversation tick 事件表示当网络连接活跃时,在
FlowCollectorconversationHeartbeatInterval参数中定义的每个指定间隔。
注意如果您更新了
logType选项,则之前选择中的流不会从控制台插件中清除。例如,如果您最初将logType设置为Conversations,持续到 10 AM,然后移到EndedConversations,控制台插件会显示 10 AM 之前的所有对话事件,且仅在 10 AM 后终止对话。-
刷新 Traffic flows 标签页中的 Network Traffic。通知请注意,有两个新列: Event/Type 和 Conversation Id。当
Flow是所选查询选项时,所有 Event/Type 字段都是 Flow。 - 选择 Query Options 并选择 Log Type,Conversation。现在,Event/Type 会显示所有所需的对话事件。
- 接下来,您可以过滤侧面板中的 Conversation 和 Flow 日志类型选项的特定 对话 ID 或切换。
7.2.4. 使用数据包丢弃
当网络流数据的一个或多个数据包无法访问其目的地时,会发生数据包丢失。您可以通过将 FlowCollector 编辑到以下 YAML 示例中的规格来跟踪这些丢弃。
启用此功能时,CPU 和内存用量会增加。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题下,选择 Flow Collector。
- 选择 集群,然后选择 YAML 选项卡。
为数据包丢弃配置
FlowCollector自定义资源,例如:FlowCollector配置示例apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Direct agent: type: eBPF ebpf: features: - PacketDrop 1 privileged: true 2
验证
刷新 Network Traffic 页面时,Overview、Traffic Flow 和 Topology 视图会显示有关数据包丢弃的新信息:
- 在 Manage 面板中选择新选择,以选择要在 Overview 中显示的数据包丢弃的图形视觉化。
在 Manage 列中选择新选择,以选择要在流量流表中显示哪些数据包丢弃信息。
-
在 流量流视图 中,您还可以展开侧面板来查看有关数据包丢弃的更多信息。主机丢弃的带有
SKB_DROP前缀,OVS drops 带有OVS_DROP前缀。
-
在 流量流视图 中,您还可以展开侧面板来查看有关数据包丢弃的更多信息。主机丢弃的带有
- 在 Topology 视图中,会显示红色的行,其中出现 drops。
7.2.5. 使用 DNS 跟踪
使用 DNS 跟踪,您可以监控网络、进行安全分析并对 DNS 问题进行故障排除。您可以通过将 FlowCollector 编辑到以下 YAML 示例中的规格来跟踪 DNS。
启用这个功能时,在 eBPF 代理中观察到 CPU 和内存用量。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 Network Observability 的 Provided APIs 标题下,选择 Flow Collector。
- 选择 cluster,然后选择 YAML 选项卡。
配置
FlowCollector自定义资源。示例配置示例如下:为 DNS 跟踪配置
FlowCollectorapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Direct agent: type: eBPF ebpf: features: - DNSTracking 1 sampling: 1 2刷新 Network Traffic 页面时,您可以选择在 Overview 和 Traffic Flow 视图和可以应用的新过滤器中查看新的 DNS 表示。
- 在 Manage 面板中选择新的 DNS 选项,在 Overview 中显示图形视觉化和 DNS 指标。
- 在 Manage 列中选择新选择,将 DNS 列添加到 流量流视图 中。
- 过滤特定 DNS 指标,如 DNS Id、DNS Error DNS Latency 和 DNS Response Code,并在侧面面板中查看更多信息。默认情况下会显示 DNS Latency 和 DNS Response Code 列。
TCP 握手数据包没有 DNS 标头。在 DNS Latency、ID 和 响应代码 值 "n/a" 的流量流中会显示没有 DNS 标头的 TCP 协议流。您可以过滤掉流数据,以只查看使用通用过滤器 "DNSError" 等于 "0" 的 DNS 标头的流。
7.2.6. 使用 RTT 追踪
您可以通过将 FlowCollector 编辑到以下 YAML 示例中的规格来跟踪 RTT。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题中,选择 Flow Collector。
- 选择 集群,然后选择 YAML 选项卡。
为 RTT 追踪配置
FlowCollector自定义资源,例如:FlowCollector配置示例apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: namespace: netobserv deploymentModel: Direct agent: type: eBPF ebpf: features: - FlowRTT 1- 1
- 您可以通过列出
spec.agent.ebpf.features规格列表中的FlowRTT参数来启动追踪 RTT 网络流。
验证
刷新 Network Traffic 页面时,Overview、Traffic Flow 和 Topology 视图会显示有关 RTT 的新信息:
- 在 Overview 中,在 Manage 面板中选择新选择,以选择要显示的 RTT 的图形视觉化。
- 在 Traffic flows 表中,可以看到 Flow RTT 列,您可以在 Manage 列中管理显示。
在 流量流视图 中,您还可以展开侧面板来查看有关 RTT 的更多信息。
过滤示例
- 点 Common 过滤 → Protocol。
- 根据 TCP、Ingress 方向过滤网络流数据,并查找大于 10,000,000 纳秒(10ms)的 FlowRTT 值。
- 删除 Protocol 过滤。
- 在 Common 过滤器中过滤大于 0 的 Flow RTT 值。
- 在 Topology 视图中,点 Display 选项下拉菜单。然后点 edge labels 下拉列表中的 RTT。
7.2.6.1. 使用直方图
您可以点 Show histogram 来显示工具栏视图,以使用栏图的形式可视化流历史记录。histogram 显示一段时间内的日志数量。您可以选择直方图的一部分在下面的工具栏中过滤网络流数据。
7.2.7. 使用可用区
您可以配置 FlowCollector 以收集有关集群可用区的信息。这可让您使用应用到节点的 topology.kubernetes.io/zone 标签值增强网络流数据。
流程
- 在 Web 控制台中,进入 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题下,选择 Flow Collector。
- 选择 cluster,然后选择 YAML 选项卡。
配置
FlowCollector自定义资源,使spec.processor.addZone参数设置为true。示例配置示例如下:为可用区集合配置
FlowCollectorapiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: # ... processor: addZone: true # ...
