
확장 및 성능
프로덕션 환경에서 OpenShift Container Platform 클러스터 스케일링 및 성능 튜닝
초록
1장. 권장 성능 및 확장성 사례
1.1. 컨트롤 플레인 권장 사례
이 주제에서는 OpenShift Container Platform의 컨트롤 플레인에 대한 권장 성능 및 확장성 사례를 설명합니다.
1.1.1. 클러스터 스케일링에 대한 권장 사례
이 섹션의 지침은 클라우드 공급자 통합을 통한 설치에만 관련이 있습니다.
다음 모범 사례를 적용하여 OpenShift Container Platform 클러스터의 작업자 머신 수를 스케일링하십시오. 작업자 머신 세트에 정의된 복제본 수를 늘리거나 줄여 작업자 머신을 스케일링합니다.
노드 수가 많아지도록 클러스터를 확장하는 경우 다음을 수행합니다.
- 고가용성을 위해 모든 사용 가능한 영역으로 노드를 분산합니다.
- 한 번에 확장하는 머신 수가 25~50개를 넘지 않도록 합니다.
- 주기적인 공급자 용량 제약 조건을 완화하는 데 도움이 되도록 유사한 크기의 대체 인스턴스 유형을 사용하여 사용 가능한 각 영역에 새 컴퓨팅 머신 세트를 생성하는 것이 좋습니다. 예를 들어 AWS에서 m5.large 및 m5d.large를 사용합니다.
클라우드 제공자는 API 서비스 할당량을 구현할 수 있습니다. 따라서 점진적으로 클러스터를 스케일링하십시오.
컴퓨팅 머신 세트의 복제본이 한 번에 모두 더 높은 숫자로 설정된 경우 컨트롤러가 머신을 생성하지 못할 수 있습니다. OpenShift Container Platform이 배포된 클라우드 플랫폼에서 처리할 수 있는 요청 수는 프로세스에 영향을 미칩니다. 컨트롤러는 상태를 사용하여 머신을 생성하고, 점검하고, 업데이트하는 동안 더 많이 쿼리하기 시작합니다. OpenShift Container Platform이 배포된 클라우드 플랫폼에는 API 요청 제한이 있습니다. 과도한 쿼리로 인해 클라우드 플랫폼 제한으로 인해 머신 생성 오류가 발생할 수 있습니다.
노드 수가 많아지도록 스케일링하는 경우 머신 상태 점검을 활성화하십시오. 실패가 발생하면 상태 점검에서 상태를 모니터링하고 비정상 머신을 자동으로 복구합니다.
대규모 및 밀도가 높은 클러스터의 노드 수를 줄이는 경우 프로세스에서 동시에 종료되는 노드에서 실행되는 오브젝트를 드레이닝하거나 제거해야 하므로 많은 시간이 걸릴 수 있습니다. 또한 제거할 개체가 너무 많으면 클라이언트 요청 처리에 병목 현상이 발생할 수 있습니다. 기본 클라이언트 쿼리(QPS) 및 버스트 비율은 각각 50 및 100 으로 설정됩니다. 이러한 값은 OpenShift Container Platform에서 수정할 수 없습니다.
1.1.2. 컨트롤 플레인 노드 크기 조정
컨트롤 플레인 노드 리소스 요구 사항은 클러스터의 노드 및 오브젝트 수와 유형에 따라 다릅니다. 다음 컨트롤 플레인 노드 크기 권장 사항은 컨트롤 플레인 밀도 중심 테스트 또는 Cluster-density 결과를 기반으로 합니다. 이 테스트에서는 지정된 수의 네임스페이스에서 다음 오브젝트를 생성합니다.
- 이미지 스트림 1개
- 빌드 1개
-
5개의 배포,
절전상태에 2개의 Pod 복제본이 있는 배포, 4개의 시크릿 마운트, 4개의 구성 맵, 각각 1개의 Downward API 볼륨 - 5개의 서비스, 각각 이전 배포 중 하나의 TCP/8080 및 TCP/8443 포트를 가리킵니다.
- 이전 서비스 중 첫 번째를 가리키는 1 경로
- 2048 임의의 문자열 문자가 포함된 10개의 보안
- 2048 임의의 문자열 문자가 포함된 10개의 구성 맵
| 작업자 노드 수 | cluster-density(네임스페이스) | CPU 코어 수 | 메모리(GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16, 그러나 24 OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 | OVN-Kubernetes 네트워크 플러그인을 사용하는 경우 64이지만 128 |
| 501 그러나 OVN-Kubernetes 네트워크 플러그인으로 테스트되지 않음 | 4000 | 16 | 96 |
위의 표의 데이터는 r5.4xlarge 인스턴스를 컨트롤 플레인 노드로 사용하고 m5.2xlarge 인스턴스를 작업자 노드로 사용하여 AWS에서 실행되는 OpenShift Container Platform을 기반으로 합니다.
컨트롤 플레인 노드가 3개인 대규모 및 밀도가 높은 클러스터에서는 노드 중 하나가 중지, 재부팅 또는 실패할 때 CPU 및 메모리 사용량이 증가합니다. 비용 절감을 위해 전원, 네트워크, 기본 인프라 또는 의도적인 경우 클러스터를 종료한 후 클러스터를 다시 시작하는 예기치 않은 문제로 인해 오류가 발생할 수 있습니다. 나머지 두 컨트롤 플레인 노드는 고가용성이 되기 위해 부하를 처리하여 리소스 사용량을 늘려야 합니다. 이는 컨트롤 플레인 노드가 직렬로 연결, 드레이닝, 재부팅되어 운영 체제 업데이트를 적용하고 컨트롤 플레인 Operator 업데이트를 적용하기 때문에 업그레이드 중에도 이 문제가 발생할 수 있습니다. 단계적 오류를 방지하려면 컨트롤 플레인 노드에서 전체 CPU 및 메모리 리소스 사용량을 사용 가능한 모든 용량의 최대 60 %로 유지하여 리소스 사용량 급증을 처리합니다. 리소스 부족으로 인한 다운타임을 방지하기 위해 컨트롤 플레인 노드에서 CPU 및 메모리를 늘립니다.
노드 크기 조정은 클러스터의 노드 수와 개체 수에 따라 달라집니다. 또한 클러스터에서 개체가 현재 생성되는지에 따라 달라집니다. 개체 생성 중에 컨트롤 플레인은 개체가 running 단계에 있을 때보다 리소스 사용량 측면에서 더 활성화됩니다.
OLM(Operator Lifecycle Manager)은 컨트롤 플레인 노드에서 실행되며 해당 메모리 공간은 OLM이 클러스터에서 관리해야 하는 네임스페이스 및 사용자 설치된 Operator 수에 따라 다릅니다. OOM이 종료되지 않도록 컨트를 플레인 노드의 크기를 적절하게 조정해야 합니다. 다음 데이터 지점은 클러스터 최대값 테스트 결과를 기반으로 합니다.
| 네임스페이스 수 | 유휴 상태의 OLM 메모리(GB) | 5명의 사용자 operator가 설치된 OLM 메모리(GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
다음 구성에서만 실행 중인 OpenShift Container Platform 4.15 클러스터에서 컨트롤 플레인 노드 크기를 수정할 수 있습니다.
- 사용자 프로비저닝 설치 방법으로 설치된 클러스터입니다.
- 설치 관리자 프로비저닝 인프라 설치 방법을 사용하여 설치된 AWS 클러스터
- 컨트롤 플레인 머신 세트를 사용하여 컨트롤 플레인 시스템을 관리하는 클러스터입니다.
다른 모든 구성의 경우 총 노드 수를 추정하고 설치 중에 제안된 컨트롤 플레인 노드 크기를 사용해야 합니다.
권장 사항은 OpenShift SDN이 있는 OpenShift Container Platform 클러스터에서 네트워크 플러그인으로 캡처된 데이터 포인트를 기반으로 합니다.
OpenShift Container Platform 4.15에서는 기본적으로 OpenShift Container Platform 3.11 및 이전 버전과 비교하여 CPU 코어의 절반(500밀리코어)이 시스템에 의해 예약되어 있습니다. 이러한 점을 고려하여 크기가 결정됩니다.
1.1.2.1. 컨트롤 플레인 시스템에 대한 대규모 Amazon Web Services 인스턴스 유형 선택
AWS(Amazon Web Services) 클러스터의 컨트롤 플레인 시스템에 더 많은 리소스가 필요한 경우 컨트롤 플레인 시스템에서 사용할 더 큰 AWS 인스턴스 유형을 선택할 수 있습니다.
컨트롤 플레인 머신 세트를 사용하는 클러스터의 절차는 컨트롤 플레인 머신 세트를 사용하지 않는 클러스터의 절차와 다릅니다.
클러스터에서 ControlPlaneMachineSet CR의 상태에 대해 확신이 있는 경우 CR 상태를 확인할 수 있습니다.
1.1.2.1.1. 컨트롤 플레인 머신 세트를 사용하여 Amazon Web Services 인스턴스 유형 변경
컨트롤 플레인 머신 세트 CR(사용자 정의 리소스)에서 사양을 업데이트하여 컨트롤 플레인 시스템에서 사용하는 AWS(Amazon Web Services) 인스턴스 유형을 변경할 수 있습니다.
사전 요구 사항
- AWS 클러스터는 컨트롤 플레인 머신 세트를 사용합니다.
프로세스
다음 명령을 실행하여 컨트롤 플레인 머신 세트 CR을 편집합니다.
$ oc --namespace openshift-machine-api edit controlplanemachineset.machine.openshift.io cluster
providerSpec필드 아래의 다음 행을 편집합니다.providerSpec: value: ... instanceType: <compatible_aws_instance_type> 1- 1
- 이전 선택과 동일한 기준으로 더 큰 AWS 인스턴스 유형을 지정합니다. 예를 들어
m6i.xlarge를m6i.2xlarge또는m6i.4xlarge로 변경할 수 있습니다.
변경 사항을 저장하십시오.
-
기본
RollingUpdate업데이트 전략을 사용하는 클러스터의 경우 Operator는 변경 사항을 컨트롤 플레인 구성에 자동으로 전파합니다. -
OnDelete업데이트 전략을 사용하도록 구성된 클러스터의 경우 컨트롤 플레인 시스템을 수동으로 교체해야 합니다.
-
기본
1.1.2.1.2. AWS 콘솔을 사용하여 Amazon Web Services 인스턴스 유형 변경
AWS 콘솔에서 인스턴스 유형을 업데이트하여 컨트롤 플레인 시스템에서 사용하는 AWS(Amazon Web Services) 인스턴스 유형을 변경할 수 있습니다.
사전 요구 사항
- 클러스터의 EC2 인스턴스를 수정하는 데 필요한 권한이 있는 AWS 콘솔에 액세스할 수 있습니다.
-
cluster-admin역할의 사용자로 OpenShift Container Platform 클러스터에 액세스할 수 있습니다.
프로세스
- AWS 콘솔을 열고 컨트롤 플레인 시스템의 인스턴스를 가져옵니다.
컨트롤 플레인 머신 인스턴스 1개를 선택합니다.
- 선택한 컨트롤 플레인 시스템의 경우 etcd 스냅샷을 생성하여 etcd 데이터를 백업하십시오. 자세한 내용은 " etcd 백업"을 참조하십시오.
- AWS 콘솔에서 컨트롤 플레인 머신 인스턴스를 중지합니다.
- 중지된 인스턴스를 선택하고 작업 → 인스턴스 설정 → 인스턴스 유형 변경을 클릭합니다.
-
인스턴스를 더 큰 유형으로 변경하고 유형이 이전 선택과 동일한 기본 유형인지 확인하고 변경 사항을 적용합니다. 예를 들어
m6i.xlarge를m6i.2xlarge또는m6i.4xlarge로 변경할 수 있습니다. - 인스턴스를 시작합니다.
-
OpenShift Container Platform 클러스터에 인스턴스에 대한 해당
Machine오브젝트가 있는 경우 AWS 콘솔에 설정된 인스턴스 유형과 일치하도록 오브젝트의 인스턴스 유형을 업데이트합니다.
- 각 컨트롤 플레인 시스템에 대해 이 프로세스를 반복합니다.
추가 리소스
1.2. 인프라 관련 권장 사례
이 주제에서는 OpenShift Container Platform의 인프라에 대한 권장 성능 및 확장성 사례를 제공합니다.
1.2.1. 인프라 노드 크기 조정
인프라 노드는 OpenShift Container Platform 환경의 일부를 실행하도록 레이블이 지정된 노드입니다. 인프라 노드 리소스 요구사항은 클러스터 사용 기간, 노드, 클러스터의 오브젝트에 따라 달라집니다. 이러한 요인으로 인해 Prometheus의 지표 또는 시계열 수가 증가할 수 있기 때문입니다. 다음 인프라 노드 크기 권장 사항은 모니터링 스택 및 기본 ingress-controller가 이러한 노드로 이동되는 컨트롤 플레인 노드 크기 조정 섹션에 자세히 설명된 클러스터 밀도 테스트에서 관찰된 결과를 기반으로 합니다.
| 작업자 노드 수 | 클러스터 밀도 또는 네임스페이스 수 | CPU 코어 수 | 메모리(GB) |
|---|---|---|---|
| 27 | 500 | 4 | 24 |
| 120 | 1000 | 8 | 48 |
| 252 | 4000 | 16 | 128 |
| 501 | 4000 | 32 | 128 |
일반적으로 클러스터당 세 개의 인프라 노드를 사용하는 것이 좋습니다.
이러한 크기 조정 권장 사항은 지침으로 사용해야 합니다. Prometheus는 고도의 메모리 집약적 애플리케이션입니다. 리소스 사용량은 노드 수, 오브젝트, Prometheus 지표 스크래핑 간격, 지표 또는 시계열, 클러스터 사용 기간 등 다양한 요인에 따라 달라집니다. 또한 라우터 리소스 사용은 경로 수 및 인바운드 요청의 양/유형의 영향을 받을 수 있습니다.
이러한 권장 사항은 클러스터 생성 중에 설치된 인프라 인프라 구성 요소를 호스팅하는 인프라 노드에만 적용됩니다.
OpenShift Container Platform 4.15에서는 기본적으로 OpenShift Container Platform 3.11 및 이전 버전과 비교하여 CPU 코어의 절반(500밀리코어)이 시스템에 의해 예약되어 있습니다. 명시된 크기 조정 권장 사항은 이러한 요인의 영향을 받습니다.
1.2.2. Cluster Monitoring Operator 스케일링
OpenShift Container Platform에서는 Cluster Monitoring Operator가 수집하여 Prometheus 기반 모니터링 스택에 저장하는 지표를 공개합니다. 관리자는 Observe → Dashboards 로 이동하여 OpenShift Container Platform 웹 콘솔에서 시스템 리소스, 컨테이너 및 구성 요소에 대한 대시보드를 볼 수 있습니다.
1.2.3. Prometheus 데이터베이스 스토리지 요구사항
Red Hat은 다양한 규모에 대해 다양한 테스트를 수행했습니다.
- 다음 Prometheus 스토리지 요구 사항은 규범이 아니며 참조로 사용해야 합니다. Prometheus에서 수집한 메트릭을 노출하는 Pod, 컨테이너, 경로 또는 기타 리소스 수를 포함하여 워크로드 활동 및 리소스 밀도에 따라 클러스터에서 리소스 사용량이 증가할 수 있습니다.
- 스토리지 요구 사항에 맞게 크기 기반 데이터 보존 정책을 구성할 수 있습니다.
표 1.1. 클러스터의 노드/Pod 수에 따른 Prometheus 데이터베이스 스토리지 요구사항
| 노드 수 | Pod 수 (2 Pod당 컨테이너) | Prometheus 스토리지 증가(1일당) | Prometheus 스토리지 증가(15일당) | 네트워크(tsdb 청크당) |
|---|---|---|---|---|
| 50 | 1800 | 6.3GB | 94GB | 16MB |
| 100 | 3600 | 13GB | 195GB | 26MB |
| 150 | 5400 | 19GB | 283GB | 36MB |
| 200 | 7200 | 25GB | 375GB | 46MB |
스토리지 요구사항이 계산된 값을 초과하지 않도록 예상 크기의 약 20%가 오버헤드로 추가되었습니다.
위의 계산은 기본 OpenShift Container Platform Cluster Monitoring Operator용입니다.
CPU 사용률은 약간의 영향을 미칩니다. 50개 노드 및 1,800개 Pod당 비율이 약 40개 중 1개 코어입니다.
OpenShift Container Platform 권장 사항
- 인프라(infra) 노드를 두 개 이상 사용합니다.
- SSD 또는 NVMe(Non-volatile Memory express) 드라이브를 사용하여 openshift-container-storage 노드를 3개 이상 사용합니다.
1.2.4. 클러스터 모니터링 구성
클러스터 모니터링 스택에서 Prometheus 구성 요소의 스토리지 용량을 늘릴 수 있습니다.
프로세스
Prometheus의 스토리지 용량을 늘리려면 다음을 수행합니다.
YAML 구성 파일
cluster-monitoring-config.yaml을 생성합니다. 예를 들면 다음과 같습니다.apiVersion: v1 kind: ConfigMap data: config.yaml: | prometheusK8s: retention: {{PROMETHEUS_RETENTION_PERIOD}} 1 nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 2 resources: requests: storage: {{PROMETHEUS_STORAGE_SIZE}} 3 alertmanagerMain: nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 4 resources: requests: storage: {{ALERTMANAGER_STORAGE_SIZE}} 5 metadata: name: cluster-monitoring-config namespace: openshift-monitoring- 1
- Prometheus 보존의 기본값은
PROMETHEUS_RETENTION_PERIOD=15d입니다. 단위는 s, m, h, d 접미사 중 하나를 사용하는 시간으로 측정됩니다. - 2 4
- 클러스터의 스토리지 클래스입니다.
- 3
- 일반적인 값은
PROMETHEUS_STORAGE_SIZE=2000Gi입니다. 스토리지 값은 일반 정수 또는 E, P, T, G, M, K 접미사 중 하나를 사용하는 고정 지점 정수일 수 있습니다. Ei, Pi, Ti, Gi, Mi, Ki의 power-of-two를 사용할 수도 있습니다. - 5
- 일반적인 값은
ALERTMANAGER_STORAGE_SIZE=20Gi입니다. 스토리지 값은 일반 정수 또는 E, P, T, G, M, K 접미사 중 하나를 사용하는 고정 지점 정수일 수 있습니다. Ei, Pi, Ti, Gi, Mi, Ki의 power-of-two를 사용할 수도 있습니다.
- 보존 기간, 스토리지 클래스 및 스토리지 크기에 대한 값을 추가합니다.
- 파일을 저장합니다.
다음을 실행하여 변경사항을 적용합니다.
$ oc create -f cluster-monitoring-config.yaml
1.2.5. 추가 리소스
1.3. etcd 관련 권장 사례
이 주제에서는 OpenShift Container Platform의 etcd에 대한 권장 성능 및 확장성 사례를 제공합니다.
1.3.1. etcd 관련 권장 사례
etcd는 디스크에 데이터를 작성하고 디스크에 제안을 유지하므로 성능은 디스크 성능에 따라 다릅니다. etcd는 특히 I/O 집약적이지만 최적의 성능과 안정성을 위해 짧은 대기 시간 블록 장치가 필요합니다. etcd의 접합성 프로토콜은 메타데이터를 로그(WAL)에 영구적으로 저장하는 데 따라 다르기 때문에 etcd는 디스크 쓰기 대기 시간에 민감합니다. 다른 프로세스의 디스크 및 디스크 활동이 느리면 fsync 대기 시간이 길어질 수 있습니다.
이러한 대기 시간으로 인해 etcd가 하트비트를 놓치고 새 제안을 제 시간에 디스크에 커밋하지 않고 궁극적으로 요청 시간 초과 및 임시 리더 손실이 발생할 수 있습니다. 쓰기 대기 시간이 길어지면 OpenShift API 속도가 느려서 클러스터 성능에 영향을 미칩니다. 이러한 이유로 I/O 민감하거나 집약적이며 동일한 기본 I/O 인프라를 공유하는 컨트롤 플레인 노드에서 다른 워크로드를 배치하지 마십시오.
대기 시간 측면에서 8000바이트의 최소 50 IOPS를 순차적으로 작성할 수 있는 블록 장치 상단에서 etcd를 실행합니다. 즉, 대기 시간이 10ms인 경우 fdatasync를 사용하여 WAL의 각 쓰기를 동기화합니다. 로드가 많은 클러스터의 경우 8000바이트(2ms)의 순차적 500 IOPS를 권장합니다. 이러한 숫자를 측정하려면 fio와 같은 벤치마킹 툴을 사용할 수 있습니다.
이러한 성능을 달성하려면 대기 시간이 짧고 처리량이 높은 SSD 또는 NVMe 디스크에서 지원하는 머신에서 etcd를 실행합니다. 메모리 셀당 1비트를 제공하는 SSD(Single-level cell) SSD(Solid-State Drive)는 Cryostat 및 reliable이며 쓰기 집약적인 워크로드에 이상적입니다.
etcd의 로드는 노드 및 Pod 수와 같은 정적 요인과 Pod 자동 스케일링, Pod 재시작, 작업 실행 및 기타 워크로드 관련 이벤트로 인한 끝점 변경 등 동적 요인에서 발생합니다. etcd 설정의 크기를 정확하게 조정하려면 워크로드의 특정 요구 사항을 분석해야 합니다. etcd의 로드에 영향을 미치는 노드, 포드 및 기타 관련 요인을 고려하십시오.
다음 하드 드라이브 사례는 최적의 etcd 성능을 제공합니다.
- 전용 etcd 드라이브를 사용합니다. iSCSI와 같이 네트워크를 통해 통신하는 드라이브를 방지합니다. etcd 드라이브에 로그 파일 또는 기타 많은 워크로드를 배치하지 마십시오.
- 빠른 읽기 및 쓰기 작업을 지원하기 위해 대기 시간이 짧은 드라이브를 선호합니다.
- 더 빠른 압축 및 조각 모음을 위해 고 대역폭 쓰기를 선호합니다.
- 실패에서 더 빠른 복구를 위해 고 대역폭 읽기를 선호합니다.
- 솔리드 스테이트 드라이브를 최소 선택으로 사용하십시오. 프로덕션 환경에 대한 NVMe 드라이브를 선호합니다.
- 안정성 향상을 위해 서버 수준 하드웨어를 사용하십시오.
NAS 또는 SAN 설정 및 회전 드라이브를 방지합니다. Ceph Rados Block Device(RBD) 및 기타 유형의 네트워크 연결 스토리지로 인해 네트워크 대기 시간이 예측할 수 없습니다. 대규모 etcd 노드에 빠른 스토리지를 제공하려면 PCI 패스스루를 사용하여 NVM 장치를 노드에 직접 전달합니다.
항상 fio와 같은 유틸리티를 사용하여 벤치마크합니다. 이러한 유틸리티를 사용하여 증가에 따라 클러스터 성능을 지속적으로 모니터링할 수 있습니다.
NFS(Network File System) 프로토콜 또는 기타 네트워크 기반 파일 시스템을 사용하지 마십시오.
배포된 OpenShift Container Platform 클러스터에서 모니터링할 몇 가지 주요 지표는 etcd 디스크 쓰기 전 로그 기간과 etcd 리더 변경 횟수입니다. 이러한 지표를 추적하려면 Prometheus를 사용하십시오.
etcd 멤버 데이터베이스 크기는 정상적인 작업 중에 클러스터에서 다를 수 있습니다. 이 차이점은 리더 크기가 다른 멤버와 다른 경우에도 클러스터 업그레이드에는 영향을 미치지 않습니다.
OpenShift Container Platform 클러스터를 생성하기 전이나 후에 etcd의 하드웨어를 검증하려면 fio를 사용할 수 있습니다.
사전 요구 사항
- Podman 또는 Docker와 같은 컨테이너 런타임은 테스트 중인 시스템에 설치됩니다.
-
데이터는
/var/lib/etcd경로에 기록됩니다.
프로세스
Fio를 실행하고 결과를 분석합니다.
Podman을 사용하는 경우 다음 명령을 실행합니다.
$ sudo podman run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/cloud-bulldozer/etcd-perf
Docker를 사용하는 경우 다음 명령을 실행합니다.
$ sudo docker run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/cloud-bulldozer/etcd-perf
출력에서는 실행에서 캡처된 fsync 지표의 99번째 백분위수를 비교하여 디스크가 etcd를 호스트할 수 있을 만큼 빠른지 여부를 보고하여 10ms 미만인지 확인합니다. I/O 성능의 영향을 받을 수 있는 가장 중요한 etcd 지표 중 일부는 다음과 같습니다.
-
etcd_disk_wal_fsync_duration_seconds_bucket지표에서 etcd의 WAL fsync 기간을 보고합니다. -
etcd_disk_backend_commit_duration_seconds_bucket지표에서 etcd 백엔드 커밋 대기 시간 보고 -
etcd_server_leader_changes_seen_total메트릭에서 리더 변경 사항을 보고합니다.
etcd는 모든 멤버 간에 요청을 복제하므로 성능은 네트워크 입력/출력(I/O) 대기 시간에 따라 달라집니다. 네트워크 대기 시간이 길어지면 etcd 하트비트가 선택 시간 초과보다 오래 걸리므로 리더 선택이 발생하여 클러스터가 손상될 수 있습니다. 배포된 OpenShift Container Platform 클러스터에서 모니터링되는 주요 메트릭은 각 etcd 클러스터 멤버에서 etcd 네트워크 피어 대기 시간의 99번째 백분위 수입니다. 이러한 메트릭을 추적하려면 Prometheus를 사용하십시오.
히스토그램_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[2m])) 메트릭은 etcd가 멤버 간 클라이언트 요청을 복제하는 것을 완료하기 위한 왕복 시간을 보고합니다. 50ms 미만이어야 합니다.
1.3.2. etcd를 다른 디스크로 이동
etcd를 공유 디스크에서 별도의 디스크로 이동하여 성능 문제를 방지하거나 해결할 수 있습니다.
MCO(Machine Config Operator)는 OpenShift Container Platform 4.15 컨테이너 스토리지를 위한 보조 디스크를 마운트합니다.
이 인코딩된 스크립트는 다음 장치 유형에 대한 장치 이름만 지원합니다.
- SCSI 또는 SATA
-
/dev/sd* - 가상 장치
-
/dev/vd* - NVMe
-
/dev/nvme*[0-9]*n*
제한
-
새 디스크가 클러스터에 연결되면 etcd 데이터베이스가 root 마운트의 일부입니다. 기본 노드가 다시 생성되는 경우 보조 디스크 또는 의도한 디스크의 일부가 아닙니다. 결과적으로 기본 노드는 별도의
/var/lib/etcd마운트를 생성하지 않습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - 머신 구성을 업로드하기 전에 디스크를 추가합니다.
-
MachineConfigPool은metadata.labels[machineconfiguration.openshift.io/role]과 일치해야 합니다. 이는 컨트롤러, 작업자 또는 사용자 지정 풀에 적용됩니다.
이 절차에서는 루트 파일 시스템의 부분(예: /var/ )을 설치된 노드의 다른 디스크 또는 파티션으로 이동하지 않습니다.
프로세스
새 디스크를 클러스터에 연결하고 디버그 쉘에서
lsblk명령을 실행하여 노드에서 디스크가 감지되었는지 확인합니다.$ oc debug node/<node_name>
# lsblk
lsblk명령에서 보고한 새 디스크의 장치 이름을 확인합니다.사용자 환경에 따라 스크립트의 장치 이름을 디코딩하고 교체합니다.
#!/bin/bash set -uo pipefail for device in <device_type_glob>; do 1 /usr/sbin/blkid $device &> /dev/null if [ $? == 2 ]; then echo "secondary device found $device" echo "creating filesystem for etcd mount" mkfs.xfs -L var-lib-etcd -f $device &> /dev/null udevadm settle touch /etc/var-lib-etcd-mount exit fi done echo "Couldn't find secondary block device!" >&2 exit 77- 1
- &
lt;device_type_glob>를 블록 장치 유형의 쉘 글로 바꿉니다. SCSI 또는 SATA 드라이브의 경우/dev/sd*를 사용합니다. 가상 드라이브의 경우/dev/vd*를 사용합니다. NVMe 드라이브의 경우/dev/nvme*[0-9]*를 사용합니다.
다음과 같은 콘텐츠를 사용하여
etcd-mc.yml이라는MachineConfigYAML 파일을 만듭니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 98-var-lib-etcd spec: config: ignition: version: 3.1.0 storage: files: - path: /etc/find-secondary-device mode: 0755 contents: source: data:text/plain;charset=utf-8;base64,<encoded_etc_find_secondary_device_script> 1 systemd: units: - name: find-secondary-device.service enabled: true contents: | [Unit] Description=Find secondary device DefaultDependencies=false After=systemd-udev-settle.service Before=local-fs-pre.target ConditionPathExists=!/etc/var-lib-etcd-mount [Service] RemainAfterExit=yes ExecStart=/etc/find-secondary-device RestartForceExitStatus=77 [Install] WantedBy=multi-user.target - name: var-lib-etcd.mount enabled: true contents: | [Unit] Before=local-fs.target [Mount] What=/dev/disk/by-label/var-lib-etcd Where=/var/lib/etcd Type=xfs TimeoutSec=120s [Install] RequiredBy=local-fs.target - name: sync-var-lib-etcd-to-etcd.service enabled: true contents: | [Unit] Description=Sync etcd data if new mount is empty DefaultDependencies=no After=var-lib-etcd.mount var.mount Before=crio.service [Service] Type=oneshot RemainAfterExit=yes ExecCondition=/usr/bin/test ! -d /var/lib/etcd/member ExecStart=/usr/sbin/setsebool -P rsync_full_access 1 ExecStart=/bin/rsync -ar /sysroot/ostree/deploy/rhcos/var/lib/etcd/ /var/lib/etcd/ ExecStart=/usr/sbin/semanage fcontext -a -t container_var_lib_t '/var/lib/etcd(/.*)?' ExecStart=/usr/sbin/setsebool -P rsync_full_access 0 TimeoutSec=0 [Install] WantedBy=multi-user.target graphical.target - name: restorecon-var-lib-etcd.service enabled: true contents: | [Unit] Description=Restore recursive SELinux security contexts DefaultDependencies=no After=var-lib-etcd.mount Before=crio.service [Service] Type=oneshot RemainAfterExit=yes ExecStart=/sbin/restorecon -R /var/lib/etcd/ TimeoutSec=0 [Install] WantedBy=multi-user.target graphical.target- 1
- 이전에 생성한 인코딩된 문자열을 사용하여 이 문자열을 사용자가 지정한 인코딩된 스크립트로 바꿉니다.
검증 단계
노드의 디버그 쉘에서
grep /var/lib/etcd /proc/mounts명령을 실행하여 디스크가 마운트되었는지 확인합니다.$ oc debug node/<node_name>
# grep -w "/var/lib/etcd" /proc/mounts
출력 예
/dev/sdb /var/lib/etcd xfs rw,seclabel,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota 0 0
1.3.3. etcd 데이터 조각 모음
대규모 및 밀도가 높은 클러스터의 경우 키 공간이 너무 커져서 공간 할당량을 초과하면 etcd 성능이 저하될 수 있습니다. etcd를 정기적으로 유지 관리하고 조각 모음하여 데이터 저장소의 공간을 확보합니다. Prometheus에 대해 etcd 지표를 모니터링하고 필요한 경우 조각 모음합니다. 그러지 않으면 etcd에서 키 읽기 및 삭제만 허용하는 유지 관리 모드로 클러스터를 만드는 클러스터 전체 알람을 발생시킬 수 있습니다.
다음 주요 메트릭을 모니터링합니다.
-
etcd_server_quota_backend_bytes(현재 할당량 제한) -
etcd_mvcc_db_total_size_in_use_in_bytes에서는 기록 압축 후 실제 데이터베이스 사용량을 나타냅니다. -
etcd_mvcc_db_total_size_in_bytes: 조각 모음 대기 여유 공간을 포함하여 데이터베이스 크기를 표시합니다.
etcd 기록 압축과 같은 디스크 조각화를 초래하는 이벤트 후 디스크 공간을 회수하기 위해 etcd 데이터를 조각 모음합니다.
기록 압축은 5분마다 자동으로 수행되며 백엔드 데이터베이스에서 공백이 남습니다. 이 분할된 공간은 etcd에서 사용할 수 있지만 호스트 파일 시스템에서 사용할 수 없습니다. 호스트 파일 시스템에서 이 공간을 사용할 수 있도록 etcd 조각을 정리해야 합니다.
조각 모음이 자동으로 수행되지만 수동으로 트리거할 수도 있습니다.
etcd Operator는 클러스터 정보를 사용하여 사용자에게 가장 효율적인 작업을 결정하기 때문에 자동 조각 모음은 대부분의 경우에 적합합니다.
1.3.3.1. 자동 조각 모음
etcd Operator는 디스크 조각 모음을 자동으로 수행합니다. 수동 조작이 필요하지 않습니다.
다음 로그 중 하나를 확인하여 조각 모음 프로세스가 성공했는지 확인합니다.
- etcd 로그
- cluster-etcd-operator Pod
- Operator 상태 오류 로그
자동 조각 모음으로 인해 Kubernetes 컨트롤러 관리자와 같은 다양한 OpenShift 핵심 구성 요소에서 리더 선택 실패가 발생하여 실패한 구성 요소를 다시 시작할 수 있습니다. 재시작은 무해하며 다음 실행 중인 인스턴스로 장애 조치를 트리거하거나 다시 시작한 후 구성 요소가 작업을 다시 시작합니다.
성공적으로 조각 모음을 위한 로그 출력 예
etcd member has been defragmented: <member_name>, memberID: <member_id>
실패한 조각 모음에 대한 로그 출력 예
failed defrag on member: <member_name>, memberID: <member_id>: <error_message>
1.3.3.2. 수동 조각 모음
Prometheus 경고는 수동 조각 모음을 사용해야 하는 시기를 나타냅니다. 경고는 다음 두 가지 경우에 표시됩니다.
- etcd에서 사용 가능한 공간의 50% 이상을 10분 이상 사용하는 경우
- etcd가 10분 이상 전체 데이터베이스 크기의 50% 미만을 적극적으로 사용하는 경우
PromQL 표현식의 조각 모음으로 해제될 etcd 데이터베이스 크기를 MB 단위로 확인하여 조각 모음이 필요한지 여부를 확인할 수도 있습니다. (etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_bytes)/1024/1024
etcd를 분리하는 것은 차단 작업입니다. 조각 모음이 완료될 때까지 etcd 멤버는 응답하지 않습니다. 따라서 각 pod의 조각 모음 작업 간에 클러스터가 정상 작동을 재개할 수 있도록 1분 이상 대기해야 합니다.
각 etcd 멤버의 etcd 데이터 조각 모음을 수행하려면 다음 절차를 따릅니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
리더가 최종 조각화 처리를 수행하므로 어떤 etcd 멤버가 리더인지 확인합니다.
etcd pod 목록을 가져옵니다.
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide
출력 예
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>
Pod를 선택하고 다음 명령을 실행하여 어떤 etcd 멤버가 리더인지 확인합니다.
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table
출력 예
Defaulting container name to etcdctl. Use 'oc describe pod/etcd-ip-10-0-159-225.example.redhat.com -n openshift-etcd' to see all of the containers in this pod. +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.5.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
이 출력의
ISLEADER 열에 따르면https://10.0.199.170:2379엔드 포인트가 리더입니다. 이전 단계의 출력과 이 앤드 포인트가 일치하면 리더의 Pod 이름은etcd-ip-10-0199-170.example.redhat.com입니다.
etcd 멤버를 분리합니다.
실행중인 etcd 컨테이너에 연결하고 리더가 아닌 pod 이름을 전달합니다.
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com
ETCDCTL_ENDPOINTS환경 변수를 설정 해제합니다.sh-4.4# unset ETCDCTL_ENDPOINTS
etcd 멤버를 분리합니다.
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag
출력 예
Finished defragmenting etcd member[https://localhost:2379]
시간 초과 오류가 발생하면 명령이 성공할 때까지
--command-timeout의 값을 늘립니다.데이터베이스 크기가 감소되었는지 확인합니다.
sh-4.4# etcdctl endpoint status -w table --cluster
출력 예
+---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.5.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.5.9 | 41 MB | false | false | 7 | 91624 | 91624 | | 1 | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.5.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+이 예에서는 etcd 멤버의 데이터베이스 크기가 시작 크기인 104MB와 달리 현재 41MB임을 보여줍니다.
다음 단계를 반복하여 다른 etcd 멤버에 연결하고 조각 모음을 수행합니다. 항상 리더의 조각 모음을 마지막으로 수행합니다.
etcd pod가 복구될 수 있도록 조각 모음 작업에서 1분 이상 기다립니다. etcd pod가 복구될 때까지 etcd 멤버는 응답하지 않습니다.
공간 할당량을 초과하여
NOSPACE경고가 발생하는 경우 이를 지우십시오.NOSPACE경고가 있는지 확인합니다.sh-4.4# etcdctl alarm list
출력 예
memberID:12345678912345678912 alarm:NOSPACE
경고를 지웁니다.
sh-4.4# etcdctl alarm disarm
1.3.4. etcd의 튜닝 매개변수 설정
컨트롤 플레인 하드웨어 속도를 "Standard", "Slower" 또는 기본값인 "" 로 설정할 수 있습니다.
기본 설정을 사용하면 시스템에서 사용할 속도를 결정할 수 있습니다. 이 값을 사용하면 시스템에서 이전 버전에서 값을 선택할 수 있으므로 이 기능이 존재하지 않는 버전에서 업그레이드할 수 있습니다.
다른 값 중 하나를 선택하면 기본값을 덮어씁니다. 시간 초과 또는 누락된 하트비트로 인해 리더 선택이 많이 표시되고 시스템이 "" 또는 "표준" 으로 설정된 경우 하드웨어 속도를 "Slower" 로 설정하여 시스템의 대기 시간을 늘리도록 합니다.
etcd 대기 오차 튜닝은 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
1.3.4.1. 하드웨어 속도 내결함성 변경
etcd의 하드웨어 속도 내결함성을 변경하려면 다음 단계를 완료합니다.
사전 요구 사항
- 기술 프리뷰 기능을 활성화하기 위해 클러스터 인스턴스를 편집했습니다. 자세한 내용은 "기능 게이트 이해"를 참조하십시오.
프로세스
다음 명령을 입력하여 현재 값이 무엇인지 확인합니다.
$ oc describe etcd/cluster | grep "Control Plane Hardware Speed"
출력 예
Control Plane Hardware Speed: <VALUE>
참고출력이 비어 있으면 필드가 설정되지 않았으며 기본값으로 간주해야 합니다.
다음 명령을 입력하여 값을 변경합니다. &
lt;value>를"","Standard"또는"Slower": 유효한 값 중 하나로 바꿉니다.oc patch etcd/cluster --type=merge -p '{"spec": {"controlPlaneHardwareSpeed": "<value>"}}'다음 표는 각 프로필에 대한 하트비트 간격 및 리더 선택 시간 초과를 나타냅니다. 이러한 값은 변경될 수 있습니다.
프로필
ETCD_HEARTBEAT_INTERVAL
ETCD_LEADER_ELECTION_TIMEOUT
""플랫폼에 따라 다릅니다.
플랫폼에 따라 다릅니다.
Standard100
1000
느림500
2500
출력을 확인합니다.
출력 예
etcd.operator.openshift.io/cluster patched
유효한 값 이외의 값을 입력하면 오류 출력이 표시됩니다. 예를 들어 값으로
"Faster"를 입력하면 출력은 다음과 같습니다.출력 예
The Etcd "cluster" is invalid: spec.controlPlaneHardwareSpeed: Unsupported value: "Faster": supported values: "", "Standard", "Slower"
다음 명령을 입력하여 값이 변경되었는지 확인합니다.
$ oc describe etcd/cluster | grep "Control Plane Hardware Speed"
출력 예
Control Plane Hardware Speed: ""
etcd pod가 롤아웃될 때까지 기다립니다.
oc get pods -n openshift-etcd -w
다음 출력은 master-0에 대한 예상 항목을 보여줍니다. 계속하기 전에 모든 마스터에
실행 중인 4/4상태가 표시될 때까지 기다립니다.출력 예
installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 Pending 0 0s installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 Pending 0 0s installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 ContainerCreating 0 0s installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 ContainerCreating 0 1s installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 1/1 Running 0 2s installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 Completed 0 34s installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 Completed 0 36s installer-9-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 Completed 0 36s etcd-guard-ci-ln-qkgs94t-72292-9clnd-master-0 0/1 Running 0 26m etcd-ci-ln-qkgs94t-72292-9clnd-master-0 4/4 Terminating 0 11m etcd-ci-ln-qkgs94t-72292-9clnd-master-0 4/4 Terminating 0 11m etcd-ci-ln-qkgs94t-72292-9clnd-master-0 0/4 Pending 0 0s etcd-ci-ln-qkgs94t-72292-9clnd-master-0 0/4 Init:1/3 0 1s etcd-ci-ln-qkgs94t-72292-9clnd-master-0 0/4 Init:2/3 0 2s etcd-ci-ln-qkgs94t-72292-9clnd-master-0 0/4 PodInitializing 0 3s etcd-ci-ln-qkgs94t-72292-9clnd-master-0 3/4 Running 0 4s etcd-guard-ci-ln-qkgs94t-72292-9clnd-master-0 1/1 Running 0 26m etcd-ci-ln-qkgs94t-72292-9clnd-master-0 3/4 Running 0 20s etcd-ci-ln-qkgs94t-72292-9clnd-master-0 4/4 Running 0 20s
다음 명령을 입력하여 값을 검토합니다.
$ oc describe -n openshift-etcd pod/<ETCD_PODNAME> | grep -e HEARTBEAT_INTERVAL -e ELECTION_TIMEOUT
참고이러한 값은 기본값에서 변경되지 않을 수 있습니다.
추가 리소스
2장. 오브젝트 최대값에 따른 환경 계획
OpenShift Container Platform 클러스터를 계획하는 경우 다음과 같은 테스트된 오브젝트 최대값을 고려하십시오.
이러한 지침은 가능한 가장 큰 클러스터를 기반으로 합니다. 크기가 작은 클러스터의 경우 최대값이 더 낮습니다. etcd 버전 또는 스토리지 데이터 형식을 비롯하여 명시된 임계값에 영향을 주는 요인은 여러 가지가 있습니다.
대부분의 경우 이러한 수치를 초과하면 전체 성능이 저하됩니다. 반드시 클러스터가 실패하는 것은 아닙니다.
Pod 시작 및 중지가 많은 경우와 같이 신속한 변경이 발생하는 클러스터는 문서화된 것보다 실용적인 최대 크기를 줄일 수 있습니다.
2.1. OpenShift Container Platform에 대해 테스트된 클러스터 최대값(주요 릴리스)
Red Hat은 OpenShift Container Platform 클러스터 크기 조정에 대한 직접적인 지침을 제공하지 않습니다. 이는 클러스터가 OpenShift Container Platform의 지원되는 범위 내에 있는지 여부를 확인하려면 클러스터 스케일링을 제한하는 모든 다차원 요인을 신중하게 고려해야 하기 때문입니다.
OpenShift Container Platform은 절대 클러스터 최대값이 아닌 테스트된 클러스터 최대값을 지원합니다. OpenShift Container Platform 버전, 컨트롤 플레인 워크로드 및 네트워크 플러그인을 모두 조합한 것은 아니므로 다음 표는 모든 배포에 대한 대규모의 절대 기대치를 나타내지는 않습니다. 모든 차원의 최대값을 동시에 확장하지 못할 수 있습니다. 이 표에는 특정 워크로드 및 배포 구성에 대해 테스트된 최대값이 포함되어 있으며 유사한 배포로 예상되는 항목에 대한 스케일 가이드 역할을 합니다.
| 최대값 유형 | 4.x 테스트된 최대값 |
|---|---|
| 노드 수 | 2,000 [1] |
| Pod 수 [2] | 150,000 |
| 노드당 Pod 수 | 2,500 [3][4] |
| 코어당 Pod 수 | 기본값 없음 |
| 네임스페이스 수 [5] | 10,000 |
| 빌드 수 | 10,000(기본 Pod RAM 512Mi) - S2I(Source-to-Image) 빌드 전략 |
| 네임스페이스당 Pod 수 [6] | 25,000 |
| Ingress 컨트롤러당 경로 및 백엔드 수 | 라우터당 2,000개 |
| 보안 수 | 80,000 |
| 구성 맵 수 | 90,000 |
| 서비스 수 [7] | 10,000 |
| 네임스페이스당 서비스 수 | 5,000 |
| 서비스당 백엔드 수 | 5,000 |
| 네임스페이스당 배포 수 [6] | 2,000 |
| 빌드 구성 수 | 12,000 |
| CRD(사용자 정의 리소스 정의) 수 | 1,024 [8] |
- Pod 일시 중지는 2000 노드 규모로 OpenShift Container Platform의 컨트롤 플레인 구성 요소를 강조하기 위해 배포되었습니다. 유사한 숫자로 확장하는 기능은 특정 배포 및 워크로드 매개변수에 따라 달라집니다.
- 여기에 표시된 Pod 수는 테스트 Pod 수입니다. 실제 Pod 수는 애플리케이션 메모리, CPU 및 스토리지 요구사항에 따라 달라집니다.
-
이 테스트는 컨트롤 플레인 3개, 인프라 노드 2개, 작업자 노드 26개 등 31개의 서버가 있는 클러스터에서 테스트되었습니다. 2,500개의 사용자 Pod가 필요한 경우 각 노드에 2000개 이상의 Pod를 포함할 수 있을 만큼 큰 네트워크를 할당하고
maxPods가2500으로 설정된 사용자 정의 kubelet 구성이 모두 필요한20개의hostPrefix가 필요합니다. 자세한 내용은 OCP 4.13에서 노드당 2500개의 Pod 실행을 참조하십시오. -
노드당 테스트된 최대 Pod는
OVNKubernetes네트워크 플러그인을 사용하는 클러스터의 경우 2,500입니다.OpenShiftSDN네트워크 플러그인의 노드당 테스트된 최대 Pod는 500개의 포드입니다. - 활성 프로젝트 수가 많은 경우 키 공간이 지나치게 커져서 공간 할당량을 초과하면 etcd 성능이 저하될 수 있습니다. etcd 스토리지를 확보하기 위해 조각 모음을 포함한 etcd의 유지보수를 정기적으로 수행하는 것이 좋습니다.
- 시스템에는 일부 상태 변경에 대한 대응으로 지정된 네임스페이스의 모든 오브젝트를 반복해야 하는 컨트롤 루프가 여러 개 있습니다. 단일 네임스페이스에 지정된 유형의 오브젝트가 많이 있으면 루프 비용이 많이 들고 지정된 상태 변경 처리 속도가 느려질 수 있습니다. 이 제한을 적용하면 애플리케이션 요구사항을 충족하기에 충분한 CPU, 메모리 및 디스크가 시스템에 있다고 가정합니다.
-
각 서비스 포트와 각 서비스 백엔드에는
iptables에 해당 항목이 있습니다. 지정된 서비스의 백엔드 수는끝점오브젝트의 크기에 영향을 미치므로 시스템 전체에서 전송되는 데이터의 크기에 영향을 미칩니다. -
29개의 서버가 있는 클러스터에서 테스트되었습니다. 컨트롤 플레인 3개, 인프라 노드 2개 및 작업자 노드 24개 클러스터에는 500개의 네임스페이스가 있습니다. OpenShift Container Platform에는 OpenShift Container Platform에서 설치하는 제품을 포함하여 OpenShift Container Platform 및 사용자 생성 CRD와 통합되는 제품을 포함하여 1,024개의 총 사용자 정의 리소스 정의(CRD) 제한이 있습니다. 1,024 CRD 이상이 생성된 경우
oc명령 요청이 제한될 수 있습니다.
2.1.1. 시나리오 예
예를 들어 500개의 작업자 노드(m5.2xl)가 테스트되었으며 OpenShift Container Platform 4.15, OVN-Kubernetes 네트워크 플러그인 및 다음 워크로드 오브젝트를 사용하여 지원됩니다.
- 200개의 네임스페이스(기본값 포함)
- 노드당 60 Pod, 서버 30개 및 클라이언트 Pod 30개(총 30개)
- 57 이미지 스트림/ns (최대 11.4k)
- 서버 Pod가 지원하는 15개의 서비스/서버(총 3k)
- 이전 서비스에서 지원하는 15개의 경로/ns(총 3k)
- 20개의 시크릿/ns (4k 전체)
- 10개의 구성 맵/ns (2k 합계)
- 6 네트워크 정책/ns, deny-all, allow-from ingress 및 intra-namespace 규칙 6개
- 57개의 빌드/ns
다음 요인은 클러스터 워크로드 확장, 긍정 또는 부정적인 영향을 미치는 것으로 알려져 있으며 배포를 계획할 때 스케일 숫자로 고려해야 합니다. 자세한 내용 및 지침은 영업 담당자 또는 Red Hat 지원에 문의하십시오.
- 노드당 Pod 수
- Pod당 컨테이너 수
- 사용된 프로브 유형(예: liveness/readiness, exec/http)
- 네트워크 정책 수
- 프로젝트 수 또는 네임스페이스
- 프로젝트당 이미지 스트림 수
- 프로젝트당 빌드 수
- 서비스/엔드포인트 및 유형 수
- 경로 수
- shard 수
- 보안 수
- 구성 맵 수
클러스터 구성에서 상황이 얼마나 빠르게 변경되는지 추정하는 API 호출 속도 또는 클러스터 "churn"입니다.
-
5분 동안의 초당 Pod 생성 요청에 대한 Prometheus 쿼리:
sum(irate(apiserver_request_count{resource="pods",verb="POST"}[5m])) -
5분 동안의 모든 API 요청에 대한 Prometheus 쿼리:
sum(apiserver_request_count{}[5m])
-
5분 동안의 초당 Pod 생성 요청에 대한 Prometheus 쿼리:
- CPU의 클러스터 노드 리소스 사용
- 메모리의 클러스터 노드 리소스 사용
2.2. 클러스터 최대값 테스트를 위한 OpenShift Container Platform 환경 및 구성
2.2.1. AWS 클라우드 플랫폼
| 노드 | 플레이버 | vCPU | RAM(GiB) | 디스크 유형 | 디스크 크기(GiB)/IOS | 수량 | 리전 |
|---|---|---|---|---|---|---|---|
| 컨트롤 플레인/etcd [1] | r5.4xlarge | 16 | 128 | gp3 | 220 | 3 | us-west-2 |
| 인프라 [2] | m5.12xlarge | 48 | 192 | gp3 | 100 | 3 | us-west-2 |
| 워크로드 [3] | m5.4xlarge | 16 | 64 | gp3 | 500 [4] | 1 | us-west-2 |
| Compute | m5.2xlarge | 8 | 32 | gp3 | 100 | 3/25/250/500 [5] | us-west-2 |
- etcd가 대기 시간에 민감하기 때문에 초당 3000 IOPS 및 125MiB의 기본 성능이 있는 gp3 디스크는 컨트롤 플레인/etcd 노드에 사용됩니다. gp3 볼륨은 버스트 성능을 사용하지 않습니다.
- 인프라 노드는 모니터링, Ingress 및 레지스트리 구성 요소를 호스팅하는데 사용되어 대규모로 실행할 수 있는 충분한 리소스가 있는지 확인합니다.
- 워크로드 노드는 성능 및 확장 가능한 워크로드 생성기 실행 전용입니다.
- 성능 및 확장성 테스트 실행 중에 수집되는 대량의 데이터를 저장할 수 있는 충분한 공간을 확보 할 수 있도록 큰 디스크 크기가 사용됩니다.
- 클러스터는 반복적으로 확장되며 성능 및 확장성 테스트는 지정된 노드 수에 따라 실행됩니다.
2.2.2. IBM Power 플랫폼
| 노드 | vCPU | RAM(GiB) | 디스크 유형 | 디스크 크기(GiB)/IOS | 수량 |
|---|---|---|---|---|---|
| 컨트롤 플레인/etcd [1] | 16 | 32 | io1 | GiB당 120/10 IOPS | 3 |
| 인프라 [2] | 16 | 64 | gp2 | 120 | 2 |
| 워크로드 [3] | 16 | 256 | gp2 | 120 [4] | 1 |
| Compute | 16 | 64 | gp2 | 120 | 2에서 100까지 [5] |
- etcd는 I/O 집약적이고 대기 시간에 민감하므로 GiB당 120/10 IOPS가 있는 io1 디스크는 컨트롤 플레인/etcd 노드에 사용됩니다.
- 인프라 노드는 모니터링, Ingress 및 레지스트리 구성 요소를 호스팅하는데 사용되어 대규모로 실행할 수 있는 충분한 리소스가 있는지 확인합니다.
- 워크로드 노드는 성능 및 확장 가능한 워크로드 생성기 실행 전용입니다.
- 성능 및 확장성 테스트 실행 중에 수집되는 대량의 데이터를 저장할 수 있는 충분한 공간을 확보 할 수 있도록 큰 디스크 크기가 사용됩니다.
- 클러스터는 반복으로 확장됩니다.