验证
刷新 Network Traffic 页面时,Overview、Traffic Flow 和 Topology 视图会显示有关可用区的新信息:
- 在 Overview 选项卡中,您可以将 Zones 视为可用 Scope。
- 在 Network Traffic → Traffic flows 中,Zone 可以在 SrcK8S_Zone 和 DstK8S_Zone 字段下查看。
- 在 Topology 视图中,您可以将 Zones 设置为 Scope 或 Group。
7.3. 从 Topology 视图中观察网络流量
Topology 视图提供了网络流和流量数量的图形表示。作为管理员,您可以使用 Topology 视图监控应用程序间的流量数据。
7.3.1. 使用 Topology 视图
作为管理员,您可以进入到 Topology 视图来查看组件的详情和指标。
流程
- 进入到 Observe → Network Traffic。
- 在 Network Traffic 页面中,点 Topology 选项卡。
您可以点 Topology 中的每个组件来查看组件的详情和指标。
7.3.2. 为 Topology 视图配置高级选项
您可以使用 Show advanced options 自定义和导出视图。高级选项视图具有以下功能:
- Find in view: 要在视图中搜索所需组件。
Display options :要配置以下选项:
- Edge labels :将指定的测量显示为边缘标签。默认值为显示 Average rate(以 Bytes 为单位)。
- Scope :选择网络流量流之间的组件范围。默认值为 Namespace。
- 组 :通过对组件进行分组来充分了解所有权。默认值为 None。
- Layout:要选择图形表示的布局。默认值为 ColaNoForce。
- 显示 :要选择需要显示的详细信息。默认检查所有选项。可以选项为:Edges, Edges label, 和 Badges。
- Truncate labels:从下拉列表中选择标签所需的宽度。默认值为 M。
- 折叠组 :要展开或折叠组。默认会扩展组。如果 Groups 的值为 None,这个选项会被禁用。
7.3.2.1. 导出拓扑视图
要导出视图,点 Export topology view。该视图以 PNG 格式下载。
7.4. 过滤网络流量
默认情况下,Network Traffic 页面根据 FlowCollector 实例中配置的默认过滤器显示集群中的流量流数据。您可以通过更改 preset 过滤器,使用过滤器选项观察所需的数据。
- 查询选项
您可以使用 Query Options 来优化搜索结果,如下所示:
- 日志类型 :可用选项 Conversation 和 Flows 提供了按日志类型查询流的能力,如流日志、新对话、完成对话和心跳,这是长期对话的定期记录。对话是同一对等点之间的流聚合。
-
重复流 :可以从多个接口报告流,并从源和目标节点报告,使其多次出现在数据中。通过选择此查询选项,您可以选择显示重复的流。重复的流具有相同的源和目的地(包括端口),也具有相同的协议,但
Interface和Direction字段除外。默认情况下会隐藏重复项。使用下拉列表的 Common 部分中的 Direction 过滤器在入口和出口流量间切换。 - Match filters:您可以确定高级过滤器中选择的不同过滤器参数之间的关系。可用的选项包括 Match all 和 Match any。Match all 提供与所有值都匹配的结果,而 Match any 则提供与输入的任何值匹配的结果。默认值为 Match all。
丢弃过滤器 :您可以使用以下查询选项查看不同的丢弃数据包级别:
- 完全丢弃 显示带有完全丢弃的数据包的流记录。
- 包含丢弃 显示包含丢弃但可以发送的流记录。
- 没有丢弃 显示包含已发送数据包的记录。
- All 显示上述所有记录。
- Limit:内部后端查询的数据限制。根据匹配和过滤器设置,流量流数据的数量显示在指定的限制中。
- 快速过滤器
-
Quick 过滤器 下拉菜单中的默认值在
FlowCollector配置中定义。您可从控制台修改选项。 - 高级过滤器
- 您可以通过从下拉列表中选择要过滤的参数来设置高级过滤器、Common、Source 或 Destination。流数据根据选择进行过滤。要启用或禁用应用的过滤器,您可以点过滤器选项下面列出的应用过滤器。
您可以切换
![]() One way
One way ![]() 和
和
![]() Back and forth 过滤。
Back and forth 过滤。
![]() 单向过滤只根据过滤器选择显示 Source 和 Destination 流量。您可以使用 Swap 来更改 Source 和 Destination 流量的方向视图。
单向过滤只根据过滤器选择显示 Source 和 Destination 流量。您可以使用 Swap 来更改 Source 和 Destination 流量的方向视图。
![]()
![]() Back and forth 过滤器包括带有 Source 和 Destination 过滤器的返回流量。网络流量的方向流在流量流表中的 Direction 列中显示为
Back and forth 过滤器包括带有 Source 和 Destination 过滤器的返回流量。网络流量的方向流在流量流表中的 Direction 列中显示为 Ingress`or `Egress(对于不同节点间的流量)和 'Inner'(对于单一节点内的流量)。
您可以点 Reset default 删除现有过滤器,并应用 FlowCollector 配置中定义的过滤器。
要了解指定文本值的规则,请点了解更多。
另外,您也可以访问 Namespaces, Services, Routes, Nodes, and Workloads 页中的 Network Traffic 标签页,它们提供了相关部分的聚合过滤数据。
第 8 章 使用带有仪表板和警报的指标
Network Observability Operator 使用 flowlogs-pipeline 从流日志生成指标。您可以通过设置自定义警报和查看仪表板来使用这些指标。
8.1. 查看 Network Observability 指标仪表板
在 OpenShift Container Platform 控制台中的 Overview 选项卡中,您可以查看集群中网络流量流的整体聚合指标。您可以选择按节点、命名空间、所有者、pod 和服务显示信息。您还可以使用过滤器和显示选项来进一步优化指标。
流程
- 在 Web 控制台 Observe → Dashboards 中,选择 Netobserv 仪表板。
查看以下类别中的网络流量指标,每个指标都有每个节点、命名空间、源和目标的子集:
- 字节率
- 数据包丢弃
- DNS
- RTT
- 选择 Netobserv/Health 仪表板。
在以下类别中查看有关 Operator 健康的指标,每个类别都有每个节点的子集、命名空间、源和目的地。
- 流
- 流开销
- 流率
- 代理
- 处理器
- Operator
基础架构和应用程序指标显示在命名空间和工作负载的 split-view 中。
8.2. 网络 Observability 指标
flowlogs-pipeline 生成的指标可在 FlowCollector 自定义资源的 spec.processor.metrics.includeList 中进行配置,以添加或删除指标。
您还可以使用 Prometheus 规则中的 includeList 指标创建警报,如"创建警报"所示。
当在 Prometheus 中查找这些指标时,如通过 Observe → Metrics 或定义警报,所有指标名称都有 'netobserv_ 前缀。例如,'netobserv_namespace_flows_total。可用的指标名称如下。
8.2.1. includeList 指标名称
默认情况下启用带有星号 * 的名称。
-
namespace_egress_bytes_total -
namespace_egress_packets_total -
namespace_ingress_bytes_total -
namespace_ingress_packets_total -
namespace_flows_total* -
node_egress_bytes_total -
node_egress_packets_total -
node_ingress_bytes_total* -
node_ingress_packets_total -
node_flows_total -
workload_egress_bytes_total -
workload_egress_packets_total -
workload_ingress_bytes_total* -
workload_ingress_packets_total -
workload_flows_total
8.2.1.1. PacketDrop 指标名称
当在 spec.agent.ebpf.features (具有 privileged 模式)中启用 PacketDrop 功能时,可以使用以下额外的指标:
-
namespace_drop_bytes_total -
namespace_drop_packets_total* -
node_drop_bytes_total -
node_drop_packets_total -
workload_drop_bytes_total -