2.2.3. IBM Z 플랫폼
| 노드 | vCPU [4] | RAM(GiB)[5] | 디스크 유형 | 디스크 크기(GiB)/IOS | 수량 |
|---|---|---|---|---|---|
| 컨트롤 플레인/etcd [1,2] | 8 | 32 | ds8k | 300 / LCU 1 | 3 |
| 컴퓨팅 [1,3] | 8 | 32 | ds8k | 150 / LCU 2 | 4개의 노드(노드당 100/250/500 Pod로 스케일링) |
- etcd는 I/O 집약적이고 대기 시간에 민감하므로 컨트롤 플레인/etcd 노드의 디스크 I/O 로드를 최적화하기 위해 두 개의 LCU(Logical Control Unit) 간에 노드가 배포됩니다. etcd I/O 요구 사항은 다른 워크로드를 방해하지 않아야 합니다.
- 4개의 컴퓨팅 노드는 동시에 100/250/500개의 Pod가 있는 여러 반복 실행 테스트에 사용됩니다. 먼저 Pod를 유휴 상태로 설정하여 Pod 인스턴스를 평가할 수 있습니다. 다음으로, 과부하에 따른 시스템의 안정성을 평가하는 데 네트워크 및 CPU가 클라이언트/서버 워크로드를 사용했습니다. 클라이언트 및 서버 pod는 쌍으로 배포되었으며 각 쌍이 두 개의 컴퓨팅 노드에 분배되었습니다.
- 별도의 워크로드 노드가 사용되지 않았습니다. 워크로드는 두 컴퓨팅 노드 간에 마이크로 서비스 워크로드를 시뮬레이션합니다.
- 사용되는 물리적 프로세서 수는 Linux(IFL)에 대한 통합 6개입니다.
- 사용된 총 실제 메모리는 512GiB입니다.
2.3. 테스트된 클러스터 최대값에 따라 환경을 계획하는 방법
노드에서 물리적 리소스에 대한 서브스크립션을 초과하면 Pod를 배치하는 동안 Kubernetes 스케줄러가 보장하는 리소스에 영향을 미칩니다. 메모리 교체가 발생하지 않도록 하기 위해 수행할 수 있는 조치를 알아보십시오.
테스트된 최대값 중 일부는 단일 차원에서만 확장됩니다. 클러스터에서 실행되는 오브젝트가 많으면 최대값이 달라집니다.
이 문서에 명시된 수치는 Red Hat의 테스트 방법론, 설정, 구성, 튜닝을 기반으로 한 것입니다. 고유한 개별 설정 및 환경에 따라 수치가 달라질 수 있습니다.
환경을 계획하는 동안 노드당 몇 개의 Pod가 적합할 것으로 예상되는지 결정하십시오.
required pods per cluster / pods per node = total number of nodes needed
노드당 기본 최대 Pod 수는 250입니다. 하지만 노드에 적합한 Pod 수는 애플리케이션 자체에 따라 달라집니다. "애플리케이션 요구 사항에 따라 환경을 계획하는 방법"에 설명된 대로 애플리케이션의 메모리, CPU 및 스토리지 요구 사항을 고려하십시오.
시나리오 예
클러스터당 2,200개의 Pod로 클러스터 규모를 지정하려면 노드당 최대 500개의 Pod가 있다고 가정하여 최소 5개의 노드가 있어야 합니다.
2200 / 500 = 4.4
노드 수를 20으로 늘리면 Pod 배포는 노드당 110개 Pod로 변경됩니다.
2200 / 20 = 110
다음과 같습니다.
required pods per cluster / total number of nodes = expected pods per node
OpenShift Container Platform에는 기본적으로 모든 작업자 노드에서 실행되는 SDN, DNS, Operator 등과 같은 여러 시스템 Pod가 제공됩니다. 따라서 위의 공식의 결과는 다를 수 있습니다.
2.4. 애플리케이션 요구사항에 따라 환경을 계획하는 방법
예에 나온 애플리케이션 환경을 고려해 보십시오.
| Pod 유형 | Pod 수량 | 최대 메모리 | CPU 코어 수 | 영구 스토리지 |
|---|---|---|---|---|
| apache | 100 | 500MB | 0.5 | 1GB |
| node.js | 200 | 1GB | 1 | 1GB |
| postgresql | 100 | 1GB | 2 | 10GB |
| JBoss EAP | 100 | 1GB | 1 | 1GB |
예상 요구사항은 CPU 코어 550개, RAM 450GB 및 스토리지 1.4TB입니다.
노드의 인스턴스 크기는 기본 설정에 따라 높게 또는 낮게 조정될 수 있습니다. 노드에서는 리소스 초과 커밋이 발생하는 경우가 많습니다. 이 배포 시나리오에서는 동일한 양의 리소스를 제공하는 데 더 작은 노드를 추가로 실행하도록 선택할 수도 있고 더 적은 수의 더 큰 노드를 실행하도록 선택할 수도 있습니다. 운영 민첩성 및 인스턴스당 비용과 같은 요인을 고려해야 합니다.
| 노드 유형 | 수량 | CPU | RAM(GB) |
|---|---|---|---|
| 노드(옵션 1) | 100 | 4 | 16 |
| 노드(옵션 2) | 50 | 8 | 32 |
| 노드(옵션 3) | 25 | 16 | 64 |
어떤 애플리케이션은 초과 커밋된 환경에 적합하지만 어떤 애플리케이션은 그렇지 않습니다. 대부분의 Java 애플리케이션과 대규모 페이지를 사용하는 애플리케이션은 초과 커밋에 적합하지 않은 애플리케이션의 예입니다. 해당 메모리는 다른 애플리케이션에 사용할 수 없습니다. 위의 예에 나온 환경에서는 초과 커밋이 약 30%이며, 이는 일반적으로 나타나는 비율입니다.
애플리케이션 Pod는 환경 변수 또는 DNS를 사용하여 서비스에 액세스할 수 있습니다. 환경 변수를 사용하는 경우 노드에서 Pod가 실행될 때 활성 서비스마다 kubelet을 통해 변수를 삽입합니다. 클러스터 인식 DNS 서버는 새로운 서비스의 Kubernetes API를 확인하고 각각에 대해 DNS 레코드 세트를 생성합니다. 클러스터 전체에서 DNS가 활성화된 경우 모든 Pod가 자동으로 해당 DNS 이름을 통해 서비스를 확인할 수 있어야 합니다. 서비스가 5,000개를 넘어야 하는 경우 DNS를 통한 서비스 검색을 사용할 수 있습니다. 서비스 검색에 환경 변수를 사용하는 경우 네임스페이스에서 서비스가 5,000개를 넘은 후 인수 목록이 허용되는 길이를 초과하면 Pod 및 배포가 실패하기 시작합니다. 이 문제를 해결하려면 배포의 서비스 사양 파일에서 서비스 링크를 비활성화하십시오.
---
apiVersion: template.openshift.io/v1
kind: Template
metadata:
name: deployment-config-template
creationTimestamp:
annotations:
description: This template will create a deploymentConfig with 1 replica, 4 env vars and a service.
tags: ''
objects:
- apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
name: deploymentconfig${IDENTIFIER}
spec:
template:
metadata:
labels:
name: replicationcontroller${IDENTIFIER}
spec:
enableServiceLinks: false
containers:
- name: pause${IDENTIFIER}
image: "${IMAGE}"
ports:
- containerPort: 8080
protocol: TCP
env:
- name: ENVVAR1_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR2_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR3_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR4_${IDENTIFIER}
value: "${ENV_VALUE}"
resources: {}
imagePullPolicy: IfNotPresent
capabilities: {}
securityContext:
capabilities: {}
privileged: false
restartPolicy: Always
serviceAccount: ''
replicas: 1
selector:
name: replicationcontroller${IDENTIFIER}
triggers:
- type: ConfigChange
strategy:
type: Rolling
- apiVersion: v1
kind: Service
metadata:
name: service${IDENTIFIER}
spec:
selector:
name: replicationcontroller${IDENTIFIER}
ports:
- name: serviceport${IDENTIFIER}
protocol: TCP
port: 80
targetPort: 8080
clusterIP: ''
type: ClusterIP
sessionAffinity: None
status:
loadBalancer: {}
parameters:
- name: IDENTIFIER
description: Number to append to the name of resources
value: '1'
required: true
- name: IMAGE
description: Image to use for deploymentConfig
value: gcr.io/google-containers/pause-amd64:3.0
required: false
- name: ENV_VALUE
description: Value to use for environment variables
generate: expression
from: "[A-Za-z0-9]{255}"
required: false
labels:
template: deployment-config-template
네임스페이스에서 실행할 수 있는 애플리케이션 Pod 수는 서비스 검색에 환경 변수가 사용될 때 서비스 수와 서비스 이름의 길이에 따라 달라집니다. ARG_MAX 는 새 프로세스의 최대 인수 길이를 정의하고 기본적으로 2097152바이트(2MiB)로 설정됩니다. Kubelet은 네임스페이스에서 실행되도록 예약된 각 pod에 환경 변수를 삽입합니다. 여기에는 다음이 포함됩니다.
-
<SERVICE_NAME>_SERVICE_HOST=<IP> -
<SERVICE_NAME>_SERVICE_PORT=<PORT> -
<SERVICE_NAME>_PORT=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_PROTO=tcp -
<SERVICE_NAME>_PORT_<PORT>_TCP_PORT=<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_ADDR=<ADDR>
인수 길이가 허용된 값을 초과하고 서비스 이름의 문자 수에 영향을 미치는 경우 네임스페이스의 Pod가 실패합니다. 예를 들어, 5000개의 서비스가 있는 네임스페이스에서 서비스 이름의 제한은 33자이며, 네임스페이스에서 5000개의 Pod를 실행할 수 있습니다.
3장. IBM Z 및 IBM LinuxONE 환경에 대한 호스트 관련 권장 사례
이 주제에서는 IBM Z® 및 IBM® LinuxONE의 OpenShift Container Platform에 대한 권장 호스트 사례를 설명합니다.
s390x 아키텍처는 여러 측면에서 고유합니다. 따라서 여기에 작성된 일부 권장 사항은 다른 플랫폼에 적용되지 않을 수 있습니다.
달리 명시되지 않는 한, 이러한 사례는 IBM Z® 및 IBM® LinuxONE의 z/VM 및 RHEL(Red Hat Enterprise Linux) KVM 설치에 모두 적용됩니다.
3.1. CPU 과다 할당 관리
고도로 가상화된 IBM Z® 환경에서 인프라 설정 및 크기를 신중하게 계획해야 합니다. 가상화의 가장 중요한 기능 중 하나는 리소스 과다 할당을 수행하고 하이퍼바이저 수준에서 실제로 사용할 수 있는 것보다 가상 머신에 더 많은 리소스를 할당하는 기능입니다. 이는 매우 워크로드에 따라 다르며 모든 설정에 적용할 수 있는 골든 규칙이 없습니다.
설정에 따라 CPU 과다 할당과 관련된 다음 모범 사례를 고려하십시오.
- LPAR 수준(PR/SM 하이퍼바이저)에서 사용 가능한 모든 물리적 코어(IFL)를 각 LPAR에 할당하지 마십시오. 예를 들어 4개의 물리적 IFL을 사용할 수 있는 경우 각각 4개의 논리 IFL을 사용하여 3개의 LPAR을 정의해서는 안 됩니다.
- LPAR 공유 및 가중치를 확인하고 이해하십시오.
- 과도한 수의 가상 CPU는 성능에 부정적인 영향을 미칠 수 있습니다. 논리 프로세서보다 게스트에 더 많은 가상 프로세서를 정의하지 마십시오.
- 더 이상 최대 워크로드가 아닌 게스트당 가상 프로세서 수를 구성합니다.
- 소규모를 시작하고 워크로드를 모니터링합니다. 필요한 경우 vCPU 수를 늘리십시오.
- 모든 워크로드가 높은 오버 커밋 비율에 적합한 것은 아닙니다. 워크로드가 CPU 집약적인 경우 성능 문제 없이 높은 비율을 달성할 수 없습니다. I/O 집약적인 워크로드는 과다 할당 비율이 높은 경우에도 일관된 성능을 유지할 수 있습니다.
3.2. 투명한 대규모 페이지 비활성화
THP(Transparent Huge Pages)는 대규모 페이지를 생성, 관리 및 사용하는 대부분의 측면을 자동화하려고 합니다. THP는 대규모 페이지를 자동으로 관리하므로 모든 유형의 워크로드에 대해 항상 최적으로 처리되는 것은 아닙니다. THP는 많은 애플리케이션이 자체적으로 대규모 페이지를 처리하므로 성능 회귀를 유발할 수 있습니다. 따라서 THP를 비활성화하는 것이 좋습니다.
3.3. Receive Flow Steering으로 네트워킹 성능 향상
RFS( Flow Steering)는 네트워크 대기 시간을 추가로 줄여RP(Receive Packet Steering)를 확장합니다. RFS는 기술적으로 RPS를 기반으로 하며 CPU 캐시 적중률을 증가시켜 패킷 처리의 효율성을 향상시킵니다. RFS는 이를 달성하고 또한 계산에 가장 편리한 CPU를 확인하여 CPU 내에서 캐시 적중을 더 많이 발생시킬 수 있도록 큐 길이를 고려합니다. 따라서 CPU 캐시가 무효화되고 캐시를 다시 빌드하는 데 더 적은 사이클이 필요합니다. 이렇게 하면 패킷 처리 실행 시간을 줄일 수 있습니다.
3.3.1. MCO(Machine Config Operator)를 사용하여 RFS 활성화
프로세스
다음 MCO 샘플 프로필을 YAML 파일에 복사합니다. 예를 들어
enable-rfs.yaml은 다음과 같습니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 50-enable-rfs spec: config: ignition: version: 2.2.0 storage: files: - contents: source: data:text/plain;charset=US-ASCII,%23%20turn%20on%20Receive%20Flow%20Steering%20%28RFS%29%20for%20all%20network%20interfaces%0ASUBSYSTEM%3D%3D%22net%22%2C%20ACTION%3D%3D%22add%22%2C%20RUN%7Bprogram%7D%2B%3D%22/bin/bash%20-c%20%27for%20x%20in%20/sys/%24DEVPATH/queues/rx-%2A%3B%20do%20echo%208192%20%3E%20%24x/rps_flow_cnt%3B%20%20done%27%22%0A filesystem: root mode: 0644 path: /etc/udev/rules.d/70-persistent-net.rules - contents: source: data:text/plain;charset=US-ASCII,%23%20define%20sock%20flow%20enbtried%20for%20%20Receive%20Flow%20Steering%20%28RFS%29%0Anet.core.rps_sock_flow_entries%3D8192%0A filesystem: root mode: 0644 path: /etc/sysctl.d/95-enable-rps.confMCO 프로필을 생성합니다.
$ oc create -f enable-rfs.yaml
50-enable-rfs항목이 나열되어 있는지 확인합니다.$ oc get mc
비활성화하려면 다음을 입력합니다.
$ oc delete mc 50-enable-rfs
3.4. 네트워킹 설정 선택
네트워킹 스택은 OpenShift Container Platform과 같은 Kubernetes 기반 제품의 가장 중요한 구성 요소 중 하나입니다. IBM Z® 설정의 경우 네트워킹 설정은 선택한 하이퍼바이저에 따라 다릅니다. 워크로드 및 애플리케이션에 따라 가장 적합한 것은 일반적으로 사용 사례 및 트래픽 패턴에 따라 변경됩니다.
설정에 따라 다음 모범 사례를 고려하십시오.
- 트래픽 패턴을 최적화하기 위해 네트워킹 장치와 관련된 모든 옵션을 고려하십시오. OSA-Express, RoCE Express, HiperSockets, z/VM VSwitch, Linux Bridge(KVM)의 이점을 살펴보고 어떤 옵션을 설정하는데 가장 큰 이점이 있는지 확인하십시오.
- 항상 사용 가능한 최신 NIC 버전을 사용합니다. 예를 들어 OSA Express 7S 10GbE는 모두 10GbE 어댑터이지만 트랜잭션 워크로드 유형의 OSA Express 6S 10GbE에 비해 큰 개선 사항을 보여줍니다.
- 각 가상 스위치는 추가 대기 시간 계층을 추가합니다.
- 로드 밸런서는 클러스터 외부의 네트워크 통신에 중요한 역할을 합니다. 애플리케이션에 중요한 경우 프로덕션 수준의 하드웨어 로드 밸런서를 사용하는 것이 좋습니다.
- OpenShift Container Platform SDN은 네트워킹 성능에 영향을 미치는 흐름과 규칙을 도입합니다. 통신이 중요한 서비스의 현지성을 활용하려면 Pod의 특성과 배치를 고려해야 합니다.
- 성능과 기능 간의 균형을 조정합니다.
3.5. z/VM에서 HyperPAV를 사용하여 높은 디스크 성능 보장
DASD 및 ECKD 장치는 IBM Z® 환경에서 일반적으로 사용되는 디스크 유형입니다. z/VM 환경의 일반적인 OpenShift Container Platform 설정에서 DASD 디스크는 일반적으로 노드의 로컬 스토리지를 지원하는 데 사용됩니다. HyperPAV 별칭 장치를 설정하여 더 많은 처리량과 z/VM 게스트를 지원하는 DASD 디스크에 대해 전반적으로 더 나은 I/O 성능을 제공할 수 있습니다.
로컬 스토리지 장치에 HyperPAV를 사용하면 상당한 성능 이점이 있습니다. 그러나 처리량과 CPU 비용 간에 절충이 있다는 점에 유의해야 합니다.
3.5.1. MCO(Machine Config Operator)를 사용하여 z/VM full-pack Minidisk를 사용하여 노드에서 HyperPAV 별칭을 활성화합니다.
전체 팩 미니 디스크를 사용하는 z/VM 기반 OpenShift Container Platform 설정의 경우 모든 노드에서 HyperPAV 별칭을 활성화하여 MCO 프로필의 이점을 활용할 수 있습니다. 컨트롤 플레인 및 컴퓨팅 노드 모두에 YAML 구성을 추가해야 합니다.
프로세스
다음 MCO 샘플 프로필을 컨트롤 플레인 노드의 YAML 파일에 복사합니다. 예를 들어
05-master-kernelarg-hpav.yaml:$ cat 05-master-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 05-master-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805다음 MCO 샘플 프로필을 컴퓨팅 노드의 YAML 파일에 복사합니다. 예를 들어
05-worker-kernelarg-hpav.yaml:$ cat 05-worker-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805참고장치 ID에 맞게
rd.dasd인수를 수정해야 합니다.MCO 프로필을 생성합니다.
$ oc create -f 05-master-kernelarg-hpav.yaml
$ oc create -f 05-worker-kernelarg-hpav.yaml
비활성화하려면 다음을 입력합니다.
$ oc delete -f 05-master-kernelarg-hpav.yaml
$ oc delete -f 05-worker-kernelarg-hpav.yaml
3.6. IBM Z 호스트의 RHEL KVM 권장 사항
KVM 가상 서버 환경 최적화는 가상 서버의 워크로드와 사용 가능한 리소스에 따라 크게 달라집니다. 한 환경에서 성능을 향상시키는 동일한 동작이 다른 환경에서 부정적인 영향을 미칠 수 있습니다. 특정 설정에 가장 적합한 균형을 찾는 것은 어려울 수 있으며 종종 실험이 포함됩니다.
다음 섹션에서는 IBM Z® 및 IBM® LinuxONE 환경에서 RHEL KVM과 함께 OpenShift Container Platform을 사용할 때 몇 가지 모범 사례를 소개합니다.
3.6.1. 가상 블록 장치에 I/O 스레드 사용
가상 블록 장치를 I/O 스레드를 사용하려면 가상 서버에 대해 하나 이상의 I/O 스레드와 각 가상 블록 장치가 이러한 I/O 스레드 중 하나를 사용하도록 구성해야 합니다.
다음 예제에서는 연속 10진수 스레드 ID 1, 2, 3으로 세 개의 I/O 스레드를 구성하려면 <iothreads >3</iothreads>를 지정합니다. iothread="2" 매개변수는 ID 2와 함께 I/O 스레드를 사용할 디스크 장치의 드라이버 요소를 지정합니다.
I/O 스레드 사양 샘플
... <domain> <iothreads>3</iothreads>1 ... <devices> ... <disk type="block" device="disk">2 <driver ... iothread="2"/> </disk> ... </devices> ... </domain>
스레드는 디스크 장치에 대한 I/O 작업의 성능을 향상시킬 수 있지만 메모리 및 CPU 리소스도 사용합니다. 동일한 스레드를 사용하도록 여러 장치를 구성할 수 있습니다. 스레드를 장치에 가장 잘 매핑하는 것은 사용 가능한 리소스 및 워크로드에 따라 다릅니다.
적은 수의 I/O 스레드로 시작합니다. 종종 모든 디스크 장치에 대한 단일 I/O 스레드만으로도 충분합니다. 가상 CPU 수보다 많은 스레드를 구성하지 말고 유휴 스레드를 구성하지 마십시오.
virsh iothreadadd 명령을 사용하여 실행 중인 가상 서버에 특정 스레드 ID가 있는 I/O 스레드를 추가할 수 있습니다.
3.6.2. 가상 SCSI 장치 방지
SCSI별 인터페이스를 통해 장치를 처리해야 하는 경우에만 가상 SCSI 장치를 구성합니다. 호스트의 백업과 관계없이 가상 SCSI 장치가 아닌 가상 블록 장치로 디스크 공간을 구성합니다.
그러나 다음과 같은 SCSI별 인터페이스가 필요할 수 있습니다.
- 호스트에서 SCSI 연결 테드라이브를 위한 LUN입니다.
- 가상 DVD 드라이브에 마운트된 호스트 파일 시스템의 DVD ISO 파일입니다.
3.6.3. 디스크에 대한 게스트 캐싱 구성
호스트가 아닌 게스트에서 캐싱하도록 디스크 장치를 구성합니다.
디스크 장치의 드라이버 요소에 cache="none" 및 io="native" 매개변수가 포함되어 있는지 확인합니다.
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" iothread="1"/>
...
</disk>3.6.4. 메모리 balloon 장치 제외
동적 메모리 크기가 필요하지 않은 경우 메모리 balloon 장치를 정의하지 말고 libvirt가 생성되지 않도록 합니다. memballoon 매개변수를 도메인 구성 XML 파일에 devices 요소의 자식으로 포함합니다.
활성 프로필 목록을 확인합니다.
<memballoon model="none"/>
3.6.5. 호스트 스케줄러의 CPU 마이그레이션 알고리즘 조정
영향을 이해하는 전문가인 경우 스케줄러 설정을 변경하지 마십시오. 프로덕션 시스템을 테스트하지 않고 변경 사항을 적용하고 의도한 효과가 있는지 확인하지 마십시오.
kernel.sched_migration_cost_ns 매개변수는 나노초 단위의 시간 간격을 지정합니다. 작업을 마지막으로 실행한 후 이 간격이 만료될 때까지 CPU 캐시가 유용한 콘텐츠로 간주됩니다. 이 간격을 늘리면 작업 마이그레이션이 줄어듭니다. 기본값은 500000 ns입니다.
실행 가능한 프로세스가 있을 때 CPU 유휴 시간이 예상보다 길면 이 간격을 줄입니다. CPU 또는 노드 간에 작업이 너무 자주 끊기면 늘리십시오.
간격을 60000 ns로 동적으로 설정하려면 다음 명령을 입력합니다.
# sysctl kernel.sched_migration_cost_ns=60000
값을 60000 ns로 영구적으로 변경하려면 /etc/sysctl.conf 에 다음 항목을 추가합니다.
kernel.sched_migration_cost_ns=60000
3.6.6. cpuset cgroup 컨트롤러 비활성화
이 설정은 cgroups 버전이 1인 KVM 호스트에만 적용됩니다. 호스트에서 CPU 핫플러그를 활성화하려면 cgroup 컨트롤러를 비활성화합니다.
프로세스
-
선택한 편집기에서
/etc/libvirt/qemu.conf를 엽니다. -
cgroup_controllers행으로 이동합니다. - 전체 행을 복제하고 복사에서 선행 숫자 기호(#)를 제거합니다.
다음과 같이
cpuset항목을 제거합니다.cgroup_controllers = [ "cpu", "devices", "memory", "blkio", "cpuacct" ]
새 설정을 적용하려면 libvirtd 데몬을 다시 시작해야 합니다.
- 모든 가상 머신을 중지합니다.
다음 명령을 실행합니다.
# systemctl restart libvirtd
- 가상 머신을 재시작합니다.
이 설정은 호스트가 재부팅해도 유지됩니다.
3.6.7. 유휴 가상 CPU의 폴링 기간 조정
가상 CPU가 유휴 상태가 되면 KVM은 호스트 리소스를 할당하기 전에 가상 CPU의 작동 상태를 폴링합니다. /sys/module/kvm/parameters/halt_poll_ns 에서 sysfs에서 폴링이 수행되는 시간 간격을 지정할 수 있습니다. 지정된 시간 동안 폴링은 리소스 사용을 희생하여 가상 CPU의 레이턴시를 줄입니다. 워크로드에 따라 폴링 시간이 길거나 짧은 경우 유용할 수 있습니다. 시간 간격은 나노초 단위로 지정됩니다. 기본값은 50000 ns입니다.
낮은 CPU 사용을 최적화하려면 작은 값을 입력하거나 0을 작성하여 폴링을 비활성화합니다.
# echo 0 > /sys/module/kvm/parameters/halt_poll_ns
짧은 대기 시간을 최적화하려면 트랜잭션 워크로드의 경우 큰 값을 입력합니다.
# echo 80000 > /sys/module/kvm/parameters/halt_poll_ns
4장. Node Tuning Operator 사용
Node Tuning Operator에 대해 알아보고, Node Tuning Operator를 사용하여 Tuned 데몬을 오케스트레이션하고 노드 수준 튜닝을 관리하는 방법도 알아봅니다.
4.1. Node Tuning Operator 정보
Node Tuning Operator는 TuneD 데몬을 오케스트레이션하여 노드 수준 튜닝을 관리하고 Performance Profile 컨트롤러를 사용하여 대기 시간이 짧은 성능을 달성하는 데 도움이 됩니다. 대부분의 고성능 애플리케이션에는 일정 수준의 커널 튜닝이 필요합니다. Node Tuning Operator는 노드 수준 sysctls 사용자에게 통합 관리 인터페이스를 제공하며 사용자의 필요에 따라 지정되는 사용자 정의 튜닝을 추가할 수 있는 유연성을 제공합니다.
Operator는 OpenShift Container Platform의 컨테이너화된 TuneD 데몬을 Kubernetes 데몬 세트로 관리합니다. 클러스터에서 실행되는 모든 컨테이너화된 TuneD 데몬에 사용자 정의 튜닝 사양이 데몬이 이해할 수 있는 형식으로 전달되도록 합니다. 데몬은 클러스터의 모든 노드에서 노드당 하나씩 실행됩니다.
컨테이너화된 TuneD 데몬을 통해 적용되는 노드 수준 설정은 프로필 변경을 트리거하는 이벤트 시 또는 컨테이너화된 TuneD 데몬이 종료 신호를 수신하고 처리하여 정상적으로 종료될 때 롤백됩니다.