workload_drop_packets_total
8.2.1.2. DNS 指标名称
当在 spec.agent.ebpf.features 中启用了 DNSTracking 功能时,可以使用以下额外的指标:
-
namespace_dns_latency_seconds* -
node_dns_latency_seconds -
workload_dns_latency_seconds
8.2.1.3. FlowRTT 指标名称
当在 spec.agent.ebpf.features 中启用 FlowRTT 功能时,可以使用以下额外指标:
-
namespace_rtt_seconds* -
node_rtt_seconds -
workload_rtt_seconds
8.3. 创建警报
您可以为 Netobserv 仪表板指标创建自定义警报规则,以便在满足某些定义条件时触发警报。
先决条件
- 您可以使用具有 cluster-admin 角色的用户访问集群,或者具有所有项目的查看权限。
- 已安装 Network Observability Operator。
流程
- 点导入图标 + 创建 YAML 文件。
向 YAML 文件添加警报规则配置。在以下 YAML 示例中,当集群入口流量达到每个目标工作负载的指定阈值 10 MBps 时,会为警报创建一个警报。
apiVersion: monitoring.openshift.io/v1 kind: AlertingRule metadata: name: netobserv-alerts namespace: openshift-monitoring spec: groups: - name: NetObservAlerts rules: - alert: NetObservIncomingBandwidth annotations: message: |- {{ $labels.job }}: incoming traffic exceeding 10 MBps for 30s on {{ $labels.DstK8S_OwnerType }} {{ $labels.DstK8S_OwnerName }} ({{ $labels.DstK8S_Namespace }}). summary: "High incoming traffic." expr: sum(rate(netobserv_workload_ingress_bytes_total {SrcK8S_Namespace="openshift-ingress"}[1m])) by (job, DstK8S_Namespace, DstK8S_OwnerName, DstK8S_OwnerType) > 10000000 1 for: 30s labels: severity: warning- 1
- 在
spec.processor.metrics.includeList中默认启用netobserv_workload_ingress_bytes_total指标。
- 点 Create 将配置文件应用到集群。
其他资源
- 有关创建您可以在仪表板中看到的警报的更多信息,请参阅为用户定义的项目创建警报规则。
第 9 章 监控 Network Observability Operator
您可以使用 Web 控制台监控与 Network Observability Operator 健康相关的警报。
9.1. 查看健康信息
您可从 web 控制台的 Dashboards 页面中访问 Network Observability Operator 健康和资源使用的指标。当触发警报时,您定向到仪表板的健康警报横幅可能会出现在 Network Traffic 和 Home 页面中。在以下情况下生成警报:
-
如果
flowlogs-pipeline工作负载因为 Loki 错误而丢弃流,如已经达到 Loki ingestion 速率限制,则NetObservLokiError警报发生。 -
如果在一个时间段内没有流,则会发出
NetObservNoFlows警报。
您还可以按以下类别查看 Operator 健康状况的指标:
- 流
- 流开销
- 每个源和目标节点的最大流率
- 每个源和目标命名空间的最大流率
- 每个源和目标工作负载的最大流率
- 代理
- 处理器
- Operator
先决条件
- 已安装 Network Observability Operator。
-
您可以使用具有
cluster-admin角色或所有项目的查看权限的用户访问集群。
流程
- 从 web 控制台中的 Administrator 视角,进入到 Observe → Dashboards。
- 从 Dashboards 下拉菜单中选择 Netobserv/Health。
- 查看页面中显示的 Operator 健康状况的指标。
9.1.1. 禁用健康警报
您可以通过编辑 FlowCollector 资源来选择不使用健康警报:
- 在 Web 控制台中,进入到 Operators → Installed Operators。
- 在 NetObserv Operator 的 Provided APIs 标题下,选择 Flow Collector。
- 选择 cluster,然后选择 YAML 选项卡。
添加
spec.processor.metrics.disableAlerts来禁用健康警报,如下例所示:apiVersion: flows.netobserv.io/v1beta2 kind: FlowCollector metadata: name: cluster spec: processor: metrics: disableAlerts: [NetObservLokiError, NetObservNoFlows] 1- 1
- 您可以指定一个或多个包含要禁用的警报类型的列表。
9.2. 为 NetObserv 仪表板创建 Loki 速率限制警报
您可以为 Netobserv 仪表板指标创建自定义警报规则,以便在达到 Loki 速率限制时触发警报。
先决条件
- 您可以使用具有 cluster-admin 角色的用户访问集群,或者具有所有项目的查看权限。
- 已安装 Network Observability Operator。
流程
- 点导入图标 + 创建 YAML 文件。
向 YAML 文件添加警报规则配置。在以下 YAML 示例中,当达到 Loki 速率限制时,会创建一个警报:
apiVersion: monitoring.openshift.io/v1 kind: AlertingRule metadata: name: loki-alerts namespace: openshift-monitoring spec: groups: - name: LokiRateLimitAlerts rules: - alert: LokiTenantRateLimit annotations: message: |- {{ $labels.job }} {{ $labels.route }} is experiencing 429 errors. summary: "At any number of requests are responded with the rate limit error code." expr: sum(irate(loki_request_duration_seconds_count{status_code="429"}[1m])) by (job, namespace, route) / sum(irate(loki_request_duration_seconds_count[1m])) by (job, namespace, route) * 100 > 0 for: 10s labels: severity: warning- 点 Create 将配置文件应用到集群。
其他资源
- 有关创建您可以在仪表板中看到的警报的更多信息,请参阅为用户定义的项目创建警报规则。
第 10 章 FlowCollector 配置参数
FlowCollector 是网络流集合 API 的 Schema,它试用并配置底层部署。
10.1. FlowCollector API 规格
- 描述
-
FlowCollector是网络流集合 API 的 schema,它试用并配置底层部署。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| APIVersion 定义对象的这个表示法的版本化的 schema。服务器应该将识别的模式转换为最新的内部值,并可拒绝未识别的值。更多信息: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources |
|
|
| kind 是一个字符串值,代表此对象所代表的 REST 资源。服务器可以从客户端向其提交请求的端点推断。无法更新。采用驼峰拼写法 (CamelCase)。更多信息: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds |
|
|
| 标准对象元数据。更多信息: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata |
|
|
|
定义 FlowCollector 资源所需状态。 |
10.1.1. .metadata
- 描述
- 标准对象元数据。更多信息: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
- 类型
-
object
10.1.2. .spec
- 描述
-
定义 FlowCollector 资源所需状态。
*:在本文档中声明的"不支持"或"弃用"的功能代表红帽不正式支持这些功能。例如,这些功能可能由社区提供,并在没有正式维护协议的情况下被接受。产品维护人员可能只为这些功能提供一些支持。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 流提取的代理配置。 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Kafka 配置,允许使用 Kafka 作为流集合管道的一部分。当 |
|
|
|
|
|
|
| 部署 Network Observability pod 的命名空间。 |
|
|
|
|
10.1.3. .spec.agent
- 描述
- 流提取的代理配置。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.4. .spec.agent.ebpf
- 描述
-
ebpf描述了当spec.agent.type设置为eBPF时,与基于 eBPF 的流报告程序相关的设置。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
要启用的额外功能列表。它们都默认禁用。启用其他功能可能会对性能有影响。可能的值有: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
eBPF Agent 容器的特权模式。当忽略或设置为 |
|
|
|
|
|
|
| 流报告器的抽样率。100 表示发送 100 个流中的一个。0 或 1 表示所有流都是抽样的。 |
10.1.5. .spec.agent.ebpf.advanced
- 描述
-
advanced允许设置 eBPF 代理的内部配置的一些方面。本节主要用于调试和精细的性能优化,如GOGC和GOMAXPROCS环境变量。在设置这些值时,您需要自己考虑相关的风险。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
10.1.6. .spec.agent.ebpf.resources
- 描述
-
resources是此容器所需的计算资源。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 限制描述了允许的最大计算资源量。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests 描述了所需的最少计算资源。如果容器省略了 Requests,则默认为 Limits (如果明确指定),否则默认为实现定义的值。请求不能超过限值。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
10.1.7. .spec.agent.ipfix
- 描述
-
ipfix[deprecated (*)] - 当spec.agent.type设置为 IPFIX 时,描述了与基于IPFIX的流报告程序相关的设置。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.8. .spec.agent.ipfix.clusterNetworkOperator
- 描述
-
clusterNetworkOperator定义与 OpenShift Container Platform Cluster Network Operator 相关的设置(如果可用)。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 部署配置映射的命名空间。 |
10.1.9. .spec.agent.ipfix.ovnKubernetes
- 描述
-
ovnKubernetes定义 OVN-Kubernetes CNI 的设置(如果可用)。在没有 OpenShift Container Platform 的情况下使用 OVN 的 IPFIX 导出时使用此配置。使用 OpenShift Container Platform 时,请参阅clusterNetworkOperator属性。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 部署 OVN-Kubernetes pod 的命名空间。 |
10.1.10. .spec.consolePlugin
- 描述
-
ConsolePlugin定义与 OpenShift Container Platform 控制台插件相关的设置(如果可用)。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
Pod 横向自动扩展的 |
|
|
|
启用 console 插件部署。 |
|
|
|
|
|
|
|
控制台插件后端的 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.11. .spec.consolePlugin.advanced
- 描述
-
advanced允许设置控制台插件的内部配置的一些方面。本节主要用于调试和精细的性能优化,如GOGC和GOMAXPROCS环境变量。在设置这些值时,您需要自己考虑相关的风险。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.12. .spec.consolePlugin.autoscaler
- 描述
-
Pod 横向自动扩展的
autoscaler规格来为插件部署设置。请参阅 HorizontalPodAutoscaler 文档(autoscaling/v2)。 - 类型
-
object
10.1.13. .spec.consolePlugin.portNaming
- 描述
-
portNaming定义端口到服务名称转换的配置 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 启用 console 插件端口到服务名称转换 |
|
|
|
|
10.1.14. .spec.consolePlugin.quickFilters
- 描述
-
quickFilters为 Console 插件配置快速过滤器预设置 - 类型
-
数组
10.1.15. .spec.consolePlugin.quickFilters[]
- 描述
-
QuickFilter为控制台的快速过滤器定义预设置配置 - 类型
-
对象 - 必填
-
filter -
name
-
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 过滤器的名称,在控制台中显示 |
10.1.16. .spec.consolePlugin.resources
- 描述
-
resources,根据此容器所需的计算资源。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 限制描述了允许的最大计算资源量。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests 描述了所需的最少计算资源。如果容器省略了 Requests,则默认为 Limits (如果明确指定),否则默认为实现定义的值。请求不能超过限值。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
10.1.17. .spec.exporters
- 描述
-
exporters为自定义消耗或存储定义了额外的可选导出器。 - 类型
-
数组
10.1.18. .spec.exporters[]
- 描述
-
FlowCollectorExporter定义了一个额外的导出器来发送增强的流 - 类型
-
对象 - 必填
-
type
-
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| IPFIX 配置,如 IP 地址和端口,以将增强的 IPFIX 流发送到。 |
|
|
| Kafka 配置(如地址和主题)将增强的流发送到。 |
|
|
|
|
10.1.19. .spec.exporters[].ipfix
- 描述
- IPFIX 配置,如 IP 地址和端口,以将增强的 IPFIX 流发送到。
- 类型
-
对象 - 必填
-
targetHost -
targetPort
-
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| IPFIX 外部接收器的地址 |
|
|
| IPFIX 外部接收器的端口 |
|
|
|
用于 IPFIX 连接的传输协议( |
10.1.20. .spec.exporters[].kafka
- 描述
- Kafka 配置(如地址和主题)将增强的流发送到。
- 类型
-
对象 - 必填
-
address -
topic
-
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| Kafka 服务器的地址 |
|
|
| SASL 身份验证配置。[Unsupported packagemanifests]。 |
|
|
| TLS 客户端配置。在使用 TLS 时,验证地址是否与用于 TLS 的 Kafka 端口匹配,通常为 9093。 |
|
|
| 要使用的 Kafka 主题。它必须存在。Network Observability 不会创建它。 |
10.1.21. .spec.exporters[].kafka.sasl