Node Tuning Operator는 Performance Profile 컨트롤러를 사용하여 OpenShift Container Platform 애플리케이션에 대한 짧은 대기 시간 성능을 달성하기 위해 자동 튜닝을 구현합니다.
클러스터 관리자는 다음과 같은 노드 수준 설정을 정의하도록 성능 프로필을 구성합니다.
- 커널을 kernel-rt로 업데이트합니다.
- 하우스키핑을 위한 CPU 선택.
- 실행 중인 워크로드를 위한 CPU 선택.
현재 cgroup v2에서는 CPU 부하 분산을 비활성화하는 것은 지원되지 않습니다. 따라서 cgroup v2가 활성화된 경우 성능 프로필에서 원하는 동작이 없을 수 있습니다. 성능 프로필을 사용하는 경우에는 cgroup v2를 활성화하는 것은 권장되지 않습니다.
버전 4.1 이상에서는 Node Tuning Operator가 표준 OpenShift Container Platform 설치에 포함되어 있습니다.
이전 버전의 OpenShift Container Platform에서는 Performance Addon Operator를 사용하여 OpenShift 애플리케이션에 대해 짧은 대기 시간 성능을 달성하기 위해 자동 튜닝을 구현했습니다. OpenShift Container Platform 4.11 이상에서 이 기능은 Node Tuning Operator의 일부입니다.
4.2. Node Tuning Operator 사양 예에 액세스
이 프로세스를 사용하여 Node Tuning Operator 사양 예에 액세스하십시오.
프로세스
다음 명령을 실행하여 Node Tuning Operator 사양 예제에 액세스합니다.
oc get tuned.tuned.openshift.io/default -o yaml -n openshift-cluster-node-tuning-operator
기본 CR은 OpenShift Container Platform 플랫폼의 표준 노드 수준 튜닝을 제공하기 위한 것이며 Operator 관리 상태를 설정하는 경우에만 수정할 수 있습니다. Operator는 기본 CR에 대한 다른 모든 사용자 정의 변경사항을 덮어씁니다. 사용자 정의 튜닝의 경우 고유한 Tuned CR을 생성합니다. 새로 생성된 CR은 노드 또는 Pod 라벨 및 프로필 우선 순위에 따라 OpenShift Container Platform 노드에 적용된 기본 CR 및 사용자 정의 튜닝과 결합됩니다.
특정 상황에서는 Pod 라벨에 대한 지원이 필요한 튜닝을 자동으로 제공하는 편리한 방법일 수 있지만 이러한 방법은 권장되지 않으며 특히 대규모 클러스터에서는 이러한 방법을 사용하지 않는 것이 좋습니다. 기본 Tuned CR은 Pod 라벨이 일치되지 않은 상태로 제공됩니다. Pod 라벨이 일치된 상태로 사용자 정의 프로필이 생성되면 해당 시점에 이 기능이 활성화됩니다. Pod 레이블 기능은 Node Tuning Operator의 향후 버전에서 더 이상 사용되지 않습니다.
4.3. 클러스터에 설정된 기본 프로필
다음은 클러스터에 설정된 기본 프로필입니다.
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Optimize systems running OpenShift (provider specific parent profile)
include=-provider-${f:exec:cat:/var/lib/tuned/provider},openshift
name: openshift
recommend:
- profile: openshift-control-plane
priority: 30
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
- profile: openshift-node
priority: 40
OpenShift Container Platform 4.9부터 모든 OpenShift TuneD 프로필이 TuneD 패키지와 함께 제공됩니다. oc exec 명령을 사용하여 이러한 프로필의 내용을 볼 수 있습니다.
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;4.4. TuneD 프로필이 적용되었는지 검증
클러스터 노드에 적용되는 TuneD 프로필을 확인합니다.
$ oc get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator
출력 예
NAME TUNED APPLIED DEGRADED AGE master-0 openshift-control-plane True False 6h33m master-1 openshift-control-plane True False 6h33m master-2 openshift-control-plane True False 6h33m worker-a openshift-node True False 6h28m worker-b openshift-node True False 6h28m
-
NAME: Profile 오브젝트의 이름입니다. 노드당 하나의 Profile 오브젝트가 있고 해당 이름이 일치합니다. -
TUNED: 적용할 TuneD 프로파일의 이름입니다. -
APPLIED: TuneD 데몬이 원하는 프로필을 적용한 경우True입니다. (True/False/Unknown). -
DEGRADED: TuneD 프로파일 적용 중에 오류가 보고된 경우 (True)./False/Unknown -
AGE: Profile 개체 생성 이후 경과 시간입니다.
ClusterOperator/node-tuning 오브젝트에는 Operator 및 해당 노드 에이전트의 상태에 대한 유용한 정보도 포함되어 있습니다. 예를 들어 Operator 구성 오류는 ClusterOperator/node-tuning 상태 메시지에 의해 보고됩니다.
ClusterOperator/node-tuning 오브젝트에 대한 상태 정보를 가져오려면 다음 명령을 실행합니다.
$ oc get co/node-tuning -n openshift-cluster-node-tuning-operator
출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE node-tuning 4.15.1 True False True 60m 1/5 Profiles with bootcmdline conflict
ClusterOperator/node-tuning 또는 프로파일 오브젝트의 상태가 DEGRADED 인 경우 Operator 또는 피연산자 로그에 추가 정보가 제공됩니다.
4.5. 사용자 정의 튜닝 사양
Operator의 CR(사용자 정의 리소스)에는 두 가지 주요 섹션이 있습니다. 첫 번째 섹션인 profile:은 TuneD 프로필 및 해당 이름의 목록입니다. 두 번째인 recommend:은 프로필 선택 논리를 정의합니다.
여러 사용자 정의 튜닝 사양은 Operator의 네임스페이스에 여러 CR로 존재할 수 있습니다. 새로운 CR의 존재 또는 오래된 CR의 삭제는 Operator에서 탐지됩니다. 기존의 모든 사용자 정의 튜닝 사양이 병합되고 컨테이너화된 TuneD 데몬의 해당 오브젝트가 업데이트됩니다.
관리 상태
Operator 관리 상태는 기본 Tuned CR을 조정하여 설정됩니다. 기본적으로 Operator는 Managed 상태이며 기본 Tuned CR에는 spec.managementState 필드가 없습니다. Operator 관리 상태에 유효한 값은 다음과 같습니다.
- Managed: 구성 리소스가 업데이트되면 Operator가 해당 피연산자를 업데이트합니다.
- Unmanaged: Operator가 구성 리소스에 대한 변경을 무시합니다.
- Removed: Operator가 프로비저닝한 해당 피연산자 및 리소스를 Operator가 제거합니다.
프로필 데이터
profile: 섹션에는 TuneD 프로필 및 해당 이름이 나열됩니다.
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings권장 프로필
profile: 선택 논리는 CR의 recommend: 섹션에 의해 정의됩니다. recommend: 섹션은 선택 기준에 따라 프로필을 권장하는 항목의 목록입니다.
recommend: <recommend-item-1> # ... <recommend-item-n>
목록의 개별 항목은 다음과 같습니다.
- machineConfigLabels: 1 <mcLabels> 2 match: 3 <match> 4 priority: <priority> 5 profile: <tuned_profile_name> 6 operand: 7 debug: <bool> 8 tunedConfig: reapply_sysctl: <bool> 9
- 1
- 선택 사항입니다.
- 2
- 키/값
MachineConfig라벨 사전입니다. 키는 고유해야 합니다. - 3
- 생략하면 우선 순위가 높은 프로필이 먼저 일치되거나
machineConfigLabels가 설정되어 있지 않으면 프로필이 일치하는 것으로 가정합니다. - 4
- 선택사항 목록입니다.
- 5
- 프로필 순서 지정 우선 순위입니다. 숫자가 작을수록 우선 순위가 높습니다(
0이 가장 높은 우선 순위임). - 6
- 일치에 적용할 TuneD 프로필입니다. 예를 들어
tuned_profile_1이 있습니다. - 7
- 선택적 피연산자 구성입니다.
- 8
- TuneD 데몬에 대해 디버깅을 켜거나 끕니다. on 또는
false의 경우 옵션은true입니다. 기본값은false입니다. - 9
- TuneD 데몬의 경우
reapply_sysctl기능을 켭니다. on 및false의 경우 옵션은true입니다.
<match>는 다음과 같이 재귀적으로 정의되는 선택사항 목록입니다.
- label: <label_name> 1 value: <label_value> 2 type: <label_type> 3 <match> 4
<match>를 생략하지 않으면 모든 중첩 <match> 섹션도 true로 평가되어야 합니다. 생략하면 false로 가정하고 해당 <match> 섹션이 있는 프로필을 적용하지 않거나 권장하지 않습니다. 따라서 중첩(하위 <match> 섹션)은 논리 AND 연산자 역할을 합니다. 반대로 <match> 목록의 항목이 일치하면 전체 <match> 목록이 true로 평가됩니다. 따라서 이 목록이 논리 OR 연산자 역할을 합니다.
machineConfigLabels가 정의되면 지정된 recommend: 목록 항목에 대해 머신 구성 풀 기반 일치가 설정됩니다. <mcLabels>는 머신 구성의 라벨을 지정합니다. 머신 구성은 <tuned_profile_name> 프로필에 대해 커널 부팅 매개변수와 같은 호스트 설정을 적용하기 위해 자동으로 생성됩니다. 여기에는 <mcLabels>와 일치하는 머신 구성 선택기가 있는 모든 머신 구성 풀을 찾고 머신 구성 풀이 할당된 모든 노드에서 <tuned_profile_name> 프로필을 설정하는 작업이 포함됩니다. 마스터 및 작업자 역할이 모두 있는 노드를 대상으로 하려면 마스터 역할을 사용해야 합니다.
목록 항목 match 및 machineConfigLabels는 논리 OR 연산자로 연결됩니다. match 항목은 단락 방식으로 먼저 평가됩니다. 따라서 true로 평가되면 machineConfigLabels 항목이 고려되지 않습니다.
머신 구성 풀 기반 일치를 사용하는 경우 동일한 하드웨어 구성을 가진 노드를 동일한 머신 구성 풀로 그룹화하는 것이 좋습니다. 이 방법을 따르지 않으면 TuneD 피연산자가 동일한 머신 구성 풀을 공유하는 두 개 이상의 노드에 대해 충돌하는 커널 매개변수를 계산할 수 있습니다.
예: 노드 또는 Pod 라벨 기반 일치
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
위의 CR은 컨테이너화된 TuneD 데몬의 프로필 우선 순위에 따라 recommended.conf 파일로 변환됩니다. 우선 순위가 가장 높은 프로필(10)이 openshift-control-plane-es이므로 이 프로필을 첫 번째로 고려합니다. 지정된 노드에서 실행되는 컨테이너화된 TuneD 데몬은 tuned.openshift.io/elasticsearch 라벨이 설정된 동일한 노드에서 실행되는 Pod가 있는지 확인합니다. 없는 경우 전체 <match> 섹션이 false로 평가됩니다. 라벨이 있는 Pod가 있는 경우 <match> 섹션을 true로 평가하려면 노드 라벨도 node-role.kubernetes.io/master 또는 node-role.kubernetes.io/infra여야 합니다.
우선 순위가 10인 프로필의 라벨이 일치하면 openshift-control-plane-es 프로필이 적용되고 다른 프로필은 고려되지 않습니다. 노드/Pod 라벨 조합이 일치하지 않으면 두 번째로 높은 우선 순위 프로필(openshift-control-plane)이 고려됩니다. 컨테이너화된 TuneD Pod가 node-role.kubernetes.io/master 또는 node-role.kubernetes.io/infra. 라벨이 있는 노드에서 실행되는 경우 이 프로필이 적용됩니다.
마지막으로, openshift-node 프로필은 우선 순위가 가장 낮은 30입니다. 이 프로필에는 <match> 섹션이 없으므로 항상 일치합니다. 지정된 노드에서 우선 순위가 더 높은 다른 프로필이 일치하지 않는 경우 openshift-node 프로필을 설정하는 데 catch-all 프로필 역할을 합니다.
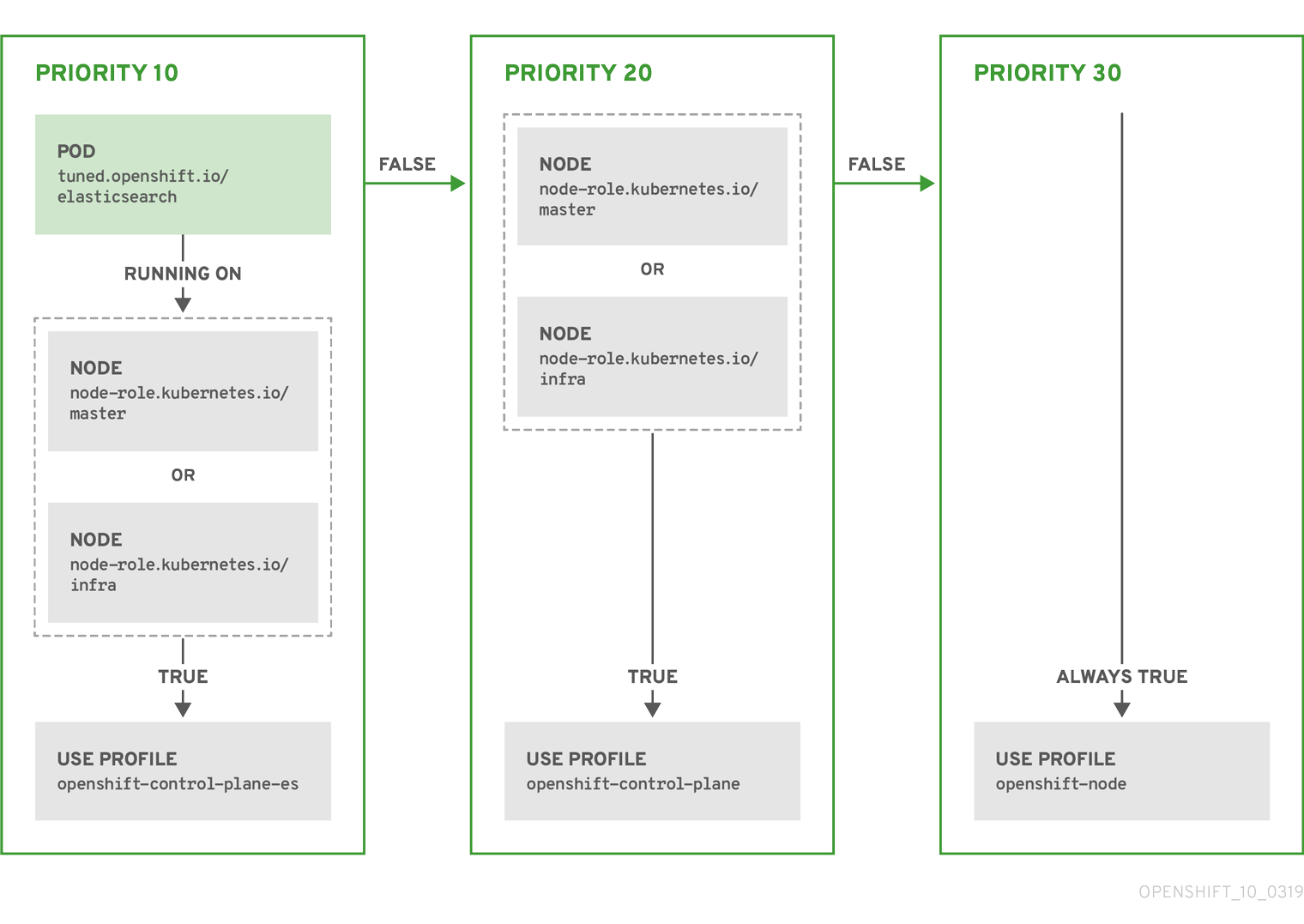
예: 머신 구성 풀 기반 일치
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-custom
노드 재부팅을 최소화하려면 머신 구성 풀의 노드 선택기와 일치하는 라벨로 대상 노드에 라벨을 지정한 후 위의 Tuned CR을 생성하고 마지막으로 사용자 정의 머신 구성 풀을 생성합니다.
클라우드 공급자별 TuneD 프로필
이 기능을 사용하면 모든 클라우드 공급자별 노드에 OpenShift Container Platform 클러스터의 지정된 클라우드 공급자에 특별히 맞춰진 TuneD 프로필을 편리하게 할당할 수 있습니다. 이 작업은 노드를 머신 구성 풀에 추가하거나 노드를 그룹화하지 않고 수행할 수 있습니다.
이 기능은 <cloud-provider> ://<cloud-provider-specific-id> 형식의 노드 오브젝트 값을 활용하고 NTO 피연산자 컨테이너의 < spec.provider IDcloud-provider> 값으로 파일을 씁니다. 그런 다음 이 파일의 내용은 해당 프로필이 존재하는 경우 TuneD에서 /var/lib/tuned/provider provider-<cloud-provider > 프로필을 로드하는 데 사용됩니다.
이제 및 openshift -control-planeopenshift-node 프로필에서 설정을 상속하는 openshift 프로파일이 조건부 프로필 로드를 사용하여 이 기능을 사용하도록 업데이트되었습니다. NTO 및 TuneD에는 현재 클라우드 공급자별 프로필이 포함되어 있지 않습니다. 그러나 모든 Cloud 공급자별 클러스터 노드에 적용할 사용자 지정 프로필 provider-<cloud- provider>를 생성할 수 있습니다.
GCE 클라우드 공급자 프로파일의 예
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: provider-gce
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=GCE Cloud provider-specific profile
# Your tuning for GCE Cloud provider goes here.
name: provider-gce
프로필 상속으로 인해 provider-< cloud-provider > 프로필에 지정된 모든 설정은 openshift 프로필 및 해당 하위 프로필이 덮어씁니다.
4.6. 사용자 정의 튜닝 예
기본 CR에서 TuneD 프로파일 사용
다음 CR에서는 tuned.openshift.io/ingress-node-label 레이블이 임의의 값으로 설정된 OpenShift Container Platform 노드에 대해 사용자 정의 노드 수준 튜닝을 적용합니다.
예: openshift-control-plane TuneD 프로필을 사용한 사용자 정의 튜닝
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: ingress
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=A custom OpenShift ingress profile
include=openshift-control-plane
[sysctl]
net.ipv4.ip_local_port_range="1024 65535"
net.ipv4.tcp_tw_reuse=1
name: openshift-ingress
recommend:
- match:
- label: tuned.openshift.io/ingress-node-label
priority: 10
profile: openshift-ingress
사용자 정의 프로필 작성자는 기본 TuneD CR에 제공된 기본 Tuned 데몬 프로필을 포함하는 것이 좋습니다. 위의 예에서는 기본 openshift-control-plane 프로필을 사용하여 작업을 수행합니다.
내장된 TuneD 프로필 사용
NTO 관리 데몬 세트가 성공적으로 롤아웃되면 TuneD 피연산자는 모두 동일한 버전의 TuneD 데몬을 관리합니다. 데몬에서 지원하는 기본 제공 TuneD 프로필을 나열하려면 다음 방식으로 TuneD Pod를 쿼리합니다.
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/ -name tuned.conf -printf '%h\n' | sed 's|^.*/||'
사용자 정의 튜닝 사양에서 이 명령으로 검색한 프로필 이름을 사용할 수 있습니다.
예: 기본 제공 hpc-compute TuneD 프로필 사용
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-hpc-compute
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile for HPC compute workloads
include=openshift-node,hpc-compute
name: openshift-node-hpc-compute
recommend:
- match:
- label: tuned.openshift.io/openshift-node-hpc-compute
priority: 20
profile: openshift-node-hpc-compute
기본 제공 hpc-compute 프로필 외에도 위의 예제에는 기본 Tuned CR 내에 제공된 openshift-node TuneD 데몬 프로필이 포함되어 컴퓨팅 노드에 OpenShift별 튜닝을 사용합니다.
호스트 수준 sysctl 덮어쓰기
/run/sysctl.d/, /etc/sysctl.d/, /etc/sysctl.conf 호스트 구성 파일을 사용하여 런타임 시 다양한 커널 매개변수를 변경할 수 있습니다. OpenShift Container Platform은 런타임 시 커널 매개변수를 설정하는 여러 호스트 구성 파일을 추가합니다(예: net.ipv[4-6]., fs.inotify., vm.max_map_count ). 이러한 런타임 매개변수는 kubelet 및 Operator가 시작되기 전에 시스템에 대한 기본 기능 튜닝을 제공합니다.
reapply_sysctl 옵션이 false 로 설정되지 않는 한 Operator는 이러한 설정을 재정의하지 않습니다. 이 옵션을 false 로 설정하면 사용자 지정 프로필이 적용된 후 TuneD 가 호스트 구성 파일의 설정을 적용하지 않습니다.
예: 호스트 수준 sysctl 덮어쓰기
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-no-reapply-sysctl
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift profile
include=openshift-node
[sysctl]
vm.max_map_count=>524288
name: openshift-no-reapply-sysctl
recommend:
- match:
- label: tuned.openshift.io/openshift-no-reapply-sysctl
priority: 15
profile: openshift-no-reapply-sysctl
operand:
tunedConfig:
reapply_sysctl: false
4.7. 지원되는 TuneD 데몬 플러그인
Tuned CR의 profile: 섹션에 정의된 사용자 정의 프로필을 사용하는 경우 [main] 섹션을 제외한 다음 TuneD 플러그인이 지원됩니다.
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
- bootloader
이러한 플러그인 중 일부에서 제공하는 동적 튜닝 기능은 지원되지 않습니다. 다음 TuneD 플러그인은 현재 지원되지 않습니다.
- script
- systemd
TuneD 부트로더 플러그인은 RHCOS(Red Hat Enterprise Linux CoreOS) 작업자 노드만 지원합니다.
4.8. 호스트 클러스터에서 노드 튜닝 구성
호스팅된 클러스터의 노드에 노드 수준 튜닝을 설정하려면 Node Tuning Operator를 사용할 수 있습니다. 호스팅된 컨트롤 플레인에서는 Tuned 오브젝트가 포함된 구성 맵을 생성하고 노드 풀에 해당 구성 맵을 참조하여 노드 튜닝을 구성할 수 있습니다.
절차
유효한 tuned 매니페스트가 포함된 구성 맵을 생성하고 노드 풀에서 매니페스트를 참조합니다. 다음 예에서
Tuned매니페스트는tuned-1-node-label노드 라벨이 임의의 값이 포함된 노드에서vm.dirty_ratio를 55로 설정하는 프로필을 정의합니다.tuned-1.yaml이라는 파일에 다음ConfigMap매니페스트를 저장합니다.apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profile참고Tuned 사양의
spec.recommend섹션에 있는 항목에 라벨을 추가하지 않으면 node-pool 기반 일치로 간주되므로spec.recommend섹션에서 가장 높은 우선 순위 프로필이 풀의 노드에 적용됩니다. Tuned.spec.recommend.match섹션에서 레이블 값을 설정하여 보다 세분화된 노드 레이블 기반 일치를 수행할 수 있지만 노드 레이블은 노드 풀의.spec.management.upgradeType값을InPlace로 설정하지 않는 한 업그레이드 중에 유지되지 않습니다.관리 클러스터에
ConfigMap오브젝트를 생성합니다.$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml
노드 풀을 편집하거나 하나를 생성하여 노드 풀의
spec.tuningConfig필드에서ConfigMap오브젝트를 참조합니다. 이 예에서는 2개의 노드가 포함된nodepool-1이라는NodePool이 하나만 있다고 가정합니다.apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...참고여러 노드 풀에서 동일한 구성 맵을 참조할 수 있습니다. 호스팅된 컨트롤 플레인에서 Node Tuning Operator는 노드 풀 이름과 네임스페이스의 해시를 Tuned CR 이름에 추가하여 구별합니다. 이 경우 동일한 호스트 클러스터에 대해 다른 Tuned CR에 동일한 이름의 여러 TuneD 프로필을 생성하지 마십시오.
검증
이제 Tuned 매니페스트가 포함된 ConfigMap 오브젝트를 생성하여 NodePool 에서 참조하므로 Node Tuning Operator가 Tuned 오브젝트를 호스팅된 클러스터에 동기화합니다. 정의된 Tuned 오브젝트와 각 노드에 적용되는 TuneD 프로필을 확인할 수 있습니다.
호스트 클러스터에서
Tuned오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operator
출력 예
NAME AGE default 7m36s rendered 7m36s tuned-1 65s
호스팅된 클러스터의
Profile오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator
출력 예
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s
참고사용자 지정 프로필이 생성되지 않으면 기본적으로
openshift-node프로필이 적용됩니다.튜닝이 올바르게 적용되었는지 확인하려면 노드에서 디버그 쉘을 시작하고 sysctl 값을 확인합니다.
$ oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio
출력 예
vm.dirty_ratio = 55
4.9. 커널 부팅 매개변수를 설정하여 호스팅된 클러스터의 고급 노드 튜닝
커널 부팅 매개변수를 설정해야 하는 호스팅된 컨트롤 플레인의 고급 튜닝의 경우 Node Tuning Operator를 사용할 수도 있습니다. 다음 예제에서는 대규모 페이지가 예약된 노드 풀을 생성하는 방법을 보여줍니다.
프로세스
크기가 2MB인 대규모 페이지 10개를 생성하기 위한
Tuned오브젝트 매니페스트가 포함된ConfigMap오브젝트를 생성합니다. 이ConfigMap매니페스트를tuned-hugepages.yaml이라는 파일에 저장합니다.apiVersion: v1 kind: ConfigMap metadata: name: tuned-hugepages namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 name: openshift-node-hugepages recommend: - priority: 20 profile: openshift-node-hugepages참고.spec.recommend.match필드는 의도적으로 비워 둡니다. 이 경우 이Tuned오브젝트는 이ConfigMap오브젝트가 참조되는 노드 풀의 모든 노드에 적용됩니다. 동일한 하드웨어 구성이 있는 노드를 동일한 노드 풀로 그룹화합니다. 그렇지 않으면 TuneD 피연산자가 동일한 노드 풀을 공유하는 두 개 이상의 노드에 대해 충돌하는 커널 매개변수를 계산할 수 있습니다.관리 클러스터에
ConfigMap오브젝트를 생성합니다.$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-hugepages.yaml
NodePool매니페스트 YAML 파일을 생성하고NodePool의 업그레이드 유형을 사용자 지정하고spec.tuningConfig섹션에서 생성한ConfigMap오브젝트를 참조합니다.NodePool매니페스트를 생성하고hcpCLI를 사용하여hugepages-nodepool.yaml이라는 파일에 저장합니다.NODEPOOL_NAME=hugepages-example INSTANCE_TYPE=m5.2xlarge NODEPOOL_REPLICAS=2 hcp create nodepool aws \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $NODEPOOL_REPLICAS \ --instance-type $INSTANCE_TYPE \ --render > hugepages-nodepool.yamlhugepages-nodepool.yaml파일에서.spec.management.upgradeType을InPlace로 설정하고.spec.tuningConfig를 설정하여 사용자가 생성한tuned-hugepagesConfigMap오브젝트를 참조합니다.apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: name: hugepages-nodepool namespace: clusters ... spec: management: ... upgradeType: InPlace ... tuningConfig: - name: tuned-hugepages참고새
MachineConfig오브젝트를 적용할 때 노드의 불필요한 재생성을 방지하려면.spec.management.upgradeType을InPlace로 설정합니다. 업그레이드교체유형을 사용하는 경우 노드가 완전히 삭제되고 TuneD 피연산자가 계산된 새 커널 부팅 매개변수를 적용할 때 새 노드가 대체될 수 있습니다.관리 클러스터에서
NodePool을 생성합니다.$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f hugepages-nodepool.yaml
검증
노드를 사용할 수 있게 되면 컨테이너화된 TuneD 데몬은 적용된 TuneD 프로필을 기반으로 필요한 커널 부팅 매개변수를 계산합니다. 생성된 MachineConfig 오브젝트를 적용하기 위해 노드를 준비하고 재부팅한 후 TuneD 프로필이 적용되고 커널 부팅 매개변수가 설정되었는지 확인할 수 있습니다.