- 描述
- SASL 身份验证配置。[Unsupported packagemanifests]。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 对包含客户端 ID 的 secret 或配置映射的引用 |
|
|
| 对包含客户端 secret 的 secret 或配置映射的引用 |
|
|
|
使用的 SASL 身份验证类型,如果没有使用 SASL,则为 |
10.1.22. .spec.exporters[].kafka.sasl.clientIDReference
- 描述
- 对包含客户端 ID 的 secret 或配置映射的引用
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 配置映射或 secret 中的文件名 |
|
|
| 包含该文件的配置映射或 secret 的名称 |
|
|
| 包含该文件的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
| 文件引用的 type: "configmap" 或 "secret" |
10.1.23. .spec.exporters[].kafka.sasl.clientSecretReference
- 描述
- 对包含客户端 secret 的 secret 或配置映射的引用
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 配置映射或 secret 中的文件名 |
|
|
| 包含该文件的配置映射或 secret 的名称 |
|
|
| 包含该文件的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
| 文件引用的 type: "configmap" 或 "secret" |
10.1.24. .spec.exporters[].kafka.tls
- 描述
- TLS 客户端配置。在使用 TLS 时,验证地址是否与用于 TLS 的 Kafka 端口匹配,通常为 9093。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
| 启用 TLS |
|
|
|
|
|
|
|
|
10.1.25. .spec.exporters[].kafka.tls.caCert
- 描述
-
caCert定义证书颁发机构的证书引用 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.26. .spec.exporters[].kafka.tls.userCert
- 描述
-
userCert定义用户证书引用,用于 mTLS (您可以在使用单向 TLS 时忽略它) - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.27. .spec.kafka
- 描述
-
Kafka 配置,允许使用 Kafka 作为流集合管道的一部分。当
spec.deploymentModel是Kafka时可用。 - 类型
-
对象 - 必填
-
address -
topic
-
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| Kafka 服务器的地址 |
|
|
| SASL 身份验证配置。[Unsupported packagemanifests]。 |
|
|
| TLS 客户端配置。在使用 TLS 时,验证地址是否与用于 TLS 的 Kafka 端口匹配,通常为 9093。 |
|
|
| 要使用的 Kafka 主题。它必须存在。Network Observability 不会创建它。 |
10.1.28. .spec.kafka.sasl
- 描述
- SASL 身份验证配置。[Unsupported packagemanifests]。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 对包含客户端 ID 的 secret 或配置映射的引用 |
|
|
| 对包含客户端 secret 的 secret 或配置映射的引用 |
|
|
|
使用的 SASL 身份验证类型,如果没有使用 SASL,则为 |
10.1.29. .spec.kafka.sasl.clientIDReference
- 描述
- 对包含客户端 ID 的 secret 或配置映射的引用
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 配置映射或 secret 中的文件名 |
|
|
| 包含该文件的配置映射或 secret 的名称 |
|
|
| 包含该文件的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
| 文件引用的 type: "configmap" 或 "secret" |
10.1.30. .spec.kafka.sasl.clientSecretReference
- 描述
- 对包含客户端 secret 的 secret 或配置映射的引用
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 配置映射或 secret 中的文件名 |
|
|
| 包含该文件的配置映射或 secret 的名称 |
|
|
| 包含该文件的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
| 文件引用的 type: "configmap" 或 "secret" |
10.1.31. .spec.kafka.tls
- 描述
- TLS 客户端配置。在使用 TLS 时,验证地址是否与用于 TLS 的 Kafka 端口匹配,通常为 9093。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
| 启用 TLS |
|
|
|
|
|
|
|
|
10.1.32. .spec.kafka.tls.caCert
- 描述
-
caCert定义证书颁发机构的证书引用 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.33. .spec.kafka.tls.userCert
- 描述
-
userCert定义用户证书引用,用于 mTLS (您可以在使用单向 TLS 时忽略它) - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.34. .spec.loki
- 描述
-
loki,流存储、客户端设置。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
将 |
|
|
|
|
|
|
|
|
|
|
|
对于 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.35. .spec.loki.advanced
- 描述
-
advanced允许设置 Loki 客户端的内部配置的一些方面。本节主要用于调试和精细的性能优化。 - 类型
-
object
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.1.36. .spec.loki.lokiStack
- 描述
-
LokiStack模式的 Loki 配置。这对简单的 loki-operator 配置非常有用。对于其他模式,它会被忽略。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 要使用的现有 LokiStack 资源的名称。 |
|
|
|
此 |
10.1.37. .spec.loki.manual
- 描述
-
Manual模式的 Loki 配置。这是最灵活的配置。对于其他模式,它会被忽略。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Loki 状态 URL 的 TLS 客户端配置。 |
|
|
|
|
|
|
|
|
|
|
| Loki URL 的 TLS 客户端配置。 |
10.1.38. .spec.loki.manual.statusTls
- 描述
- Loki 状态 URL 的 TLS 客户端配置。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
| 启用 TLS |
|
|
|
|
|
|
|
|
10.1.39. .spec.loki.manual.statusTls.caCert
- 描述
-
caCert定义证书颁发机构的证书引用 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.40. .spec.loki.manual.statusTls.userCert
- 描述
-
userCert定义用户证书引用,用于 mTLS (您可以在使用单向 TLS 时忽略它) - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.41. .spec.loki.manual.tls
- 描述
- Loki URL 的 TLS 客户端配置。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
| 启用 TLS |
|
|
|
|
|
|
|
|