호스트 클러스터에서
Tuned오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get tuned.tuned.openshift.io -n openshift-cluster-node-tuning-operator
출력 예
NAME AGE default 123m hugepages-8dfb1fed 1m23s rendered 123m
호스팅된 클러스터의
Profile오브젝트를 나열합니다.$ oc --kubeconfig="$HC_KUBECONFIG" get profile.tuned.openshift.io -n openshift-cluster-node-tuning-operator
출력 예
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 openshift-node True False 132m nodepool-1-worker-2 openshift-node True False 131m hugepages-nodepool-worker-1 openshift-node-hugepages True False 4m8s hugepages-nodepool-worker-2 openshift-node-hugepages True False 3m57s
새
NodePool의 작업자 노드 모두openshift-node-hugepages프로필이 적용됩니다.튜닝이 올바르게 적용되었는지 확인하려면 노드에서 디버그 쉘을 시작하고
/proc/cmdline을 확인합니다.$ oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host cat /proc/cmdline
출력 예
BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-... hugepagesz=2M hugepages=50
추가 리소스
호스팅된 컨트롤 플레인에 대한 자세한 내용은 호스팅 컨트롤 플레인 을 참조하십시오.
5장. CPU 관리자 및 토폴로지 관리자 사용
CPU 관리자는 CPU 그룹을 관리하고 워크로드를 특정 CPU로 제한합니다.
CPU 관리자는 다음과 같은 속성 중 일부가 포함된 워크로드에 유용합니다.
- 가능한 한 많은 CPU 시간이 필요합니다.
- 프로세서 캐시 누락에 민감합니다.
- 대기 시간이 짧은 네트워크 애플리케이션입니다.
- 다른 프로세스와 조정하고 단일 프로세서 캐시 공유를 통해 얻는 이점이 있습니다.
토폴로지 관리자는 동일한 NUMA(Non-Uniform Memory Access) 노드의 모든 QoS(Quality of Service) 클래스에 대해 CPU 관리자, 장치 관리자, 기타 힌트 공급자로부터 힌트를 수집하여 CPU, SR-IOV VF, 기타 장치 리소스 등의 Pod 리소스를 정렬합니다.
토폴로지 관리자는 토폴로지 관리자 정책 및 요청된 Pod 리소스에 따라 수집된 힌트의 토폴로지 정보를 사용하여 노드에서 Pod를 수락하거나 거부할 수 있는지 결정합니다.
토폴로지 관리자는 하드웨어 가속기를 사용하여 대기 시간이 중요한 실행과 처리량이 높은 병렬 계산을 지원하는 워크로드에 유용합니다.
토폴로지 관리자를 사용하려면 정적 정책을 사용하여 CPU 관리자를 구성해야 합니다.
5.1. CPU 관리자 설정
프로세스
선택사항: 노드에 레이블을 지정합니다.
# oc label node perf-node.example.com cpumanager=true
CPU 관리자를 활성화해야 하는 노드의
MachineConfigPool을 편집합니다. 이 예에서는 모든 작업자의 CPU 관리자가 활성화됩니다.# oc edit machineconfigpool worker
작업자 머신 구성 풀에 레이블을 추가합니다.
metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledKubeletConfig,cpumanager-kubeletconfig.yaml, CR(사용자 정의 리소스)을 생성합니다. 이전 단계에서 생성한 레이블을 참조하여 올바른 노드가 새 kubelet 구성으로 업데이트되도록 합니다.machineConfigPoolSelector섹션을 참조하십시오.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2동적 kubelet 구성을 생성합니다.
# oc create -f cpumanager-kubeletconfig.yaml
그러면 kubelet 구성에 CPU 관리자 기능이 추가되고 필요한 경우 MCO(Machine Config Operator)가 노드를 재부팅합니다. CPU 관리자를 활성화하는 데는 재부팅이 필요하지 않습니다.
병합된 kubelet 구성을 확인합니다.
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7
출력 예
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]작업자에서 업데이트된
kubelet.conf를 확인합니다.# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager
출력 예
cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2
코어를 하나 이상 요청하는 Pod를 생성합니다. 제한 및 요청 둘 다 해당 CPU 값이 정수로 설정되어야 합니다. 해당 숫자는 이 Pod 전용으로 사용할 코어 수입니다.
# cat cpumanager-pod.yaml
출력 예
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: cpumanager image: gcr.io/google_containers/pause:3.2 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] nodeSelector: cpumanager: "true"Pod를 생성합니다.
# oc create -f cpumanager-pod.yaml
레이블 지정한 노드에 Pod가 예약되어 있는지 검증합니다.
# oc describe pod cpumanager
출력 예
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=truecgroups가 올바르게 설정되었는지 검증합니다.pause프로세스의 PID(프로세스 ID)를 가져옵니다.# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pause
QoS(Quality of Service) 계층
Guaranteed의 Pod는kubepods.slice에 있습니다. 다른 QoS 계층의 Pod는kubepods의 하위cgroups에 있습니다.# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; done
출력 예
cpuset.cpus 1 tasks 32706
작업에 허용되는 CPU 목록을 확인합니다.
# grep ^Cpus_allowed_list /proc/32706/status
출력 예
Cpus_allowed_list: 1
GuaranteedPod용으로 할당된 코어에서는 시스템의 다른 Pod(이 경우burstableQoS 계층의 Pod)를 실행할 수 없는지 검증합니다.# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus 0 # oc describe node perf-node.example.com
출력 예
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)
이 VM에는 두 개의 CPU 코어가 있습니다.
system-reserved설정은 500밀리코어로 설정되었습니다. 즉,Node Allocatable양이 되는 노드의 전체 용량에서 한 코어의 절반이 감산되었습니다.Allocatable CPU는 1500 밀리코어임을 확인할 수 있습니다. 즉, Pod마다 하나의 전체 코어를 사용하므로 CPU 관리자 Pod 중 하나를 실행할 수 있습니다. 전체 코어는 1000밀리코어에 해당합니다. 두 번째 Pod를 예약하려고 하면 시스템에서 해당 Pod를 수락하지만 Pod가 예약되지 않습니다.NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
5.2. 토폴로지 관리자 정책
토폴로지 관리자는 CPU 관리자 및 장치 관리자와 같은 힌트 공급자로부터 토폴로지 힌트를 수집하고 수집된 힌트로 Pod 리소스를 정렬하는 방법으로 모든 QoS(Quality of Service) 클래스의 Pod 리소스를 정렬합니다.
토폴로지 관리자는 cpumanager-enabled 라는 KubeletConfig CR(사용자 정의 리소스)에서 할당하는 네 가지 할당 정책을 지원합니다.
none정책- 기본 정책으로, 토폴로지 정렬을 수행하지 않습니다.
best-effort정책-
best-effort토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 해당 컨테이너의 기본 NUMA 노드 선호도를 저장합니다. 선호도를 기본 설정하지 않으면 토폴로지 관리자가 해당 정보를 저장하고 노드에 대해 Pod를 허용합니다. restricted정책-
restricted토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 해당 컨테이너의 기본 NUMA 노드 선호도를 저장합니다. 선호도를 기본 설정하지 않으면 토폴로지 관리자가 노드에서 이 Pod를 거부합니다. 그러면 Pod는Terminated상태가 되고 Pod 허용 실패가 발생합니다. single-numa-node정책-
single-numa-node토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 단일 NUMA 노드 선호도가 가능한지 여부를 결정합니다. 가능한 경우 노드에 대해 Pod가 허용됩니다. 단일 NUMA 노드 선호도가 가능하지 않은 경우 토폴로지 관리자가 노드에서 Pod를 거부합니다. 그러면 Pod는 Terminated 상태가 되고 Pod 허용 실패가 발생합니다.
5.3. 토폴로지 관리자 설정
토폴로지 관리자를 사용하려면 cpumanager-enabled 라는 KubeletConfig CR(사용자 정의 리소스)에서 할당 정책을 구성해야 합니다. CPU 관리자를 설정한 경우 해당 파일이 존재할 수 있습니다. 파일이 없으면 파일을 생성할 수 있습니다.
사전 요구 사항
-
CPU 관리자 정책을
static으로 구성하십시오.
프로세스
토폴로지 관리자를 활성화하려면 다음을 수행합니다.
사용자 정의 리소스에서 토폴로지 관리자 할당 정책을 구성합니다.
$ oc edit KubeletConfig cpumanager-enabled
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node 2
5.4. Pod와 토폴로지 관리자 정책 간의 상호 작용
아래 Pod 사양의 예는 Pod와 토폴로지 관리자 간 상호 작용을 보여주는 데 도움이 됩니다.
다음 Pod는 리소스 요청 또는 제한이 지정되어 있지 않기 때문에 BestEffort QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
다음 Pod는 요청이 제한보다 작기 때문에 Burstable QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
선택한 정책이 none이 아니면 토폴로지 관리자는 이러한 Pod 사양 중 하나를 고려하지 않습니다.
아래 마지막 예의 Pod는 요청이 제한과 동일하기 때문에 Guaranteed QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"토폴로지 관리자는 이러한 Pod를 고려합니다. 토폴로지 관리자는 CPU 관리자 및 장치 관리자인 힌트 공급자를 참조하여 Pod의 토폴로지 힌트를 가져옵니다.
토폴로지 관리자는 이 정보를 사용하여 이 컨테이너에 대한 최상의 토폴로지를 저장합니다. 이 Pod의 경우 CPU 관리자와 장치 관리자는 리소스 할당 단계에서 이러한 저장된 정보를 사용합니다.
6장. NUMA 인식 워크로드 예약
NUMA 인식 스케줄링 및 이를 사용하여 OpenShift Container Platform 클러스터에 고성능 워크로드를 배포하는 방법을 알아봅니다.
NUMA 리소스 Operator를 사용하면 동일한 NUMA 영역에 고성능 워크로드를 예약할 수 있습니다. 사용 가능한 클러스터 노드 NUMA 리소스와 워크로드를 관리하는 보조 스케줄러에 보고하는 노드 리소스를 배포합니다.
6.1. NUMA 인식 스케줄링 정보
NUMA(Non-Uniform Memory Access)는 서로 다른 CPU가 다른 속도로 다른 메모리 영역에 액세스할 수 있도록 하는 컴퓨팅 플랫폼 아키텍처입니다. NUMA 리소스 토폴로지는 계산 노드에서 서로 상대적인 CPU, 메모리 및 PCI 장치의 위치를 나타냅니다. Co-located 리소스는 동일한 NUMA 영역에 있다고 합니다. 고성능 애플리케이션의 경우 클러스터는 단일 NUMA 영역에서 Pod 워크로드를 처리해야 합니다.
NUMA 아키텍처를 사용하면 여러 메모리 컨트롤러가 있는 CPU에서 메모리가 있는 위치에 관계없이 CPU 복잡한 CPU에서 사용 가능한 메모리를 사용할 수 있습니다. 이렇게 하면 성능이 저하될 때 유연성이 향상됩니다. NUMA 영역 외부에 있는 메모리를 사용하여 워크로드를 처리하는 CPU는 단일 NUMA 영역에서 처리된 워크로드보다 느립니다. 또한 I/O가 제한적인 워크로드의 경우 원격 NUMA 영역의 네트워크 인터페이스가 애플리케이션에 도달하는 속도가 느려집니다. 통신 워크로드와 같은 고성능 워크로드는 이러한 조건에서 사양에 따라 작동할 수 없습니다. NUMA 인식 스케줄링은 동일한 NUMA 영역에 요청된 클러스터 컴퓨팅 리소스(CPU, 메모리, 장치)를 조정하여 대기 시간에 민감하거나 고성능 워크로드를 효율적으로 처리합니다. NUMA 인식 스케줄링은 리소스 효율성을 높이기 위해 컴퓨팅 노드당 Pod 밀도를 향상시킵니다.
Node Tuning Operator의 성능 프로필을 NUMA 인식 스케줄링과 통합하면 대기 시간에 민감한 워크로드에 대한 성능을 최적화하도록 CPU 선호도를 추가로 구성할 수 있습니다.
기본 OpenShift Container Platform Pod 스케줄러 스케줄링 논리는 개별 NUMA 영역이 아닌 전체 컴퓨팅 노드의 사용 가능한 리소스를 고려합니다. kubelet 토폴로지 관리자에서 가장 제한적인 리소스 정렬이 요청되면 노드에 Pod를 허용할 때 오류 상태가 발생할 수 있습니다. 반대로, 가장 제한적인 리소스 정렬을 요청하지 않으면 적절한 리소스 정렬 없이 Pod를 노드에 허용하여 성능이 저하되거나 예측할 수 없습니다. 예를 들어 Pod 스케줄러에서 Pod의 요청된 리소스를 사용할 수 있는지 여부를 알 수 없으므로 Pod 스케줄러에서 보장된 Pod 워크로드에 대한 하위 스케줄링 결정을 내릴 때 Topology Affinity Error 를 사용한 runaway Pod 생성이 발생할 수 있습니다. 예약 불일치 결정으로 인해 Pod 시작 지연이 발생할 수 있습니다. 또한 클러스터 상태 및 리소스 할당에 따라 잘못된 Pod 예약 결정으로 인해 시작 시도가 실패했기 때문에 클러스터에 추가 로드가 발생할 수 있습니다.
NUMA 리소스 Operator는 사용자 정의 NUMA 리소스 보조 스케줄러 및 기타 리소스를 배포하여 기본 OpenShift Container Platform Pod 스케줄러의 단점에 대해 완화합니다. 다음 다이어그램에서는 NUMA 인식 Pod 예약에 대한 개괄적인 개요를 보여줍니다.
그림 6.1. NUMA 인식 스케줄링 개요
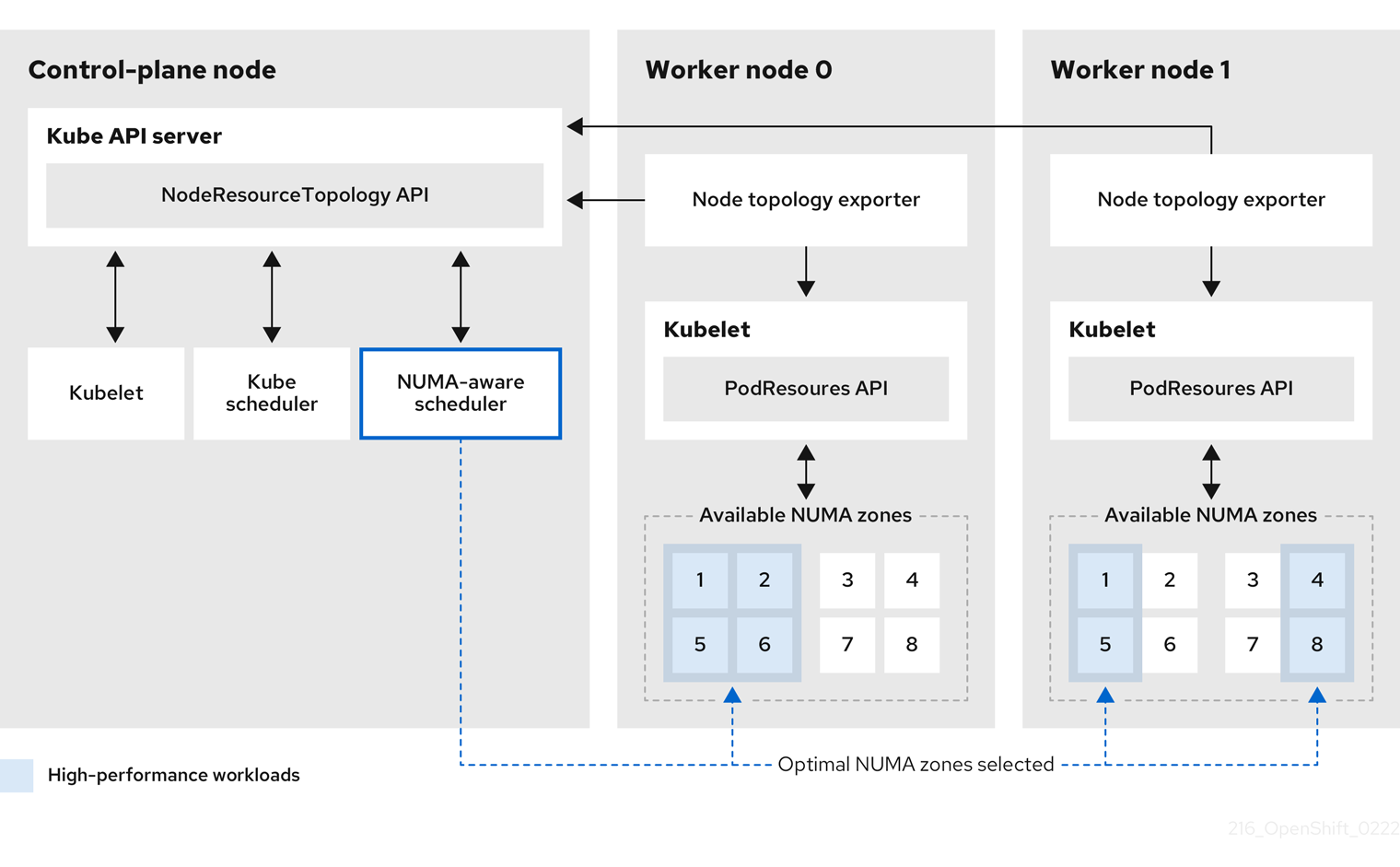
- NodeResourceTopology API
-
NodeResourceTopologyAPI는 각 컴퓨팅 노드에서 사용 가능한 NUMA 영역 리소스를 설명합니다. - NUMA 인식 스케줄러
-
NUMA 인식 보조 스케줄러는
NodeResourceTopologyAPI에서 사용 가능한 NUMA 영역에 대한 정보를 수신하고 최적으로 처리할 수 있는 노드에서 고성능 워크로드를 예약합니다. - 노드 토폴로지 내보내기
-
노드 토폴로지 내보내기는 각 컴퓨팅 노드에 대해 사용 가능한 NUMA 영역 리소스를
NodeResourceTopologyAPI에 노출합니다. 노드 토폴로지 내보내기 데몬은PodResourcesAPI를 사용하여 kubelet의 리소스 할당을 추적합니다. - PodResources API
PodResourcesAPI는 각 노드에 로컬이며 리소스 토폴로지 및 사용 가능한 리소스를 kubelet에 노출합니다.참고PodResourcesAPI의List끝점은 특정 컨테이너에 할당된 전용 CPU를 노출합니다. API는 공유 풀에 속하는 CPU를 노출하지 않습니다.GetAllocatableResources끝점은 노드에서 사용 가능한 할당 가능한 리소스를 노출합니다.
추가 리소스
- 클러스터에서 보조 Pod 스케줄러를 실행하는 방법 및 보조 Pod 스케줄러를 사용하여 Pod를 배포하는 방법에 대한 자세한 내용은 보조 스케줄러 를 사용하여 Pod 예약을 참조하십시오.
6.2. NUMA Resources Operator 설치
NUMA 리소스 Operator는 NUMA 인식 워크로드 및 배포를 예약할 수 있는 리소스를 배포합니다. OpenShift Container Platform CLI 또는 웹 콘솔을 사용하여 NUMA 리소스 Operator를 설치할 수 있습니다.
6.2.1. CLI를 사용하여 NUMA 리소스 Operator 설치
클러스터 관리자는 CLI를 사용하여 Operator를 설치할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
NUMA Resources Operator의 네임스페이스를 생성합니다.
다음 YAML을
nro-namespace.yaml파일에 저장합니다.apiVersion: v1 kind: Namespace metadata: name: openshift-numaresources
다음 명령을 실행하여
네임스페이스CR을 생성합니다.$ oc create -f nro-namespace.yaml
NUMA Resources Operator에 대한 Operator 그룹을 생성합니다.
다음 YAML을
nro-operatorgroup.yaml파일에 저장합니다.apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: numaresources-operator namespace: openshift-numaresources spec: targetNamespaces: - openshift-numaresources
다음 명령을 실행하여
OperatorGroupCR을 생성합니다.$ oc create -f nro-operatorgroup.yaml
NUMA Resources Operator에 대한 서브스크립션을 생성합니다.
다음 YAML을
nro-sub.yaml파일에 저장합니다.apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: numaresources-operator namespace: openshift-numaresources spec: channel: "4.15" name: numaresources-operator source: redhat-operators sourceNamespace: openshift-marketplace
다음 명령을 실행하여
서브스크립션CR을 생성합니다.$ oc create -f nro-sub.yaml
검증
openshift-numaresources네임스페이스에서 CSV 리소스를 검사하여 설치에 성공했는지 확인합니다. 다음 명령을 실행합니다.$ oc get csv -n openshift-numaresources
출력 예
NAME DISPLAY VERSION REPLACES PHASE numaresources-operator.v4.15.2 numaresources-operator 4.15.2 Succeeded
6.2.2. 웹 콘솔을 사용하여 NUMA Resources Operator 설치
클러스터 관리자는 웹 콘솔을 사용하여 NUMA 리소스 Operator를 설치할 수 있습니다.
프로세스
NUMA Resources Operator의 네임스페이스를 생성합니다.
- OpenShift Container Platform 웹 콘솔에서 관리 → 네임스페이스를 클릭합니다.
-
네임스페이스 생성을 클릭하고 이름 필드에
openshift-numaresources를 입력한 다음 생성 을 클릭합니다.
NUMA Resources Operator를 설치합니다.
- OpenShift Container Platform 웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
- 사용 가능한 Operator 목록에서 NUMA Resources Operator 를 선택한 다음 설치를 클릭합니다.
-
설치된 네임스페이스 필드에서
openshift-numaresources네임스페이스를 선택한 다음 설치를 클릭합니다.
선택 사항: NUMA Resources Operator가 성공적으로 설치되었는지 확인합니다.
- Operator → 설치된 Operator 페이지로 전환합니다.
NUMA Resources Operator 가
openshift-numaresources네임스페이스에 InstallSucceeded 상태로 나열되어 있는지 확인합니다.참고설치 중에 Operator는 실패 상태를 표시할 수 있습니다. 나중에 InstallSucceeded 메시지와 함께 설치에 성공하면 이 실패 메시지를 무시할 수 있습니다.
Operator가 설치된 것으로 나타나지 않으면 다음과 같이 추가 문제 해결을 수행합니다.
- Operator → 설치된 Operator 페이지로 이동하고 Operator 서브스크립션 및 설치 계획 탭의 상태에 장애나 오류가 있는지 검사합니다.
-
워크로드 → Pod 페이지로 이동하여
기본프로젝트에서 Pod 로그를 확인합니다.
6.3. NUMA 인식 워크로드 예약
대기 시간에 민감한 워크로드를 실행하는 클러스터는 일반적으로 워크로드 대기 시간을 최소화하고 성능을 최적화하는 데 도움이 되는 성능 프로필을 제공합니다. NUMA 인식 스케줄러는 노드에 적용된 성능 프로필 설정과 관련하여 사용 가능한 노드 NUMA 리소스를 기반으로 워크로드를 배포합니다. NUMA 인식 배포와 워크로드의 성능 프로파일이 조합되면 성능을 극대화하는 방식으로 워크로드가 예약됩니다.
6.3.1. NUMAResourcesOperator 사용자 정의 리소스 생성
NUMA Resources Operator를 설치한 경우 데몬 세트 및 API를 포함하여 NUMA 리소스 Operator 가 NUMA 인식 스케줄러를 지원하는 데 필요한 모든 클러스터 인프라를 설치하도록 지시하는 NUMAResourcesOperator CR(사용자 정의 리소스)을 생성합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - NUMA Resources Operator를 설치합니다.
프로세스
NUMAResourcesOperator사용자 지정 리소스를 만듭니다.다음 YAML을
nrop.yaml파일에 저장합니다.apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: ""다음 명령을 실행하여
NUMAResourcesOperatorCR을 만듭니다.$ oc create -f nrop.yaml
검증
다음 명령을 실행하여 NUMA Resources Operator가 성공적으로 배포되었는지 확인합니다.
$ oc get numaresourcesoperators.nodetopology.openshift.io
출력 예
NAME AGE numaresourcesoperator 10m
6.3.2. NUMA 인식 보조 Pod 스케줄러 배포
NUMA Resources Operator를 설치한 후 다음을 수행하여 NUMA 인식 보조 Pod 스케줄러를 배포합니다.
- 성능 프로필을 구성합니다.
- NUMA 인식 보조 스케줄러를 배포합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - 필요한 머신 구성 풀을 생성합니다.
- NUMA Resources Operator를 설치합니다.
프로세스
PerformanceProfileCR(사용자 정의 리소스)을 생성합니다.nro-perfprof.yaml파일에 다음 YAML을 저장합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: perfprof-nrop spec: cpu: 1 isolated: "4-51,56-103" reserved: "0,1,2,3,52,53,54,55" nodeSelector: node-role.kubernetes.io/worker: "" numa: topologyPolicy: single-numa-node- 1
cpu.isolated및cpu.reserved사양은 분리된 CPU 및 예약된 CPU의 범위를 정의합니다. CPU 구성에 유효한 값을 입력합니다. 성능 프로필 구성에 대한 자세한 내용은 추가 리소스 섹션을 참조하십시오.
다음 명령을 실행하여
PerformanceProfileCR을 생성합니다.$ oc create -f nro-perfprof.yaml
출력 예
performanceprofile.performance.openshift.io/perfprof-nrop created
NUMA 인식 사용자 정의 Pod 스케줄러를 배포하는
NUMAResourcesScheduler사용자 정의 리소스를 생성합니다.nro-scheduler.yaml파일에 다음 YAML을 저장합니다.apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-rhel9:v4.15" cacheResyncPeriod: "5s" 1- 1
- 스케줄러 캐시의 동기화를 위해 간격 값을 초 단위로 입력합니다. 값
5s는 대부분의 구현에 일반적인 값입니다.