10.1.42. .spec.loki.manual.tls.caCert
- 描述
-
caCert定义证书颁发机构的证书引用 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.43. .spec.loki.manual.tls.userCert
- 描述
-
userCert定义用户证书引用,用于 mTLS (您可以在使用单向 TLS 时忽略它) - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.44. .spec.loki.microservices
- 描述
-
对于
Microservices模式的 Loki 配置。当使用微服务部署模式(https://grafana.com/docs/loki/latest/fundamentals/architecture/deployment-modes/#microservices-mode)安装 Loki 时使用这个选项。对于其他模式,它会被忽略。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Loki URL 的 TLS 客户端配置。 |
10.1.45. .spec.loki.microservices.tls
- 描述
- Loki URL 的 TLS 客户端配置。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
| 启用 TLS |
|
|
|
|
|
|
|
|
10.1.46. .spec.loki.microservices.tls.caCert
- 描述
-
caCert定义证书颁发机构的证书引用 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.47. .spec.loki.microservices.tls.userCert
- 描述
-
userCert定义用户证书引用,用于 mTLS (您可以在使用单向 TLS 时忽略它) - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.48. .spec.loki.monolithic
- 描述
-
Monolithic模式的 Loki 配置。当使用单体部署模式 (https://grafana.com/docs/loki/latest/fundamentals/architecture/deployment-modes/#monolithic-mode) 安装 Loki 时使用这个选项。对于其他模式,它会被忽略。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
| Loki URL 的 TLS 客户端配置。 |
|
|
|
|
10.1.49. .spec.loki.monolithic.tls
- 描述
- Loki URL 的 TLS 客户端配置。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
| 启用 TLS |
|
|
|
|
|
|
|
|
10.1.50. .spec.loki.monolithic.tls.caCert
- 描述
-
caCert定义证书颁发机构的证书引用 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.51. .spec.loki.monolithic.tls.userCert
- 描述
-
userCert定义用户证书引用,用于 mTLS (您可以在使用单向 TLS 时忽略它) - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.52. .spec.processor
- 描述
-
processor定义从代理接收流的组件设置,增强它们,生成指标,并将它们转发到 Loki 持久层和/或任何可用的导出器。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
处理器运行时的 |
|
|
|
|
|
|
|
|
|
|
|
将 |
|
|
|
|
10.1.53. .spec.processor.advanced
- 描述
-
advanced允许设置流处理器的内部配置。本节主要用于调试和精细的性能优化,如GOGC和GOMAXPROCS环境变量。在设置这些值时,您需要自己考虑相关的风险。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 流收集器(主机端口)的端口。按照惯例,一些值会被禁止。它必须大于 1024,且不能是 4500、4789 和 6081。 |
|
|
|
|
10.1.54. .spec.processor.kafkaConsumerAutoscaler
- 描述
-
kafkaConsumerAutoscaler是 Pod 横向自动扩展的 spec,用于flowlogs-pipeline-transformer,它使用 Kafka 信息。当 Kafka 被禁用时,会忽略此设置。请参阅 HorizontalPodAutoscaler 文档(autoscaling/v2)。 - 类型
-
object
10.1.55. .spec.processor.metrics
- 描述
-
Metrics定义有关指标的处理器配置 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| Prometheus scraper 的指标服务器端点配置 |
10.1.56. .spec.processor.metrics.server
- 描述
- Prometheus scraper 的指标服务器端点配置
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| prometheus HTTP 端口 |
|
|
| TLS 配置。 |
10.1.57. .spec.processor.metrics.server.tls
- 描述
- TLS 配置。
- 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
当 |
|
|
|
当将 |
|
|
|
选择 TLS 配置类型: |
10.1.58. .spec.processor.metrics.server.tls.provided
- 描述
-
当
type设置为Provided时的 TLS 配置。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
| 包含证书的配置映射或 Secret 的名称 |
|
|
| 包含证书的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
|
证书引用的类型: |
10.1.59. .spec.processor.metrics.server.tls.providedCaFile
- 描述
-
当将
type设置为Provided时,对 CA 文件的引用。 - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 配置映射或 secret 中的文件名 |
|
|
| 包含该文件的配置映射或 secret 的名称 |
|
|
| 包含该文件的配置映射或 secret 的命名空间。如果省略,则默认为使用与部署 Network Observability 相同的命名空间。如果命名空间不同,则复制配置映射或 secret,以便可以根据需要挂载它。 |
|
|
| 文件引用的 type: "configmap" 或 "secret" |
10.1.60. .spec.processor.resources
- 描述
-
resources是此容器所需的计算资源。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ - 类型
-
对象
| 属性 | 类型 | 描述 |
|---|---|---|
|
|
| 限制描述了允许的最大计算资源量。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
|
|
| Requests 描述了所需的最少计算资源。如果容器省略了 Requests,则默认为 Limits (如果明确指定),否则默认为实现定义的值。请求不能超过限值。更多信息: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ |
第 11 章 网络流格式参考
这些是网络流格式的规格,在内部和将流导出到 Kafka 时使用。
11.1. 网络流格式参考
这是网络流格式的规格。在配置了 Kafka 导出器时,使用这种格式,用于 Prometheus 指标标签,以及 Loki 存储的内部。
"Filter ID"列显示定义 Quick Filters 时使用的相关名称(请参阅 FlowCollector 规格中的 spec.consolePlugin.quickFilters )。
当直接查询 Loki 时,"Loki label"列很有用:需要使用 流选择器 来选择标签字段。
| Name | 类型 | 描述 | 过滤 ID | Loki 标签 |
|---|---|---|---|---|
|
| number | 字节数 | 不适用 | 否 |
|
| number | 从 DNS tracker ebpf hook 功能返回的错误数 |
| 否 |
|
| number | DNS 记录的 DNS 标记 | 不适用 | 否 |
|
| string | 解析的 DNS 标头 RCODE 名称 |
| 否 |
|
| number | DNS 记录 ID |
| 否 |
|
| number | DNS 请求和响应之间的时间(以毫秒为单位) |
| 否 |
|
| number | 差异化服务代码点 (DSCP) 值 |
| 否 |
|
| string | 目标 IP 地址 (ipv4 或 ipv6) |
| 否 |
|
| string | 目的地节点 IP |
| 否 |
|
| string | 目标节点名称 |
| 否 |
|
| string | 目标 Kubernetes 对象的名称,如 Pod 名称、服务名称或节点名称。 |
| 否 |
|
| string | 目标命名空间 |
| 是 |
|
| string | 目标所有者的名称,如 Deployment 名称、StatefulSet 名称等。 |
| 是 |
|
| string | 目标所有者的类型,如 Deployment、StatefulSet 等。 |
| 否 |
|
| string | 目标 Kubernetes 对象的类型,如 Pod、Service 或 Node。 |
| 是 |
|
| string | 目标可用区 |
| 是 |
|
| string | 目标 MAC 地址 |
| 否 |
|
| number | 目的地端口 |
| 否 |
|
| 布尔值 | 指明此流是否也从同一主机上的另一个接口捕获 | 不适用 | 是 |
|
| number |
在流中包括唯一 TCP 标志的逻辑 OR 组合,根据 RFC-9293,带有额外的自定义标志来代表每个数据包的组合: | 不适用 | 否 |
|
| number |
来自节点观察点的流方向可以是: |
| 是 |
|
| number | ICMP 代码 |
| 否 |
|
| number | ICMP 类型 |
| 否 |
|
| number |
从网络接口观察点进行流方向。可以是: | 不适用 | 否 |
|
| string | 网络接口 |
| 否 |
|
| string | 集群名称或标识符 |
| 是 |
|
| string | 流层: 'app' 或 'infra' |
| 否 |
|
| number | 数据包数 | 不适用 | 否 |
|
| number | 内核丢弃的字节数 | 不适用 | 否 |
|
| string | 最新丢弃原因 |
| 否 |
|
| number | 最后丢弃的数据包上的 TCP 标志 | 不适用 | 否 |
|
| string | 最后丢弃的数据包上的 TCP 状态 |
| 否 |
|
| number | 内核丢弃的数据包数 | 不适用 | 否 |
|
| number | L4 协议 |
| 否 |
|
| string | 源 IP 地址 (ipv4 或 ipv6) |
| 否 |
|
| string | 源节点 IP |
| 否 |
|
| string | 源节点名称 |
| 否 |
|
| string | 源 Kubernetes 对象的名称,如 Pod 名称、服务名称或节点名称。 |
| 否 |
|
| string | 源命名空间 |
| 是 |
|
| string | 源所有者的名称,如 Deployment 名称、StatefulSet 名称等。 |
| 是 |
|
| string | 源所有者的类型,如 Deployment、StatefulSet 等。 |
| 否 |
|
| string | 源 Kubernetes 对象的类型,如 Pod、Service 或 Node。 |
| 是 |
|
| string | 源可用区 |
| 是 |
|
| string | 源 MAC 地址 |
| 否 |
|
| number | 源端口 |
| 否 |
|
| number | 此流的结束时间戳,以毫秒为单位 | 不适用 | 否 |
|
| number | TCP Smoothed Round Trip Time (SRTT),单位为纳秒 |
| 否 |
|
| number | 开始此流的时间戳,以毫秒为单位 | 不适用 | 否 |
|
| number | 由流被流收集器接收并处理时的时间戳,以秒为单位 | 不适用 | 否 |
|
| string | 在对话跟踪中,对话标识符 |
| 否 |
|
| string | 记录类型:'flowLog' 用于常规流日志,或 'newConnection', 'heartbeat', 'endConnection' 用于对话跟踪 |
| 是 |
第 12 章 Network Observability 故障排除
为了协助对 Network Observability 问题进行故障排除,可以执行一些故障排除操作。
12.1. 使用 must-gather 工具
您可以使用 must-gather 工具来收集有关 Network Observability Operator 资源和集群范围资源的信息,如 pod 日志、FlowCollector 和 Webhook 配置。
流程
- 进入到要存储 must-gather 数据的目录。
运行以下命令来收集集群范围的 must-gather 资源:
$ oc adm must-gather --image-stream=openshift/must-gather \ --image=quay.io/netobserv/must-gather
12.2. 在 OpenShift Container Platform 控制台中配置网络流量菜单条目
当网络流量菜单条目没有在 OpenShift Container Platform 控制台的 Observe 菜单中列出时,在 OpenShift Container Platform 控制台中手动配置网络流量菜单条目。
先决条件
- 已安装 OpenShift Container Platform 版本 4.10 或更高版本。
流程
运行以下命令,检查
spec.consolePlugin.register字段是否已设置为true:$ oc -n netobserv get flowcollector cluster -o yaml
输出示例
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: false可选:通过手动编辑 Console Operator 配置来添加
netobserv-plugin插件:$ oc edit console.operator.openshift.io cluster
输出示例
... spec: plugins: - netobserv-plugin ...
可选:运行以下命令,将
spec.consolePlugin.register字段设置为true:$ oc -n netobserv edit flowcollector cluster -o yaml
输出示例
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: consolePlugin: register: true运行以下命令,确保控制台 pod 的状态为
running:$ oc get pods -n openshift-console -l app=console
运行以下命令重启控制台 pod:
$ oc delete pods -n openshift-console -l app=console
- 清除浏览器缓存和历史记录。
运行以下命令,检查 Network Observability 插件 pod 的状态:
$ oc get pods -n netobserv -l app=netobserv-plugin
输出示例
NAME READY STATUS RESTARTS AGE netobserv-plugin-68c7bbb9bb-b69q6 1/1 Running 0 21s
运行以下命令,检查 Network Observability 插件 pod 的日志:
$ oc logs -n netobserv -l app=netobserv-plugin
输出示例
time="2022-12-13T12:06:49Z" level=info msg="Starting netobserv-console-plugin [build version: , build date: 2022-10-21 15:15] at log level info" module=main time="2022-12-13T12:06:49Z" level=info msg="listening on https://:9001" module=server
12.3. 安装 Kafka 后 Flowlogs-Pipeline 不会消耗网络流
如果您首先使用 deploymentModel: KAFKA 部署了流收集器,然后部署 Kafka,则流收集器可能无法正确连接到 Kafka。手动重启 flow-pipeline pod,其中 Flowlogs-pipeline 不使用 Kafka 中的网络流。
流程
运行以下命令,删除 flow-pipeline pod 来重启它们:
$ oc delete pods -n netobserv -l app=flowlogs-pipeline-transformer
12.4. 无法从 br-int 和 br-ex 接口查看网络流