참고-
cacheResyncPeriod사양을 활성화하여 노드에서 보류 중인 리소스를 모니터링하고 이 정보를 정의된 간격으로 스케줄러 캐시에서 동기화하여 NUMA 리소스 가용성을 보다 정확하게 보고할 수 있습니다. 또한 최적의 스케줄링 결정으로 인해토폴로지 선호도 오류오류를 최소화하는 데 도움이 됩니다. 간격을 줄이는 경우 네트워크를 더 많이 로드할 수 있습니다.cacheResyncPeriod사양은 기본적으로 비활성화되어 있습니다. -
NUMAResourcesOperatorCR의podsFingerprinting사양에 대해Enabled값을 설정하는 것은cacheResyncPeriod사양을 구현하기 위한 요구 사항입니다.
다음 명령을 실행하여
NUMAResourcesSchedulerCR을 만듭니다.$ oc create -f nro-scheduler.yaml
검증
다음 명령을 실행하여 성능 프로필이 적용되었는지 확인합니다.
$ oc describe performanceprofile <performance-profile-name>
다음 명령을 실행하여 필요한 리소스가 성공적으로 배포되었는지 확인합니다.
$ oc get all -n openshift-numaresources
출력 예
NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7575848485-bns4s 1/1 Running 0 13m pod/numaresourcesoperator-worker-dvj4n 2/2 Running 0 16m pod/numaresourcesoperator-worker-lcg4t 2/2 Running 0 16m pod/secondary-scheduler-56994cf6cf-7qf4q 1/1 Running 0 16m NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/numaresourcesoperator-worker 2 2 2 2 2 node-role.kubernetes.io/worker= 16m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/numaresources-controller-manager 1/1 1 1 13m deployment.apps/secondary-scheduler 1/1 1 1 16m NAME DESIRED CURRENT READY AGE replicaset.apps/numaresources-controller-manager-7575848485 1 1 1 13m replicaset.apps/secondary-scheduler-56994cf6cf 1 1 1 16m
추가 리소스
6.3.3. NUMA 인식 스케줄러를 사용하여 워크로드 예약
워크로드를 처리하는 데 필요한 최소 리소스를 지정하는 Deployment CR을 사용하여 NUMA 인식 스케줄러로 워크로드를 예약할 수 있습니다.
다음 예제 배포에서는 샘플 워크로드에 대해 NUMA 인식 스케줄링을 사용합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - NUMA Resources Operator를 설치하고 NUMA 인식 보조 스케줄러를 배포합니다.
프로세스
다음 명령을 실행하여 클러스터에 배포된 NUMA 인식 스케줄러의 이름을 가져옵니다.
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'
출력 예
topo-aware-scheduler
스케줄러 이름이
topo-aware-scheduler인DeploymentCR을 생성합니다. 예를 들면 다음과 같습니다.다음 YAML을
nro-deployment.yaml파일에 저장합니다.apiVersion: apps/v1 kind: Deployment metadata: name: numa-deployment-1 namespace: openshift-numaresources spec: replicas: 1 selector: matchLabels: app: test template: metadata: labels: app: test spec: schedulerName: topo-aware-scheduler 1 containers: - name: ctnr image: quay.io/openshifttest/hello-openshift:openshift imagePullPolicy: IfNotPresent resources: limits: memory: "100Mi" cpu: "10" requests: memory: "100Mi" cpu: "10" - name: ctnr2 image: registry.access.redhat.com/rhel:latest imagePullPolicy: IfNotPresent command: ["/bin/sh", "-c"] args: [ "while true; do sleep 1h; done;" ] resources: limits: memory: "100Mi" cpu: "8" requests: memory: "100Mi" cpu: "8"- 1
schedulerName은 클러스터에 배포된 NUMA 인식 스케줄러의 이름(예:topo-aware-scheduler)과 일치해야 합니다.
다음 명령을 실행하여
DeploymentCR을 생성합니다.$ oc create -f nro-deployment.yaml
검증
배포에 성공했는지 확인합니다.
$ oc get pods -n openshift-numaresources
출력 예
NAME READY STATUS RESTARTS AGE numa-deployment-1-56954b7b46-pfgw8 2/2 Running 0 129m numaresources-controller-manager-7575848485-bns4s 1/1 Running 0 15h numaresourcesoperator-worker-dvj4n 2/2 Running 0 18h numaresourcesoperator-worker-lcg4t 2/2 Running 0 16h secondary-scheduler-56994cf6cf-7qf4q 1/1 Running 0 18h
topo-aware-scheduler에서 다음 명령을 실행하여 배포된 Pod를 예약하는지 확인합니다.$ oc describe pod numa-deployment-1-56954b7b46-pfgw8 -n openshift-numaresources
출력 예
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 130m topo-aware-scheduler Successfully assigned openshift-numaresources/numa-deployment-1-56954b7b46-pfgw8 to compute-0.example.com
참고예약에 사용할 수 있는 것보다 많은 리소스를 요청하는 배포는
MinimumReplicasUnavailable오류와 함께 실패합니다. 필요한 리소스를 사용할 수 있게 되면 배포가 성공합니다. Pod는 필요한 리소스를 사용할 수 있을 때까지Pending상태로 유지됩니다.예상되는 할당된 리소스가 노드에 대해 나열되어 있는지 확인합니다.
다음 명령을 실행하여 배포 Pod를 실행 중인 노드를 확인하고 <namespace>를
DeploymentCR에 지정한 네임스페이스로 교체합니다.$ oc get pods -n <namespace> -o wide
출력 예
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES numa-deployment-1-65684f8fcc-bw4bw 0/2 Running 0 82m 10.128.2.50 worker-0 <none> <none>
다음 명령을 실행하여 <node_name>을 배포 Pod를 실행 중인 해당 노드의 이름으로 바꿉니다.
$ oc describe noderesourcetopologies.topology.node.k8s.io <node_name>
출력 예
... Zones: Costs: Name: node-0 Value: 10 Name: node-1 Value: 21 Name: node-0 Resources: Allocatable: 39 Available: 21 1 Capacity: 40 Name: cpu Allocatable: 6442450944 Available: 6442450944 Capacity: 6442450944 Name: hugepages-1Gi Allocatable: 134217728 Available: 134217728 Capacity: 134217728 Name: hugepages-2Mi Allocatable: 262415904768 Available: 262206189568 Capacity: 270146007040 Name: memory Type: Node- 1
- 보장된 pod에 할당된 리소스 때문에
사용 가능한용량이 줄어듭니다.
보장된 Pod에서 사용하는 리소스는
noderesourcetopologies.topology.node.k8s.io아래에 나열된 사용 가능한 노드 리소스에서 차감됩니다.
Best-effort또는BurstableQoS(qosClass)가 있는 Pod의 리소스 할당은noderesourcetopologies.topology.node.k8s.io의 NUMA 노드 리소스에 반영되지 않습니다. Pod의 사용한 리소스가 노드 리소스 계산에 반영되지 않은 경우 Pod에Guaranteed가 있고 CPU 요청이 10진수 값이 아닌 정수 값이 있는지 확인합니다.다음 명령을 실행하여 Pod에보장된qosClass가 있는지 확인할 수 있습니다.$ oc get pod <pod_name> -n <pod_namespace> -o jsonpath="{ .status.qosClass }"출력 예
Guaranteed
6.4. 수동 성능 설정으로 NUMA 인식 워크로드 예약
대기 시간에 민감한 워크로드를 실행하는 클러스터는 일반적으로 워크로드 대기 시간을 최소화하고 성능을 최적화하는 데 도움이 되는 성능 프로필을 제공합니다. 그러나 성능 프로파일이 없는 초기 클러스터에서 NUMA 인식 워크로드를 예약할 수 있습니다. 다음 워크플로는 KubeletConfig 리소스를 사용하여 성능을 위해 수동으로 구성할 수 있는 초기 클러스터를 제공합니다. 이는 NUMA 인식 워크로드를 예약하는 일반적인 환경이 아닙니다.
6.4.1. 수동 성능 설정을 사용하여 NUMAResourcesOperator 사용자 지정 리소스 생성
NUMA Resources Operator를 설치한 경우 데몬 세트 및 API를 포함하여 NUMA 리소스 Operator 가 NUMA 인식 스케줄러를 지원하는 데 필요한 모든 클러스터 인프라를 설치하도록 지시하는 NUMAResourcesOperator CR(사용자 정의 리소스)을 생성합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - NUMA Resources Operator를 설치합니다.
프로세스
선택 사항: 작업자 노드에 사용자 정의 kubelet 구성을 활성화하는
MachineConfigPool사용자 정의 리소스를 생성합니다.참고기본적으로 OpenShift Container Platform은 클러스터의 작업자 노드에 대한
MachineConfigPool리소스를 생성합니다. 필요한 경우 사용자 지정MachineConfigPool리소스를 생성할 수 있습니다.다음 YAML을
nro-machineconfig.yaml파일에 저장합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: labels: cnf-worker-tuning: enabled machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: "" name: worker spec: machineConfigSelector: matchLabels: machineconfiguration.openshift.io/role: worker nodeSelector: matchLabels: node-role.kubernetes.io/worker: ""다음 명령을 실행하여
MachineConfigPoolCR을 생성합니다.$ oc create -f nro-machineconfig.yaml
NUMAResourcesOperator사용자 지정 리소스를 만듭니다.다음 YAML을
nrop.yaml파일에 저장합니다.apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: "" 1- 1
- 관련
MachineConfigPoolCR의 작업자 노드에 적용되는 레이블과 일치해야 합니다.
다음 명령을 실행하여
NUMAResourcesOperatorCR을 만듭니다.$ oc create -f nrop.yaml
검증
다음 명령을 실행하여 NUMA Resources Operator가 성공적으로 배포되었는지 확인합니다.
$ oc get numaresourcesoperators.nodetopology.openshift.io
출력 예
NAME AGE numaresourcesoperator 10m
6.4.2. 수동 성능 설정을 사용하여 NUMA 인식 보조 Pod 스케줄러 배포
NUMA Resources Operator를 설치한 후 다음을 수행하여 NUMA 인식 보조 Pod 스케줄러를 배포합니다.
- 필요한 머신 프로필에 대한 Pod 승인 정책을 구성합니다.
- 필요한 머신 구성 풀을 생성합니다.
- NUMA 인식 보조 스케줄러 배포
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - NUMA Resources Operator를 설치합니다.
프로세스
머신 프로필에 대한 Pod 허용 정책을 구성하는
KubeletConfig사용자 정의 리소스를 생성합니다.다음 YAML을
nro-kubeletconfig.yaml파일에 저장합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cnf-worker-tuning spec: machineConfigPoolSelector: matchLabels: cnf-worker-tuning: enabled kubeletConfig: cpuManagerPolicy: "static" 1 cpuManagerReconcilePeriod: "5s" reservedSystemCPUs: "0,1" memoryManagerPolicy: "Static" 2 evictionHard: memory.available: "100Mi" reservedMemory: - numaNode: 0 limits: memory: "1124Mi" systemReserved: memory: "512Mi" topologyManagerPolicy: "single-numa-node" 3 topologyManagerScope: "pod"다음 명령을 실행하여
KubeletConfigCR(사용자 정의 리소스)을 생성합니다.$ oc create -f nro-kubeletconfig.yaml
NUMA 인식 사용자 정의 Pod 스케줄러를 배포하는
NUMAResourcesScheduler사용자 정의 리소스를 생성합니다.nro-scheduler.yaml파일에 다음 YAML을 저장합니다.apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-container-rhel8:v4.15" cacheResyncPeriod: "5s" 1- 1
- 스케줄러 캐시의 동기화를 위해 간격 값을 초 단위로 입력합니다. 값
5s는 대부분의 구현에 일반적인 값입니다.
참고-
cacheResyncPeriod사양을 활성화하여 노드에서 보류 중인 리소스를 모니터링하고 이 정보를 정의된 간격으로 스케줄러 캐시에서 동기화하여 NUMA 리소스 가용성을 보다 정확하게 보고할 수 있습니다. 또한 최적의 스케줄링 결정으로 인해토폴로지 선호도 오류오류를 최소화하는 데 도움이 됩니다. 간격을 줄이는 경우 네트워크를 더 많이 로드할 수 있습니다.cacheResyncPeriod사양은 기본적으로 비활성화되어 있습니다. -
NUMAResourcesOperatorCR의podsFingerprinting사양에 대해Enabled값을 설정하는 것은cacheResyncPeriod사양을 구현하기 위한 요구 사항입니다.
다음 명령을 실행하여
NUMAResourcesSchedulerCR을 만듭니다.$ oc create -f nro-scheduler.yaml
검증
다음 명령을 실행하여 필요한 리소스가 성공적으로 배포되었는지 확인합니다.
$ oc get all -n openshift-numaresources
출력 예
NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7575848485-bns4s 1/1 Running 0 13m pod/numaresourcesoperator-worker-dvj4n 2/2 Running 0 16m pod/numaresourcesoperator-worker-lcg4t 2/2 Running 0 16m pod/secondary-scheduler-56994cf6cf-7qf4q 1/1 Running 0 16m NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/numaresourcesoperator-worker 2 2 2 2 2 node-role.kubernetes.io/worker= 16m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/numaresources-controller-manager 1/1 1 1 13m deployment.apps/secondary-scheduler 1/1 1 1 16m NAME DESIRED CURRENT READY AGE replicaset.apps/numaresources-controller-manager-7575848485 1 1 1 13m replicaset.apps/secondary-scheduler-56994cf6cf 1 1 1 16m
6.4.3. 수동 성능 설정을 사용하여 NUMA 인식 스케줄러를 사용하여 워크로드 예약
워크로드를 처리하는 데 필요한 최소 리소스를 지정하는 Deployment CR을 사용하여 NUMA 인식 스케줄러로 워크로드를 예약할 수 있습니다.
다음 예제 배포에서는 샘플 워크로드에 대해 NUMA 인식 스케줄링을 사용합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - NUMA Resources Operator를 설치하고 NUMA 인식 보조 스케줄러를 배포합니다.
프로세스
다음 명령을 실행하여 클러스터에 배포된 NUMA 인식 스케줄러의 이름을 가져옵니다.
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'
출력 예
topo-aware-scheduler
스케줄러 이름이
topo-aware-scheduler인DeploymentCR을 생성합니다. 예를 들면 다음과 같습니다.다음 YAML을
nro-deployment.yaml파일에 저장합니다.apiVersion: apps/v1 kind: Deployment metadata: name: numa-deployment-1 namespace: openshift-numaresources spec: replicas: 1 selector: matchLabels: app: test template: metadata: labels: app: test spec: schedulerName: topo-aware-scheduler 1 containers: - name: ctnr image: quay.io/openshifttest/hello-openshift:openshift imagePullPolicy: IfNotPresent resources: limits: memory: "100Mi" cpu: "10" requests: memory: "100Mi" cpu: "10" - name: ctnr2 image: registry.access.redhat.com/rhel:latest imagePullPolicy: IfNotPresent command: ["/bin/sh", "-c"] args: [ "while true; do sleep 1h; done;" ] resources: limits: memory: "100Mi" cpu: "8" requests: memory: "100Mi" cpu: "8"- 1
schedulerName은 클러스터에 배포된 NUMA 인식 스케줄러의 이름(예:topo-aware-scheduler)과 일치해야 합니다.
다음 명령을 실행하여
DeploymentCR을 생성합니다.$ oc create -f nro-deployment.yaml
검증
배포에 성공했는지 확인합니다.
$ oc get pods -n openshift-numaresources
출력 예
NAME READY STATUS RESTARTS AGE numa-deployment-1-56954b7b46-pfgw8 2/2 Running 0 129m numaresources-controller-manager-7575848485-bns4s 1/1 Running 0 15h numaresourcesoperator-worker-dvj4n 2/2 Running 0 18h numaresourcesoperator-worker-lcg4t 2/2 Running 0 16h secondary-scheduler-56994cf6cf-7qf4q 1/1 Running 0 18h
topo-aware-scheduler에서 다음 명령을 실행하여 배포된 Pod를 예약하는지 확인합니다.$ oc describe pod numa-deployment-1-56954b7b46-pfgw8 -n openshift-numaresources
출력 예
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 130m topo-aware-scheduler Successfully assigned openshift-numaresources/numa-deployment-1-56954b7b46-pfgw8 to compute-0.example.com
참고예약에 사용할 수 있는 것보다 많은 리소스를 요청하는 배포는
MinimumReplicasUnavailable오류와 함께 실패합니다. 필요한 리소스를 사용할 수 있게 되면 배포가 성공합니다. Pod는 필요한 리소스를 사용할 수 있을 때까지Pending상태로 유지됩니다.예상되는 할당된 리소스가 노드에 대해 나열되어 있는지 확인합니다.
다음 명령을 실행하여 배포 Pod를 실행 중인 노드를 확인하고 <namespace>를
DeploymentCR에 지정한 네임스페이스로 교체합니다.$ oc get pods -n <namespace> -o wide
출력 예
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES numa-deployment-1-65684f8fcc-bw4bw 0/2 Running 0 82m 10.128.2.50 worker-0 <none> <none>
다음 명령을 실행하여 <node_name>을 배포 Pod를 실행 중인 해당 노드의 이름으로 교체합니다.
$ oc describe noderesourcetopologies.topology.node.k8s.io <node_name>
출력 예
... Zones: Costs: Name: node-0 Value: 10 Name: node-1 Value: 21 Name: node-0 Resources: Allocatable: 39 Available: 21 1 Capacity: 40 Name: cpu Allocatable: 6442450944 Available: 6442450944 Capacity: 6442450944 Name: hugepages-1Gi Allocatable: 134217728 Available: 134217728 Capacity: 134217728 Name: hugepages-2Mi Allocatable: 262415904768 Available: 262206189568 Capacity: 270146007040 Name: memory Type: Node- 1
- 보장된 pod에 할당된 리소스 때문에
사용 가능한용량이 줄어듭니다.
보장된 Pod에서 사용하는 리소스는
noderesourcetopologies.topology.node.k8s.io아래에 나열된 사용 가능한 노드 리소스에서 차감됩니다.
Best-effort또는BurstableQoS(qosClass)가 있는 Pod의 리소스 할당은noderesourcetopologies.topology.node.k8s.io의 NUMA 노드 리소스에 반영되지 않습니다. Pod의 사용한 리소스가 노드 리소스 계산에 반영되지 않은 경우 Pod에Guaranteed가 있고 CPU 요청이 10진수 값이 아닌 정수 값이 있는지 확인합니다.다음 명령을 실행하여 Pod에보장된qosClass가 있는지 확인할 수 있습니다.$ oc get pod <pod_name> -n <pod_namespace> -o jsonpath="{ .status.qosClass }"출력 예
Guaranteed
6.5. 선택 사항: NUMA 리소스 업데이트를 위한 폴링 작업 구성
nodeGroup 의 NUMA Resources Operator에서 제어하는 데몬은 리소스를 폴링하여 사용 가능한 NUMA 리소스에 대한 업데이트를 검색합니다. NUMAResourcesOperator CR(사용자 정의 리소스)에서 spec.nodeGroups 사양을 구성하여 이러한 데몬에 대한 폴링 작업을 미세 조정할 수 있습니다. 이를 통해 폴링 작업에 대한 고급 제어가 제공됩니다. 스케줄링 동작을 개선하고 최적의 스케줄링 결정을 해결하기 위해 이러한 사양을 구성합니다.
구성 옵션은 다음과 같습니다.
-
infoRefreshMode: kubelet을 폴링하기 위한 트리거 조건을 결정합니다. NUMA Resources Operator는 결과 정보를 API 서버에 보고합니다. -
infoRefreshPeriod: 폴링 업데이트 사이의 기간을 결정합니다. podsFingerprinting: 노드에서 실행되는 현재 Pod 세트에 대한 지정 시간 정보가 폴링 업데이트에서 노출되는지 여부를 결정합니다.참고podsFingerprinting은 기본적으로 활성화되어 있습니다.podsFingerprinting은NUMAResourcesSchedulerCR의cacheResyncPeriod사양에 대한 요구 사항입니다.cacheResyncPeriod사양은 노드에서 보류 중인 리소스를 모니터링하여 보다 정확한 리소스 가용성을 보고하는 데 도움이 됩니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - NUMA Resources Operator를 설치합니다.
프로세스
NUMAResourcesOperatorCR에서spec.nodeGroups사양을 구성합니다.apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - config: infoRefreshMode: Periodic 1 infoRefreshPeriod: 10s 2 podsFingerprinting: Enabled 3 name: worker- 1
- 유효한 값은
Periodic,Events,periodicAndEvents입니다.Periodic을 사용하여infoRefreshPeriod에 정의된 간격으로 kubelet을 폴링합니다.이벤트를사용하여 모든 Pod 라이프사이클 이벤트에서 kubelet을 폴링합니다.PeriodicAndEvents를 사용하여 두 가지 방법을 모두 활성화합니다. - 2
Periodic또는PeriodicAndEvents새로 고침 모드의 폴링 간격을 정의합니다. 새로 고침 모드가Events인 경우 필드가 무시됩니다.- 3
- 유효한 값은
사용또는Disabled입니다.NUMAResourcesScheduler의cacheResyncPeriod사양에 대한 요구 사항입니다.
검증
NUMA Resources Operator를 배포한 후 다음 명령을 실행하여 노드 그룹 구성이 적용되었는지 확인합니다.
$ oc get numaresop numaresourcesoperator -o json | jq '.status'
출력 예
... "config": { "infoRefreshMode": "Periodic", "infoRefreshPeriod": "10s", "podsFingerprinting": "Enabled" }, "name": "worker" ...
6.6. NUMA 인식 스케줄링 문제 해결
NUMA 인식 Pod 예약의 일반적인 문제를 해결하려면 다음 단계를 수행합니다.
사전 요구 사항
-
OpenShift Container Platform CLI (
oc)를 설치합니다. - cluster-admin 권한이 있는 사용자로 로그인합니다.
- NUMA Resources Operator를 설치하고 NUMA 인식 보조 스케줄러를 배포합니다.
프로세스
다음 명령을 실행하여
noderesourcetopologiesCRD가 클러스터에 배포되었는지 확인합니다.$ oc get crd | grep noderesourcetopologies
출력 예
NAME CREATED AT noderesourcetopologies.topology.node.k8s.io 2022-01-18T08:28:06Z
다음 명령을 실행하여 NUMA 인식 스케줄러 이름이 NUMA 인식 워크로드에 지정된 이름과 일치하는지 확인합니다.
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'
출력 예
topo-aware-scheduler
NUMA 인식 scheduable 노드에
noderesourcetopologiesCR이 적용되는지 확인합니다. 다음 명령을 실행합니다.$ oc get noderesourcetopologies.topology.node.k8s.io
출력 예
NAME AGE compute-0.example.com 17h compute-1.example.com 17h
참고노드 수는 머신 구성 풀(
mcp) 작업자 정의로 구성된 작업자 노드 수와 같아야 합니다.다음 명령을 실행하여 예약 가능한 모든 노드에 대한 NUMA 영역 단위가 있는지 확인합니다.
$ oc get noderesourcetopologies.topology.node.k8s.io -o yaml
출력 예
apiVersion: v1 items: - apiVersion: topology.node.k8s.io/v1 kind: NodeResourceTopology metadata: annotations: k8stopoawareschedwg/rte-update: periodic creationTimestamp: "2022-06-16T08:55:38Z" generation: 63760 name: worker-0 resourceVersion: "8450223" uid: 8b77be46-08c0-4074-927b-d49361471590 topologyPolicies: - SingleNUMANodeContainerLevel zones: - costs: - name: node-0 value: 10 - name: node-1 value: 21 name: node-0 resources: - allocatable: "38" available: "38" capacity: "40" name: cpu - allocatable: "134217728" available: "134217728" capacity: "134217728" name: hugepages-2Mi - allocatable: "262352048128" available: "262352048128" capacity: "270107316224" name: memory - allocatable: "6442450944" available: "6442450944" capacity: "6442450944" name: hugepages-1Gi type: Node - costs: - name: node-0 value: 21 - name: node-1 value: 10 name: node-1 resources: - allocatable: "268435456" available: "268435456" capacity: "268435456" name: hugepages-2Mi - allocatable: "269231067136" available: "269231067136" capacity: "270573244416" name: memory - allocatable: "40" available: "40" capacity: "40" name: cpu - allocatable: "1073741824" available: "1073741824" capacity: "1073741824" name: hugepages-1Gi type: Node - apiVersion: topology.node.k8s.io/v1 kind: NodeResourceTopology metadata: annotations: k8stopoawareschedwg/rte-update: periodic creationTimestamp: "2022-06-16T08:55:37Z" generation: 62061 name: worker-1 resourceVersion: "8450129" uid: e8659390-6f8d-4e67-9a51-1ea34bba1cc3 topologyPolicies: - SingleNUMANodeContainerLevel zones: 1 - costs: - name: node-0 value: 10 - name: node-1 value: 21 name: node-0 resources: 2 - allocatable: "38" available: "38" capacity: "40" name: cpu - allocatable: "6442450944" available: "6442450944" capacity: "6442450944" name: hugepages-1Gi - allocatable: "134217728" available: "134217728" capacity: "134217728" name: hugepages-2Mi - allocatable: "262391033856" available: "262391033856" capacity: "270146301952" name: memory type: Node - costs: - name: node-0 value: 21 - name: node-1 value: 10 name: node-1 resources: - allocatable: "40" available: "40" capacity: "40" name: cpu - allocatable: "1073741824" available: "1073741824" capacity: "1073741824" name: hugepages-1Gi - allocatable: "268435456" available: "268435456" capacity: "268435456" name: hugepages-2Mi - allocatable: "269192085504" available: "269192085504" capacity: "270534262784" name: memory type: Node kind: List metadata: resourceVersion: "" selfLink: ""
6.6.1. NUMA 인식 스케줄러 로그 확인
로그를 검토하여 NUMA 인식 스케줄러의 문제를 해결합니다. 필요한 경우 NUMAResourcesScheduler 리소스의 spec.logLevel 필드를 수정하여 스케줄러 로그 수준을 늘릴 수 있습니다. 허용 가능한 값은 Normal,Debug 및 Trace 이며 Trace 는 가장 자세한 옵션입니다.
보조 스케줄러의 로그 수준을 변경하려면 실행 중인 스케줄러 리소스를 삭제하고 변경된 로그 수준으로 다시 배포합니다. 이 다운타임 동안 새 워크로드를 예약할 수 없습니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
현재 실행 중인
NUMAResourcesScheduler리소스를 삭제합니다.다음 명령을 실행하여 활성
NUMAResourcesScheduler를 가져옵니다.$ oc get NUMAResourcesScheduler
출력 예
NAME AGE numaresourcesscheduler 90m
다음 명령을 실행하여 보조 스케줄러 리소스를 삭제합니다.
$ oc delete NUMAResourcesScheduler numaresourcesscheduler
출력 예
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
nro-scheduler-debug.yaml파일에 다음 YAML을 저장합니다. 이 예에서는 로그 수준을Debug로 변경합니다.apiVersion: nodetopology.openshift.io/v1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-container-rhel8:v4.15" logLevel: Debug
다음 명령을 실행하여 업데이트된
DebugloggingNUMAResourcesScheduler리소스를 만듭니다.$ oc create -f nro-scheduler-debug.yaml
출력 예
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
검증 단계
NUMA 인식 스케줄러가 성공적으로 배포되었는지 확인합니다.
다음 명령을 실행하여 CRD가 정상적으로 생성되었는지 확인합니다.
$ oc get crd | grep numaresourcesschedulers
출력 예
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z
다음 명령을 실행하여 새 사용자 정의 스케줄러를 사용할 수 있는지 확인합니다.
$ oc get numaresourcesschedulers.nodetopology.openshift.io
출력 예
NAME AGE numaresourcesscheduler 3h26m
스케줄러의 로그에 증가된 로그 수준이 표시되는지 확인합니다.
다음 명령을 실행하여
openshift-numaresources네임스페이스에서 실행 중인 Pod 목록을 가져옵니다.$ oc get pods -n openshift-numaresources
출력 예
NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21m
다음 명령을 실행하여 보조 스케줄러 Pod의 로그를 가져옵니다.
$ oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresources
출력 예
... I0223 11:04:55.614788 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.Namespace total 11 items received I0223 11:04:56.609114 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.ReplicationController total 10 items received I0223 11:05:22.626818 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.StorageClass total 7 items received I0223 11:05:31.610356 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.PodDisruptionBudget total 7 items received I0223 11:05:31.713032 1 eventhandlers.go:186] "Add event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq" I0223 11:05:53.461016 1 eventhandlers.go:244] "Delete event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq"
6.6.2. 리소스 토폴로지 내보내기 문제 해결
해당 resource-topology-exporter 로그를 검사하여 예기치 않은 결과가 발생하는 noderesourcetopologies 오브젝트의 문제를 해결합니다.
해당 노드에서 클러스터의 NUMA 리소스 토폴로지 내보내기 인스턴스의 이름을 지정하는 것이 좋습니다. 예를 들어, 이름이 worker인 작업자 노드에는 라는 해당 worker noderesourcetopologies 오브젝트가 있어야 합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
NUMA Resources Operator에서 관리하는 데몬 세트를 가져옵니다. 각 daemonset에는
NUMAResourcesOperatorCR에 해당nodeGroup이 있습니다. 다음 명령을 실행합니다.$ oc get numaresourcesoperators.nodetopology.openshift.io numaresourcesoperator -o jsonpath="{.status.daemonsets[0]}"출력 예
{"name":"numaresourcesoperator-worker","namespace":"openshift-numaresources"}이전 단계의
name에 대한 값을 사용하여 관심 있는 데몬 세트의 레이블을 가져옵니다.$ oc get ds -n openshift-numaresources numaresourcesoperator-worker -o jsonpath="{.spec.selector.matchLabels}"출력 예
{"name":"resource-topology"}다음 명령을 실행하여
resource-topology레이블을 사용하여 Pod를 가져옵니다.$ oc get pods -n openshift-numaresources -l name=resource-topology -o wide
출력 예
NAME READY STATUS RESTARTS AGE IP NODE numaresourcesoperator-worker-5wm2k 2/2 Running 0 2d1h 10.135.0.64 compute-0.example.com numaresourcesoperator-worker-pb75c 2/2 Running 0 2d1h 10.132.2.33 compute-1.example.com
문제 해결 중인 노드에 해당하는 작업자 Pod에서 실행 중인
resource-topology-exporter컨테이너의 로그를 검사합니다. 다음 명령을 실행합니다.$ oc logs -n openshift-numaresources -c resource-topology-exporter numaresourcesoperator-worker-pb75c
출력 예
I0221 13:38:18.334140 1 main.go:206] using sysinfo: reservedCpus: 0,1 reservedMemory: "0": 1178599424 I0221 13:38:18.334370 1 main.go:67] === System information === I0221 13:38:18.334381 1 sysinfo.go:231] cpus: reserved "0-1" I0221 13:38:18.334493 1 sysinfo.go:237] cpus: online "0-103" I0221 13:38:18.546750 1 main.go:72] cpus: allocatable "2-103" hugepages-1Gi: numa cell 0 -> 6 numa cell 1 -> 1 hugepages-2Mi: numa cell 0 -> 64 numa cell 1 -> 128 memory: numa cell 0 -> 45758Mi numa cell 1 -> 48372Mi
6.6.3. 누락된 리소스 토폴로지 내보내기 구성 맵 수정
클러스터 설정이 잘못 구성된 클러스터에 NUMA Resources Operator를 설치하는 경우 Operator가 active로 표시되지만 RTE(Resource topology exporter) 데몬 세트 Pod의 로그에 RTE의 구성이 누락되어 있음을 보여줍니다.
Info: couldn't find configuration in "/etc/resource-topology-exporter/config.yaml"
이 로그 메시지는 필요한 구성이 있는 kubeletconfig 가 클러스터에 제대로 적용되지 않아 RTE configmap 이 누락되었음을 나타냅니다. 예를 들어 다음 클러스터에 numaresourcesoperator-worker configmap CR (사용자 정의 리소스)이 없습니다.
$ oc get configmap
출력 예
NAME DATA AGE 0e2a6bd3.openshift-kni.io 0 6d21h kube-root-ca.crt 1 6d21h openshift-service-ca.crt 1 6d21h topo-aware-scheduler-config 1 6d18h
올바르게 구성된 클러스터에서 oc get configmap 도 numaresourcesoperator-worker configmap CR을 반환합니다.
사전 요구 사항
-
OpenShift Container Platform CLI (
oc)를 설치합니다. - cluster-admin 권한이 있는 사용자로 로그인합니다.
- NUMA Resources Operator를 설치하고 NUMA 인식 보조 스케줄러를 배포합니다.
프로세스
다음 명령을 사용하여
MachineConfigPool(mcp) 작업자 CR의spec.machineConfigPoolSelector.matchLabels값과kubeletconfig및metadata.labels의 값을 비교합니다.다음 명령을 실행하여
kubeletconfig레이블을 확인합니다.$ oc get kubeletconfig -o yaml
출력 예
machineConfigPoolSelector: matchLabels: cnf-worker-tuning: enabled다음 명령을 실행하여
mcp레이블을 확인합니다.$ oc get mcp worker -o yaml
출력 예
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: ""
cnf-worker-tuning: enabled레이블은MachineConfigPool오브젝트에 없습니다.
누락된 라벨을 포함하도록
MachineConfigPoolCR을 편집합니다. 예를 들면 다음과 같습니다.$ oc edit mcp worker -o yaml
출력 예
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: "" cnf-worker-tuning: enabled
- 레이블 변경 사항을 적용하고 클러스터가 업데이트된 구성을 적용할 때까지 기다립니다. 다음 명령을 실행합니다.
검증
누락된
numaresourcesoperator-workerconfigmapCR이 적용되었는지 확인합니다.$ oc get configmap
출력 예
NAME DATA AGE 0e2a6bd3.openshift-kni.io 0 6d21h kube-root-ca.crt 1 6d21h numaresourcesoperator-worker 1 5m openshift-service-ca.crt 1 6d21h topo-aware-scheduler-config 1 6d18h
6.6.4. NUMA Resources Operator 데이터 수집
oc adm must-gather CLI 명령을 사용하여 NUMA Resources Operator와 관련된 기능 및 오브젝트를 포함하여 클러스터에 대한 정보를 수집할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
must-gather를 사용하여 NUMA Resources Operator 데이터를 수집하려면 NUMA Resources Operatormust-gather이미지를 지정해야 합니다.$ oc adm must-gather --image=registry.redhat.io/numaresources-must-gather/numaresources-must-gather-rhel9:4.15
7장. 확장성 및 성능 최적화
7.1. 스토리지 최적화
스토리지를 최적화하면 모든 리소스에서 스토리지 사용을 최소화할 수 있습니다. 관리자는 스토리지를 최적화하여 기존 스토리지 리소스가 효율적으로 작동하도록 합니다.
7.1.1. 사용 가능한 영구 스토리지 옵션
OpenShift Container Platform 환경을 최적화할 수 있도록 영구 스토리지 옵션에 대해 알아보십시오.
표 7.1. 사용 가능한 스토리지 옵션
| 스토리지 유형 | 설명 | 예 |
|---|---|---|
| 블록 |
| AWS EBS 및 VMware vSphere는 OpenShift Container Platform에서 기본적으로 동적 PV(영구 볼륨) 프로비저닝을 지원합니다. |
| 파일 |
| RHEL NFS, NetApp NFS [1] 및 Vendor NFS |
| 개체 |
| AWS S3 |
- NetApp NFS는 Trident 플러그인을 사용할 때 동적 PV 프로비저닝을 지원합니다.
7.1.2. 권장되는 구성 가능한 스토리지 기술
다음 표에는 지정된 OpenShift Container Platform 클러스터 애플리케이션에 권장되는 구성 가능한 스토리지 기술이 요약되어 있습니다.
표 7.2. 권장되는 구성 가능한 스토리지 기술
| 스토리지 유형 | 블록 | 파일 | 개체 |
|---|---|---|---|
|
1
2 3 Prometheus는 메트릭에 사용되는 기본 기술입니다. 4 물리적 디스크, VM 물리적 디스크, VMDK, NFS를 통한 루프백, AWS EBS 및 Azure Disk에는 적용되지 않습니다.
5 메트릭의 경우 RWX( 6 로깅의 경우 로그 저장소에 대한 영구 스토리지 구성 섹션에서 권장 스토리지 솔루션을 검토하십시오. NFS 스토리지를 영구 볼륨으로 사용하거나 Gluster와 같은 NAS를 통해 데이터가 손상될 수 있습니다. 따라서 OpenShift Container Platform Logging의 Elasticsearch 스토리지 및 LokiStack 로그 저장소에서는 NFS가 지원되지 않습니다. 로그 저장소당 하나의 영구 볼륨 유형을 사용해야 합니다. 7 OpenShift Container Platform의 PV 또는 PVC를 통해서는 오브젝트 스토리지가 사용되지 않습니다. 앱은 오브젝트 스토리지 REST API와 통합해야 합니다. | |||
| ROX1 | 제공됨4 | 제공됨4 | 제공됨 |
| RWX2 | 없음 | 제공됨 | 제공됨 |
| 레지스트리 | 구성 가능 | 구성 가능 | 권장 |
| 확장 레지스트리 | 구성 불가능 | 구성 가능 | 권장 |
| Metrics3 | 권장 | 구성 가능5 | 구성 불가능 |
| Elasticsearch 로깅 | 권장 | 구성 가능6 | 지원되지 않음6 |
| Loki 로깅 | 구성 불가능 | 구성 불가능 | 권장 |
| 앱 | 권장 | 권장 | 구성 불가능7 |
확장 레지스트리는 두 개 이상의 pod 복제본이 실행되는 OpenShift 이미지 레지스트리입니다.
7.1.2.1. 특정 애플리케이션 스토리지 권장 사항
테스트에서는 RHEL(Red Hat Enterprise Linux)의 NFS 서버를 핵심 서비스용 스토리지 백엔드로 사용하는 데 문제가 있는 것을 보여줍니다. 여기에는 OpenShift Container Registry and Quay, 스토리지 모니터링을 위한 Prometheus, 로깅 스토리지를 위한 Elasticsearch가 포함됩니다. 따라서 RHEL NFS를 사용하여 핵심 서비스에서 사용하는 PV를 백업하는 것은 권장되지 않습니다.
마켓플레이스의 다른 NFS 구현에는 이러한 문제가 나타나지 않을 수 있습니다. 이러한 OpenShift Container Platform 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 공급업체에 문의하십시오.
7.1.2.1.1. 레지스트리
비확장/HA(고가용성) OpenShift 이미지 레지스트리 클러스터 배포에서 다음을 수행합니다.
- 스토리지 기술에서 RWX 액세스 모드를 지원할 필요가 없습니다.
- 스토리지 기술에서 쓰기 후 읽기 일관성을 보장해야 합니다.
- 기본 스토리지 기술은 오브젝트 스토리지, 블록 스토리지 순입니다.
- 프로덕션 워크로드가 있는 OpenShift 이미지 레지스트리 클러스터 배포에는 파일 스토리지를 사용하지 않는 것이 좋습니다.
7.1.2.1.2. 확장 레지스트리
확장/HA OpenShift 이미지 레지스트리 클러스터 배포에서 다음을 수행합니다.
- 스토리지 기술은 RWX 액세스 모드를 지원해야 합니다.
- 스토리지 기술에서 쓰기 후 읽기 일관성을 보장해야 합니다.
- 기본 스토리지 기술은 오브젝트 스토리지입니다.
- Red Hat OpenShift Data Foundation(ODF), Amazon Simple Storage Service(Amazon S3), GCS(Google Cloud Storage), Microsoft Azure Blob Storage 및 OpenStack Swift가 지원됩니다.
- 오브젝트 스토리지는 S3 또는 Swift와 호환되어야 합니다.
- vSphere, 베어 메탈 설치 등 클라우드 이외의 플랫폼에서는 구성 가능한 유일한 기술이 파일 스토리지입니다.
- 블록 스토리지는 구성 불가능합니다.
7.1.2.1.3. 지표
OpenShift Container Platform 호스트 지표 클러스터 배포에서는 다음 사항에 유의합니다.
- 기본 스토리지 기술은 블록 스토리지입니다.
- 오브젝트 스토리지는 구성 불가능합니다.
프로덕션 워크로드가 있는 호스트 지표 클러스터 배포에는 파일 스토리지를 사용하지 않는 것이 좋습니다.
7.1.2.1.4. 로깅
OpenShift Container Platform 호스트 로깅 클러스터 배포에서는 다음 사항에 유의합니다.
Loki Operator:
- 기본 스토리지 기술은 S3 호환 오브젝트 스토리지입니다.
- 블록 스토리지는 구성 불가능합니다.
OpenShift Elasticsearch Operator:
- 기본 스토리지 기술은 블록 스토리지입니다.
- 오브젝트 스토리지는 지원되지 않습니다.
로깅 버전 5.4.3부터 OpenShift Elasticsearch Operator는 더 이상 사용되지 않으며 향후 릴리스에서 제거될 예정입니다. Red Hat은 현재 릴리스 라이프사이클 동안 이 기능에 대한 버그 수정 및 지원을 제공하지만 이 기능은 더 이상 개선 사항을 받지 않으며 제거됩니다. OpenShift Elasticsearch Operator를 사용하여 기본 로그 스토리지를 관리하는 대신 Loki Operator를 사용할 수 있습니다.
7.1.2.1.5. 애플리케이션
애플리케이션 사용 사례는 다음 예에 설명된 대로 애플리케이션마다 다릅니다.
- 동적 PV 프로비저닝을 지원하는 스토리지 기술은 마운트 대기 시간이 짧고 정상 클러스터를 지원하는 노드와 관련이 없습니다.
- 애플리케이션 개발자는 애플리케이션의 스토리지 요구사항을 잘 알고 있으며 제공된 스토리지로 애플리케이션을 작동시켜 애플리케이션이 스토리지 계층을 스케일링하거나 스토리지 계층과 상호 작용할 때 문제가 발생하지 않도록 하는 방법을 이해하고 있어야 합니다.
7.1.2.2. 다른 특정 애플리케이션 스토리지 권장 사항
etcd 와 같은 쓰기 집약적 워크로드에서는 RAID 구성을 사용하지 않는 것이 좋습니다. RAID 구성으로 etcd 를 실행하는 경우 워크로드에 성능 문제가 발생할 위험이 있을 수 있습니다.
- RHOSP(Red Hat OpenStack Platform) Cinder: RHOSP Cinder는 ROX 액세스 모드 사용 사례에 적합합니다.
- 데이터베이스: 데이터베이스(RDBMS, NoSQL DB 등)는 전용 블록 스토리지를 사용하는 경우 성능이 최대화되는 경향이 있습니다.
- etcd 데이터베이스에는 대규모 클러스터를 활성화하기 위해 충분한 스토리지와 적절한 성능 용량이 있어야 합니다. 충분한 스토리지 및 고성능 환경을 구축하기 위한 모니터링 및 벤치마킹 툴에 대한 정보는 권장 etcd 관행에 설명되어 있습니다.
7.1.3. 데이터 스토리지 관리
다음 표에는 OpenShift Container Platform 구성 요소가 데이터를 쓰는 기본 디렉터리가 요약되어 있습니다.
표 7.3. OpenShift Container Platform 데이터를 저장하는 기본 디렉터리
| 디렉터리 | 참고 | 크기 조정 | 예상 증가 |
|---|---|---|---|
| /var/log | 모든 구성 요소의 로그 파일입니다. | 10~30GB입니다. | 로그 파일이 빠르게 증가할 수 있습니다. 크기는 디스크를 늘리거나 로그 회전을 사용하여 관리할 수 있습니다. |
| /var/lib/etcd | 데이터베이스를 저장할 때 etcd 스토리지에 사용됩니다. | 20GB 미만입니다. 데이터베이스는 최대 8GB까지 증가할 수 있습니다. | 환경과 함께 천천히 증가합니다. 메타데이터만 저장합니다. 추가로 메모리가 8GB 증가할 때마다 추가로 20~25GB가 증가합니다. |
| /var/lib/containers | CRI-O 런타임의 마운트 옵션입니다. Pod를 포함한 활성 컨테이너 런타임에 사용되는 스토리지 및 로컬 이미지 스토리지입니다. 레지스트리 스토리지에는 사용되지 않습니다. | 16GB 메모리가 있는 노드의 경우 50GB가 증가합니다. 이 크기 조정은 최소 클러스터 요구사항을 결정하는 데 사용하면 안 됩니다. 추가로 메모리가 8GB 증가할 때마다 추가로 20~25GB가 증가합니다. | 컨테이너 실행 용량에 의해 증가가 제한됩니다. |
| /var/lib/kubelet | Pod용 임시 볼륨 스토리지입니다. 런타임 시 컨테이너로 마운트된 외부 요소가 모두 포함됩니다. 영구 볼륨에서 지원하지 않는 환경 변수, kube 보안 및 데이터 볼륨이 포함됩니다. | 변동 가능 | 스토리지가 필요한 Pod가 영구 볼륨을 사용하는 경우 최소입니다. 임시 스토리지를 사용하는 경우 빠르게 증가할 수 있습니다. |
7.1.4. Microsoft Azure에 대한 스토리지 성능 최적화
OpenShift Container Platform 및 Kubernetes는 디스크 성능에 민감하며 특히 컨트롤 플레인 노드의 etcd에 더 빠른 스토리지를 사용하는 것이 좋습니다.
워크로드가 집약적인 프로덕션 Azure 클러스터 및 클러스터의 경우 컨트롤 플레인 시스템의 가상 머신 운영 체제 디스크는 5000 IOPS / 200MBps의 테스트 및 권장 최소 처리량을 유지할 수 있어야 합니다. 이 처리량은 최소 1 TiB Premium SSD (P30)를 보유하여 제공할 수 있습니다. Azure 및 Azure Stack Hub에서 디스크 성능은 SSD 디스크 크기에 따라 직접 달라집니다. Standard_D8s_v3 가상 머신 또는 기타 유사한 시스템 유형에서 지원하는 처리량과 5000 IOPS 대상을 달성하려면 최소 P30 디스크가 필요합니다.
데이터를 읽을 때 대기 시간이 짧고 IOPS 및 처리량은 호스트 캐싱을 ReadOnly 로 설정해야 합니다. VM 메모리 또는 로컬 SSD 디스크에 있는 캐시에서 데이터를 읽는 것은 Blob 스토리지에 있는 디스크에서 읽기보다 훨씬 빠릅니다.
7.1.5. 추가 리소스
7.2. 라우팅 최적화
OpenShift Container Platform HAProxy 라우터는 성능을 최적화하도록 스케일링하거나 구성할 수 있습니다.
7.2.1. 기본 Ingress 컨트롤러(라우터) 성능
OpenShift Container Platform Ingress 컨트롤러 또는 라우터는 경로 및 인그레스를 사용하여 구성된 애플리케이션 및 서비스의 수신 트래픽의 수신 지점입니다.
초당 처리된 HTTP 요청 측면에서 단일 HAProxy 라우터 성능을 평가할 때 성능은 여러 요인에 따라 달라집니다. 특히 중요한 요인은 다음과 같습니다.
- HTTP 연결 유지/닫기 모드
- 경로 유형
- TLS 세션 재개 클라이언트 지원
- 대상 경로당 동시 연결 수
- 대상 경로 수
- 백엔드 서버 페이지 크기
- 기본 인프라(네트워크/SDN 솔루션, CPU 등)
특정 환경의 성능은 달라질 수 있으나 Red Hat 랩은 크기가 4 vCPU/16GB RAM인 퍼블릭 클라우드 인스턴스에서 테스트합니다. 1kB 정적 페이지를 제공하는 백엔드에서 종료한 100개의 경로를 처리하는 단일 HAProxy 라우터가 처리할 수 있는 초당 트랜잭션 수는 다음과 같습니다.
HTTP 연결 유지 모드 시나리오에서는 다음과 같습니다.
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 21515 | 29622 |
| edge | 16743 | 22913 |
| passthrough | 36786 | 53295 |
| re-encrypt | 21583 | 25198 |
HTTP 닫기(연결 유지 제외) 시나리오에서는 다음과 같습니다.
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 5719 | 8273 |
| edge | 2729 | 4069 |
| passthrough | 4121 | 5344 |
| re-encrypt | 2320 | 2941 |
기본 Ingress 컨트롤러 구성은 spec.tuningOptions.threadCount 필드와 함께 4 로 설정되었습니다. 로드 밸런서 서비스와 호스트 네트워크라는 두 가지 끝점 게시 전략이 테스트되었습니다. 암호화된 경로에는 TLS 세션 재개가 사용되었습니다. HTTP 연결 유지를 사용하면 단일 HAProxy 라우터가 8kB의 작은 페이지 크기에서 1Gbit NIC를 포화할 수 있습니다.
최신 프로세서가 있는 베어 메탈에서 실행하는 경우 성능이 위 퍼블릭 클라우드 인스턴스의 약 2배가 될 것을 예상할 수 있습니다. 이 오버헤드는 퍼블릭 클라우드에서 가상화 계층에 의해 도입되며 프라이빗 클라우드 기반 가상화에도 적용됩니다. 다음 표는 라우터 뒤에서 사용할 애플리케이션 수에 대한 가이드입니다.
| 애플리케이션 수 | 애플리케이션 유형 |
|---|---|
| 5-10 | 정적 파일/웹 서버 또는 캐싱 프록시 |
| 100-1000 | 동적 콘텐츠를 생성하는 애플리케이션 |
일반적으로 HAProxy는 사용 중인 기술에 따라 최대 1000개의 애플리케이션에 대한 경로를 지원할 수 있습니다. Ingress 컨트롤러 성능은 언어 또는 정적 콘텐츠 대비 동적 콘텐츠 등 지원하는 애플리케이션의 기능과 성능에 따라 제한될 수 있습니다.
Ingress 또는 라우터 샤딩을 사용하여 애플리케이션에 대한 경로를 더 많이 제공하면 라우팅 계층을 수평으로 확장하는 데 도움이 됩니다.
Ingress 샤딩에 대한 자세한 내용은 경로 라벨을 사용하여 Ingress 컨트롤러 분할 구성 및 네임스페이스 라벨 을 사용하여 Ingress 컨트롤러 샤딩 구성을 참조하십시오.
시간 초과에 대한 Ingress 컨트롤러 스레드 수 설정 및 Ingress 컨트롤러 사양의 기타 튜닝 구성에 제공된 정보를 사용하여 Ingress 컨트롤러 배포를 수정할 수 있습니다.
7.2.2. Ingress 컨트롤러 활성, 준비 상태 및 시작 프로브 구성
클러스터 관리자는 OpenShift Container Platform Ingress 컨트롤러(라우터)에서 관리하는 라우터 배포를 위해 kubelet의 활성 상태, 준비 상태 및 시작 프로브에 대한 시간 초과 값을 구성할 수 있습니다. 라우터의 활성 상태 및 준비 상태 프로브는 기본 시간 제한 값 1초를 사용합니다. 이 값은 네트워킹 또는 런타임 성능이 심각하게 저하될 때 너무 짧습니다. 프로브 시간 초과로 인해 애플리케이션 연결을 중단하는 원치 않는 라우터가 다시 시작될 수 있습니다. 더 큰 시간 초과 값을 설정하는 기능은 불필요하고 원하지 않는 재시작 위험을 줄일 수 있습니다.
router 컨테이너의 livenessProbe,readinessProbe 및 startupProbe 매개변수에서 timeoutSeconds 값을 업데이트할 수 있습니다.
| 매개변수 | 설명 |
|---|---|
|
|
|
|
|
|
|
|
|
시간 제한 구성 옵션은 문제를 해결하는 데 사용할 수 있는 고급 튜닝 기술입니다. 그러나 이러한 문제는 결국 진단되고 프로브가 시간 초과되는 문제에 대해 지원 케이스 또는 Jira 문제가 열려 있어야 합니다.
다음 예제에서는 기본 라우터 배포를 직접 패치하여 활성 상태 프로브 및 준비 상태 프로브에 대해 5초의 타임아웃을 설정하는 방법을 보여줍니다.
$ oc -n openshift-ingress patch deploy/router-default --type=strategic --patch='{"spec":{"template":{"spec":{"containers":[{"name":"router","livenessProbe":{"timeoutSeconds":5},"readinessProbe":{"timeoutSeconds":5}}]}}}}'검증
$ oc -n openshift-ingress describe deploy/router-default | grep -e Liveness: -e Readiness:
Liveness: http-get http://:1936/healthz delay=0s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:1936/healthz/ready delay=0s timeout=5s period=10s #success=1 #failure=3
7.2.3. HAProxy 재로드 간격 구성
경로와 연결된 경로 또는 끝점을 업데이트하면 OpenShift Container Platform 라우터에서 HAProxy 구성을 업데이트합니다. 그런 다음 HAProxy는 이러한 변경 사항을 적용하기 위해 업데이트된 구성을 다시 로드합니다. HAProxy가 다시 로드되면 업데이트된 구성을 사용하여 새 연결을 처리하는 새 프로세스가 생성됩니다.
HAProxy는 이러한 연결이 모두 종료될 때까지 기존 프로세스를 계속 실행하여 기존 연결을 처리합니다. 이전 프로세스에 수명이 긴 연결이 있는 경우 이러한 프로세스는 리소스를 누적하고 사용할 수 있습니다.