br-ex' 和 br-int 是 OSI 第 2 层操作的虚拟网桥设备。eBPF 代理分别在 IP 和 TCP 级别(第 3 和 4 层)中工作。当网络流量由物理主机或虚拟 pod 接口处理时,您可以预期 eBPF 代理捕获通过 br-ex 和 br-int 的网络流量。如果您限制 eBPF 代理网络接口只附加到 br-ex 和 br-int,则不会看到任何网络流。
手动删除限制网络接口到 br-int 和 br-ex 的 interfaces 或 excludeInterfaces 中的部分。
流程
删除
interfaces: [ 'br-int', 'br-ex' ]字段。这允许代理从所有接口获取信息。或者,您可以指定 Layer-3 接口,例如eth0。运行以下命令:$ oc edit -n netobserv flowcollector.yaml -o yaml
输出示例
apiVersion: flows.netobserv.io/v1alpha1 kind: FlowCollector metadata: name: cluster spec: agent: type: EBPF ebpf: interfaces: [ 'br-int', 'br-ex' ] 1- 1
- 指定网络接口。
12.5. Network Observability 控制器管理器 pod 内存不足
您可以通过编辑 Subscription 对象中的 spec.config.resources.limits.memory 规格来为 Network Observability Operator 增加内存限值。
流程
- 在 Web 控制台中,进入到 Operators → Installed Operators
- 点 Network Observability,然后选择 Subscription。
在 Actions 菜单中,点 Edit Subscription。
另外,您可以运行以下命令来使用 CLI 为
Subscription对象打开 YAML 配置:$ oc edit subscription netobserv-operator -n openshift-netobserv-operator
编辑
Subscription对象以添加config.resources.limits.memory规格,并将值设置为考虑您的内存要求。有关资源注意事项的更多信息,请参阅附加资源:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: netobserv-operator namespace: openshift-netobserv-operator spec: channel: stable config: resources: limits: memory: 800Mi 1 requests: cpu: 100m memory: 100Mi installPlanApproval: Automatic name: netobserv-operator source: redhat-operators sourceNamespace: openshift-marketplace startingCSV: <network_observability_operator_latest_version> 2
12.6. 对 Loki 运行自定义查询
若要进行故障排除,可以对 Loki 运行自定义查询。有两种方法示例,您可以通过将 <api_token> 替换为您自己的 <api_token> 来根据您的需要进行调整。
这些示例为 Network Observability Operator 和 Loki 部署使用 netobserv 命名空间。另外,示例假定 LokiStack 名为 loki。您可以通过调整示例(特别是 -n netobserv 或 loki-gateway URL)来使用不同的命名空间和命名。
先决条件
- 安装 Loki Operator 以用于 Network Observability Operator
流程
要获取所有可用标签,请运行以下命令:
$ oc exec deployment/netobserv-plugin -n netobserv -- curl -G -s -H 'X-Scope-OrgID:network' -H 'Authorization: Bearer <api_token>' -k https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network/loki/api/v1/labels | jq
要从源命名空间
my-namespace获取所有流,请运行以下命令:$ oc exec deployment/netobserv-plugin -n netobserv -- curl -G -s -H 'X-Scope-OrgID:network' -H 'Authorization: Bearer <api_token>' -k https://loki-gateway-http.netobserv.svc:8080/api/logs/v1/network/loki/api/v1/query --data-urlencode 'query={SrcK8S_Namespace="my-namespace"}' | jq
其他资源
12.7. Loki ResourceExhausted 错误故障排除
当 Network Observability 发送的网络流数据时,Loki 可能会返回一个 ResourceExhausted 错误,超过配置的最大消息大小。如果使用 Red Hat Loki Operator,则这个最大消息大小被配置为 100 MiB。
流程
- 进入到 Operators → Installed Operators,从 Project 下拉菜单中选择 All projects。
- 在 Provided APIs 列表中,选择 Network Observability Operator。
点 Flow Collector,然后点 YAML view 选项卡。
-
如果使用 Loki Operator,请检查
spec.loki.batchSize值没有超过 98 MiB。 -
如果您使用与 Red Hat Loki Operator 不同的 Loki 安装方法,如 Grafana Loki,请验证
grpc_server_max_recv_msg_sizeGrafana Loki 服务器设置 高于FlowCollector资源spec.loki.batchSize值。如果没有,您必须增加grpc_server_max_recv_msg_size值,或者减少spec.loki.batchSize值,使其小于限制。
-
如果使用 Loki Operator,请检查
- 如果您编辑 FlowCollector,点 Save。
12.8. Loki 空 ring 错误
Loki "empty ring" 错误会导致流没有存储在 Loki 中,且不显示在 web 控制台中。这个错误可能会在各种情况下发生。还没有解决的一个临时解决方案。您可以采取一些操作来调查 Loki pod 中的日志,并验证 LokiStack 是否健康并就绪。
观察到此错误的一些情况如下:
在卸载并在同一个命名空间中重新安装
LokiStack后,旧的 PVC 不会被删除,这会导致这个错误。-
Action :您可以尝试再次删除
LokiStack,删除 PVC,然后重新安装LokiStack。
-
Action :您可以尝试再次删除
证书轮转后,这个错误可能会阻止与
flowlogs-pipeline和console-pluginpod 的通信。- Action :您可以重启 pod 来恢复连接。
12.9. 资源故障排除
12.10. LokiStack 速率限制错误
放置在 Loki 租户上的速率限制可能会导致数据潜在的临时丢失,而 429 错误:Per stream rate limit exceeded (limit:xMB/sec) while attempting to ingest for stream。您可能会考虑设置了警报来通知您这个错误。如需更多信息,请参阅本节的附加资源中的"为 NetObserv 仪表板创建 Loki 速率限制警报"。
您可以使用 perStreamRateLimit 和 perStreamRateLimitBurst 规格更新 LokiStack CRD,如以下步骤所示。
流程
- 进入到 Operators → Installed Operators,从 Project 下拉菜单查看 All projects。
- 查找 Loki Operator,然后选择 LokiStack 选项卡。
使用 YAML 视图 创建或编辑现有 LokiStack 实例,以添加
perStreamRateLimit和perStreamRateLimitBurst规格:apiVersion: loki.grafana.com/v1 kind: LokiStack metadata: name: loki namespace: netobserv spec: limits: global: ingestion: perStreamRateLimit: 6 1 perStreamRateLimitBurst: 30 2 tenants: mode: openshift-network managementState: Managed- 点击 Save。
验证
更新 perStreamRateLimit 和 perStreamRateLimitBurst 规格后,集群重启中的 pod,429 rate-limit 错误不再发生。