기본 최소 HAProxy 재로드 간격은 5초입니다. spec.tuningOptions.reloadInterval 필드를 사용하여 Ingress 컨트롤러를 구성하여 최소 다시 로드 간격을 더 오래 설정할 수 있습니다.
최소 HAProxy 재로드 간격에 대해 큰 값을 설정하면 경로 및 엔드포인트에 대한 업데이트를 관찰하는 대기 시간이 발생할 수 있습니다. 위험을 줄이려면 업데이트에 허용되는 대기 시간보다 큰 값을 설정하지 마십시오.
프로세스
다음 명령을 실행하여 기본 Ingress 컨트롤러의 최소 HAProxy 재로드 간격을 15초로 변경합니다.
$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"tuningOptions":{"reloadInterval":"15s"}}}'
7.3. 네트워킹 최적화
OpenShift SDN 은 OpenvSwitch, VXLAN(Virtualxtensible LAN) 터널, OpenFlow 규칙 및 iptables를 사용합니다. 이 네트워크는 점보 프레임, 다중 큐 및 ethtool 설정을 사용하여 조정할 수 있습니다.
OVN-Kubernetes 는 VXLAN 대신 일반 네트워크 가상화 캡슐화(Geneve)를 터널 프로토콜로 사용합니다. 이 네트워크는 NIC(네트워크 인터페이스 컨트롤러) 오프로드를 사용하여 조정할 수 있습니다.
VXLAN은 VLAN에 비해 네트워크 수가 4096개에서 1600만 개 이상으로 증가하고 물리적 네트워크 전반에 걸쳐 계층 2 연결과 같은 이점을 제공합니다. 이를 통해 서비스 뒤에 있는 모든 Pod가 서로 다른 시스템에서 실행되는 경우에도 서로 통신할 수 있습니다.
VXLAN은 사용자 데이터그램 프로토콜(UDP) 패킷의 터널링된 모든 트래픽을 캡슐화합니다. 그러나 이로 인해 CPU 사용량이 증가합니다. 이러한 외부 및 내부 패킷은 전송 중에 데이터가 손상되지 않도록하기 위해 일반 체크섬 규칙을 따릅니다. CPU 성능에 따라 이러한 추가 처리 오버헤드는 처리량이 감소하고 기존 비 오버레이 네트워크에 비해 대기 시간이 증가할 수 있습니다.
클라우드, 가상 머신, 베어 메탈 CPU 성능은 많은 Gbps의 네트워크 처리량을 처리할 수 있습니다. 10 또는 40Gbps와 같은 높은 대역폭 링크를 사용하는 경우 성능이 저하될 수 있습니다. 이 문제는 VXLAN 기반 환경에서 알려진 문제이며 컨테이너 또는 OpenShift Container Platform에만 국한되지 않습니다. VXLAN 터널에 의존하는 네트워크는 VXLAN 구현으로 인해 비슷한 작업을 수행할 수 있습니다.
Gbps을 초과하여 푸시하려는 경우 다음을 수행할 수 있습니다.
- BGP(Border Gateway Protocol)와 같은 다양한 라우팅 기술을 구현하는 네트워크 플러그인을 평가합니다.
- VXLAN 오프로드 가능 네트워크 어댑터를 사용합니다. VXLAN 오프로드는 패킷 체크섬 계산 및 관련 CPU 오버헤드를 시스템 CPU에서 네트워크 어댑터의 전용 하드웨어로 이동합니다. 이를 통해 Pod 및 애플리케이션에서 사용할 CPU 사이클을 확보하고 사용자는 네트워크 인프라의 전체 대역폭을 사용할 수 있습니다.
VXLAN 오프로드는 대기 시간을 단축시키지 않습니다. 그러나 대기 시간 테스트에서도 CPU 사용량이 감소합니다.
7.3.1. 네트워크에 대한 MTU 최적화
중요한 MTU(최대 전송 단위)에는 NIC(네트워크 인터페이스 컨트롤러) MTU와 클러스터 네트워크 MTU가 있습니다.
NIC MTU는 OpenShift Container Platform을 설치할 때만 구성됩니다. MTU는 네트워크 NIC에서 지원되는 최대 값과 작거나 같아야 합니다. 처리량을 최적화하려면 가능한 가장 큰 값을 선택합니다. 최소 지연을 최적화하려면 더 낮은 값을 선택합니다.
OpenShift SDN 네트워크 플러그인 오버레이 MTU는 NIC MTU보다 최소 50바이트 작아야 합니다. 이 계정은 SDN 오버레이 헤더에 대한 계정입니다. 따라서 일반 이더넷 네트워크에서 1450 으로 설정해야 합니다. 점보 프레임 이더넷 네트워크에서 8950 으로 설정해야 합니다. 이러한 값은 NIC의 구성된 MTU를 기반으로 Cluster Network Operator에서 자동으로 설정해야 합니다. 따라서 클러스터 관리자는 일반적으로 이러한 값을 업데이트하지 않습니다. AWS(Amazon Web Services) 및 베어 메탈 환경은 점보 프레임 이더넷 네트워크를 지원합니다. 이 설정은 특히 TCP(전송 제어 프로토콜)에서 처리량에 도움이 됩니다.
OpenShift SDN CNI는 OpenShift Container Platform 4.14에서 더 이상 사용되지 않습니다. OpenShift Container Platform 4.15부터 네트워크 플러그인은 새 설치를 위한 옵션이 아닙니다. 향후 릴리스에서 OpenShift SDN 네트워크 플러그인은 제거될 예정이며 더 이상 지원되지 않습니다. Red Hat은 제거될 때까지 이 기능에 대한 버그 수정 및 지원을 제공하지만 이 기능은 더 이상 개선 사항을 받지 않습니다. OpenShift SDN CNI 대신 OVN Kubernetes CNI를 대신 사용할 수 있습니다.
OVN 및 Geneve의 경우 MTU는 NIC MTU보다 최소 100바이트 작아야 합니다.
이 50바이트 오버레이 헤더는 OpenShift SDN 네트워크 플러그인과 관련이 있습니다. 기타 SDN 솔루션에서는 이 값이 더 크거나 작아야 할 수 있습니다.
7.3.2. 대규모 클러스터 설치에 대한 권장 사례
대규모 클러스터를 설치하거나 클러스터 스케일링을 통해 노드 수를 늘리는 경우 install-config.yaml 파일에서 클러스터 네트워크 cidr을 적절하게 설정한 후 클러스터를 설치하십시오.
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- 172.30.0.0/16
클러스터 크기가 500개 노드를 초과하는 경우 기본 클러스터 네트워크 cidr 10.128.0.0/14를 사용할 수 없습니다. 노드 수가 500개를 초과하게 되면 10.128.0.0/12 또는 10.128.0.0/10으로 설정해야 합니다.
7.3.3. IPsec 영향
노드 호스트의 암호화 및 암호 해독은 CPU를 사용하기 때문에 사용 중인 IP 보안 시스템에 관계없이 암호화를 사용할 때 노드의 처리량과 CPU 사용량 모두에서 성능에 영향을 미칩니다.
IPsec은 NIC에 도달하기 전에 IP 페이로드 수준에서 트래픽을 암호화하여 NIC 오프로드에 사용되는 필드를 보호합니다. 즉, IPSec가 활성화되면 일부 NIC 가속 기능을 사용할 수 없으며 처리량이 감소하고 CPU 사용량이 증가합니다.
7.3.4. 추가 리소스
7.4. 마운트 네임스페이스 캡슐화를 사용하여 CPU 사용량 최적화
마운트 네임스페이스 캡슐화를 사용하여 kubelet 및 CRI-O 프로세스의 프라이빗 네임스페이스를 제공하여 OpenShift Container Platform 클러스터에서 CPU 사용량을 최적화할 수 있습니다. 이렇게 하면 기능 차이가 없이 systemd에서 사용하는 클러스터 CPU 리소스가 줄어듭니다.
마운트 네임스페이스 캡슐화는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
7.4.1. 마운트 네임스페이스 캡슐화
마운트 네임스페이스는 다른 네임스페이스의 프로세스에서 서로의 파일을 볼 수 없도록 마운트 지점을 분리하는 데 사용됩니다. 캡슐화는 Kubernetes 마운트 네임스페이스를 호스트 운영 체제에서 지속적으로 검사하지 않는 대체 위치로 이동하는 프로세스입니다.
호스트 운영 체제는 systemd를 사용하여 모든 마운트 네임스페이스를 지속적으로 검사합니다. 표준 Linux 마운트와 Kubernetes가 작동하는 데 사용하는 수많은 마운트 모두입니다. kubelet 및 CRI-O의 현재 구현은 모든 컨테이너 런타임 및 kubelet 마운트 지점에 최상위 네임스페이스를 사용합니다. 그러나 프라이빗 네임스페이스에서 이러한 컨테이너별 마운트 지점을 캡슐화하면 기능 차이가 없이 systemd 오버헤드가 줄어듭니다. CRI-O 및 kubelet 모두에 별도의 마운트 네임스페이스를 사용하면 systemd 또는 기타 호스트 운영 체제 상호 작용의 컨테이너별 마운트를 캡슐화할 수 있습니다.
이제 모든 OpenShift Container Platform 관리자가 주요 CPU 최적화를 수행할 수 있는 이 기능을 사용할 수 있습니다. Encapsulation은 권한이 없는 사용자가 검사한 위치에서 Kubernetes별 마운트 지점을 저장하여 보안을 개선할 수도 있습니다.
다음 다이어그램은 캡슐화 전후의 Kubernetes 설치를 보여줍니다. 두 시나리오 모두 양방향, host-to-container 및 none의 마운트 전파 설정이 있는 예제 컨테이너를 표시합니다.
여기에서는 단일 마운트 네임스페이스를 공유하는 systemd, 호스트 운영 체제 프로세스, kubelet 및 컨테이너 런타임을 참조하십시오.
- systemd, 호스트 운영 체제 프로세스, kubelet 및 컨테이너 런타임은 각각 모든 마운트 지점에 대한 액세스 및 가시성을 갖습니다.
-
양방향 마운트 전파로 구성된 컨테이너 1은 systemd 및 호스트 마운트, kubelet 및 CRI-O 마운트에 액세스할 수 있습니다.
/run/a와 같은 컨테이너 1에 있는 마운트는 systemd, 호스트 운영 체제 프로세스, kubelet, 컨테이너 런타임 및 호스트-컨테이너 또는 양방향 마운트 전파가 구성된 기타 컨테이너에 표시됩니다(컨테이너 2에서와 같이). -
컨테이너 2는 host-to-container 마운트 전파로 구성되며 systemd 및 호스트 마운트, kubelet 및 CRI-O 마운트에 액세스할 수 있습니다.
/run/b와 같은 컨테이너 2에서 시작된 마운트는 다른 컨텍스트에 표시되지 않습니다. -
마운트 전파 없이 구성된 컨테이너 3은 외부 마운트 지점을 확인할 수 없습니다.
/run/c와 같은 컨테이너 3에서 시작되는 마운트는 다른 컨텍스트에 표시되지 않습니다.
다음 다이어그램은 캡슐화 후 시스템 상태를 보여줍니다.
- 기본 systemd 프로세스는 더 이상 Kubernetes별 마운트 지점의 불필요한 검색에 영향을 미치지 않습니다. systemd 관련 및 호스트 마운트 지점만 모니터링합니다.
- 호스트 운영 체제 프로세스는 systemd 및 호스트 마운트 지점에만 액세스할 수 있습니다.
- CRI-O 및 kubelet 모두에 별도의 마운트 네임스페이스를 사용하면 모든 컨테이너별 마운트를 systemd 또는 기타 호스트 운영 체제 상호 작용과 완전히 분리합니다.
-
/run/a와 같이 생성되는 마운트는 더 이상 systemd 또는 호스트 운영 체제 프로세스에 표시되지 않는 경우를 제외하고 컨테이너 1의 동작은 변경되지 않습니다. kubelet, CRI-O 및 host-to-container 또는 양방향 마운트 전파가 구성된 기타 컨테이너(예: 컨테이너 2)에 계속 표시됩니다. - 컨테이너 2 및 컨테이너 3의 동작은 변경되지 않습니다.
7.4.2. 마운트 네임스페이스 캡슐화 구성
클러스터가 리소스 오버헤드로 실행되도록 마운트 네임스페이스 캡슐화를 구성할 수 있습니다.
마운트 네임스페이스 캡슐화는 기술 프리뷰 기능이며 기본적으로 비활성화되어 있습니다. 이 기능을 사용하려면 수동으로 기능을 활성화해야 합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다.
프로세스
다음 YAML을 사용하여
mount_namespace_config.yaml이라는 파일을 생성합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 99-kubens-master spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.service --- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 99-kubens-worker spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.service다음 명령을 실행하여 마운트 네임스페이스
MachineConfigCR을 적용합니다.$ oc apply -f mount_namespace_config.yaml
출력 예
machineconfig.machineconfiguration.openshift.io/99-kubens-master created machineconfig.machineconfiguration.openshift.io/99-kubens-worker created
MachineConfigCR은 클러스터에 적용되는 데 최대 30분이 걸릴 수 있습니다. 다음 명령을 실행하여MachineConfigCR의 상태를 확인할 수 있습니다.$ oc get mcp
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-03d4bc4befb0f4ed3566a2c8f7636751 False True False 3 0 0 0 45m worker rendered-worker-10577f6ab0117ed1825f8af2ac687ddf False True False 3 1 1
다음 명령을 실행한 후
MachineConfigCR이 모든 컨트롤 플레인 및 작업자 노드에 성공적으로 적용될 때까지 기다립니다.$ oc wait --for=condition=Updated mcp --all --timeout=30m
출력 예
machineconfigpool.machineconfiguration.openshift.io/master condition met machineconfigpool.machineconfiguration.openshift.io/worker condition met
검증
클러스터 호스트의 캡슐화를 확인하려면 다음 명령을 실행합니다.
클러스터 호스트에 대한 디버그 쉘을 엽니다.
$ oc debug node/<node_name>
chroot세션을 엽니다.sh-4.4# chroot /host
systemd 마운트 네임스페이스를 확인합니다.
sh-4.4# readlink /proc/1/ns/mnt
출력 예
mnt:[4026531953]
kubelet 마운트 네임스페이스를 확인합니다.
sh-4.4# readlink /proc/$(pgrep kubelet)/ns/mnt
출력 예
mnt:[4026531840]
CRI-O 마운트 네임스페이스를 확인합니다.
sh-4.4# readlink /proc/$(pgrep crio)/ns/mnt
출력 예
mnt:[4026531840]
이러한 명령은 systemd, kubelet 및 컨테이너 런타임과 관련된 마운트 네임스페이스를 반환합니다. OpenShift Container Platform에서 컨테이너 런타임은 CRI-O입니다.
위 예제와 같이 systemd가 kubelet 및 CRI-O에 다른 마운트 네임스페이스에 있는 경우 Encapsulation이 적용됩니다. 3개의 프로세스가 모두 동일한 마운트 네임스페이스에 있는 경우 캡슐화는 적용되지 않습니다.
7.4.3. 캡슐화된 네임스페이스 검사
RHCOS(Red Hat Enterprise Linux CoreOS)에서 사용할 수 있는 kubensenter 스크립트를 사용하여 디버깅 또는 감사 목적으로 클러스터 호스트 운영 체제의 Kubernetes별 마운트 지점을 검사할 수 있습니다.
클러스터 호스트에 대한 SSH 쉘 세션은 기본 네임스페이스에 있습니다. SSH 쉘 프롬프트에서 Kubernetes별 마운트 지점을 검사하려면 kubensenter 스크립트를 root로 실행해야 합니다. kubensenter 스크립트는 마운트 캡슐화 상태를 알고 있으며 캡슐화가 활성화되지 않은 경우에도 실행하는 것이 안전합니다.
oc debug 원격 쉘 세션은 기본적으로 Kubernetes 네임스페이스 내에서 시작됩니다. oc debug 를 사용할 때 마운트 지점을 검사하기 위해 kubensenter 를 실행할 필요가 없습니다.
캡슐화 기능이 활성화되지 않은 경우 kubensenter findmnt 및 findmnt 명령은 oc debug 세션 또는 SSH 쉘 프롬프트에서 실행되는지 여부에 관계없이 동일한 출력을 반환합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다. - 클러스터 호스트에 대한 SSH 액세스를 구성했습니다.
프로세스
클러스터 호스트에 대한 원격 SSH 쉘을 엽니다. 예를 들면 다음과 같습니다.
$ ssh core@<node_name>
제공된
kubensenter스크립트를 root 사용자로 사용하여 명령을 실행합니다. Kubernetes 네임스페이스 내에서 단일 명령을 실행하려면 명령과kubensenter스크립트에 인수를 제공합니다. 예를 들어 Kubernetes 네임스페이스 내에서findmnt명령을 실행하려면 다음 명령을 실행합니다.[core@control-plane-1 ~]$ sudo kubensenter findmnt
출력 예
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt TARGET SOURCE FSTYPE OPTIONS / /dev/sda4[/ostree/deploy/rhcos/deploy/32074f0e8e5ec453e56f5a8a7bc9347eaa4172349ceab9c22b709d9d71a3f4b0.0] | xfs rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,prjquota shm tmpfs ...Kubernetes 네임스페이스 내에서 새 대화형 쉘을 시작하려면 인수 없이
kubensenter스크립트를 실행합니다.[core@control-plane-1 ~]$ sudo kubensenter
출력 예
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt
7.4.4. 캡슐화된 네임스페이스에서 추가 서비스 실행
호스트 운영 체제에서 실행하는 기능을 사용하고 kubelet, CRI-O 또는 컨테이너 자체에서 생성한 마운트 지점을 확인할 수 있는 모니터링 툴은 이러한 마운트 지점을 확인하기 위해 컨테이너 마운트 네임스페이스를 입력해야 합니다. OpenShift Container Platform과 함께 제공되는 kubensenter 스크립트는 Kubernetes 마운트 지점 내에서 다른 명령을 실행하고 기존 툴을 조정하는 데 사용할 수 있습니다.
kubensenter 스크립트는 마운트 캡슐화 기능 상태를 알고 있으며 캡슐화가 활성화되지 않은 경우에도 실행하는 것이 안전합니다. 이 경우 스크립트는 기본 마운트 네임스페이스에서 제공된 명령을 실행합니다.
예를 들어 systemd 서비스를 새 Kubernetes 마운트 네임스페이스 내에서 실행해야 하는 경우 서비스 파일을 편집하고 kubensenter 와 함께 ExecStart= 명령줄을 사용합니다.
[Unit] Description=Example service [Service] ExecStart=/usr/bin/kubensenter /path/to/original/command arg1 arg2
7.4.5. 추가 리소스
8장. 베어 메탈 호스트 관리
베어 메탈 클러스터에 OpenShift Container Platform을 설치할 때 클러스터에 있는 베어 메탈 호스트에 대한 machine 및 machineset CR(사용자 정의 리소스)을 사용하여 베어 메탈 노드를 프로비저닝하고 관리할 수 있습니다.
8.1. 베어 메탈 호스트 및 노드 정보
RHCOS(Red Hat Enterprise Linux CoreOS) 베어 메탈 호스트를 클러스터에서 노드로 프로비저닝하려면 먼저 베어 메탈 호스트 하드웨어에 해당하는 MachineSet CR(사용자 정의 리소스) 오브젝트를 생성합니다. 베어 메탈 호스트 컴퓨팅 머신 세트는 구성과 관련된 인프라 구성 요소를 설명합니다. 이러한 컴퓨팅 머신 세트에 특정 Kubernetes 레이블을 적용한 다음 해당 머신에서만 실행되도록 인프라 구성 요소를 업데이트합니다.
machine CR은 metal3.io/autoscale-to-hosts 주석이 포함된 관련 MachineSet을 확장하면 자동으로 생성됩니다. OpenShift Container Platform은 Machine CR을 사용하여 MachineSet CR에 지정된 대로 호스트에 해당하는 베어 메탈 노드를 프로비저닝합니다.
8.2. 베어 메탈 호스트 유지관리
OpenShift Container Platform 웹 콘솔에서 클러스터의 베어 메탈 호스트의 세부 정보를 유지 관리할 수 있습니다. 컴퓨팅 → 베어 메탈 호스트로 이동하여 작업 드롭다운 메뉴에서 작업을 선택합니다. 여기에서 BMC 세부 정보, 호스트의 MAC 주소 부팅, 전원 관리 활성화 등의 항목을 관리할 수 있습니다. 네트워크 인터페이스의 세부 정보와 호스트에 대한 드라이브도 검토할 수 있습니다.
베어 메탈 호스트를 유지 관리 모드로 이동할 수 있습니다. 호스트를 유지 관리 모드로 이동할 때 스케줄러는 모든 관리 워크로드를 해당 베어 메탈 노드에서 이동합니다. 유지 관리 모드에서는 새 워크로드가 예약되지 않습니다.
웹 콘솔에서 베어 메탈 호스트를 프로비저닝 해제할 수 있습니다. 호스트 프로비저닝 해제는 다음 작업을 수행합니다.
-
cluster.k8s.io/delete-machine: true를 사용하여 베어 메탈 호스트 CR에 주석을 답니다. - 관련 컴퓨팅 머신 세트를 축소
먼저 데몬 세트와 관리되지 않는 정적 Pod를 다른 노드로 이동하지 않고 호스트의 전원을 끄면 서비스가 중단되고 데이터가 손실될 수 있습니다.
추가 리소스
8.2.1. 웹 콘솔을 사용하여 클러스터에 베어 메탈 호스트 추가
웹 콘솔의 클러스터에 베어 메탈 호스트를 추가할 수 있습니다.
사전 요구 사항
- 베어 메탈에 RHCOS 클러스터 설치
-
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
- 웹 콘솔에서 Compute → Bare Metal Hosts로 이동합니다.
- Add Host → New with Dialog를 선택합니다.
- 새 베어 메탈 호스트의 고유 이름을 지정합니다.
- Boot MAC address를 설정합니다.
- Baseboard Management Console (BMC) Address를 설정합니다.
- 호스트의 BMC(Baseboard Management Controller)에 대한 사용자 인증 정보를 입력합니다.
- 생성 후 호스트 전원을 켜도록선택하고 Create를 선택합니다.
- 사용 가능한 베어 메탈 호스트 수와 일치하도록 복제본 수를 확장합니다. Compute → MachineSets로 이동하고 Actions 드롭다운 메뉴에서 Edit Machine count을 선택하여 클러스터에서 머신 복제본 수를 늘립니다.
oc scale 명령 및 적절한 베어 메탈 컴퓨팅 머신 세트를 사용하여 베어 메탈 노드 수를 관리할 수도 있습니다.
8.2.2. 웹 콘솔에서 YAML을 사용하여 클러스터에 베어 메탈 호스트 추가
베어 메탈 호스트를 설명하는 YAML 파일을 사용하여 웹 콘솔의 클러스터에 베어 메탈 호스트를 추가할 수 있습니다.
사전 요구 사항
- 클러스터에 사용할 RHCOS 컴퓨팅 머신을 베어메탈 인프라에 설치합니다.
-
cluster-admin권한이 있는 사용자로 로그인합니다. -
베어 메탈 호스트의
SecretCR을 생성합니다.
프로세스
- 웹 콘솔에서 Compute → Bare Metal Hosts로 이동합니다.
- Add Host → New from YAML을 선택합니다.
아래 YAML을 복사하고 붙여넣고 호스트의 세부 정보로 관련 필드를 수정합니다.
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <bare_metal_host_name> spec: online: true bmc: address: <bmc_address> credentialsName: <secret_credentials_name> 1 disableCertificateVerification: True 2 bootMACAddress: <host_boot_mac_address>- Create를 선택하여 YAML을 저장하고 새 베어 메탈 호스트를 생성합니다.
사용 가능한 베어 메탈 호스트 수와 일치하도록 복제본 수를 확장합니다. Compute → MachineSets로 이동하고 Actions 드롭다운 메뉴에서 Edit Machine count를 선택하여 클러스터의 머신 수를 늘립니다.
참고oc scale명령 및 적절한 베어 메탈 컴퓨팅 머신 세트를 사용하여 베어 메탈 노드 수를 관리할 수도 있습니다.
8.2.3. 사용 가능한 베어 메탈 호스트 수로 머신 자동 스케일링
사용 가능한 BareMetalHost 오브젝트 수와 일치하는 Machine 오브젝트 수를 자동으로 생성하려면 MachineSet 오브젝트에 metal3.io/autoscale-to-hosts 주석을 추가합니다.
사전 요구 사항
-
클러스터에서 사용할 RHCOS 베어 메탈 컴퓨팅 머신을 설치하고 해당
BareMetalHost오브젝트를 생성합니다. -
OpenShift Container Platform CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
metal3.io/autoscale-to-hosts주석을 추가하여 자동 스케일링을 구성할 컴퓨팅 머신 세트에 주석을 답니다. <machineset>를 컴퓨팅 머신 세트의 이름으로 바꿉니다.$ oc annotate machineset <machineset> -n openshift-machine-api 'metal3.io/autoscale-to-hosts=<any_value>'
새로 확장된 머신이 시작될 때까지 기다립니다.
BareMetalHost 오브젝트를 사용하여 클러스터에 머신을 생성하고 레이블 또는 선택기가 BareMetalHost에서 변경되면 Machine 오브젝트가 생성된 MachineSet에 대해 BareMetalHost 오브젝트가 계속 계산됩니다.
8.2.4. 프로비저너 노드에서 베어 메탈 호스트 제거
특정 상황에서는 프로비저너 노드에서 베어 메탈 호스트를 일시적으로 제거해야 할 수 있습니다. 예를 들어 OpenShift Container Platform 관리 콘솔을 사용하거나 Machine Config Pool 업데이트로 베어 메탈 호스트 재부팅이 트리거되는 경우 OpenShift Container Platform은 통합된 iDrac(Remote Access Controller)에 로그인하여 작업 대기열 삭제를 발행합니다.
사용 가능한 BareMetalHost 오브젝트 수와 일치하는 Machine 오브젝트 수를 관리하지 않으려면 MachineSet 오브젝트에 baremetalhost.metal3.io/detached 주석을 추가합니다.
이 주석은 Provisioned,ExternallyProvisioned 또는 Ready/Available 상태에 있는 BareMetalHost 오브젝트에만 적용됩니다.
사전 요구 사항
-
클러스터에서 사용할 RHCOS 베어 메탈 컴퓨팅 머신을 설치하고 해당
BareMetalHost오브젝트를 생성합니다. -
OpenShift Container Platform CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
baremetalhost.metal3.io/detached주석을 추가하여 프로비저너 노드에서 제거할 컴퓨팅 머신 세트에 주석을 답니다.$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached'
새 머신이 시작될 때까지 기다립니다.
참고BareMetalHost오브젝트를 사용하여 클러스터에 머신을 생성하고 레이블 또는 선택기가BareMetalHost에서 변경되면Machine오브젝트가 생성된MachineSet에 대해BareMetalHost오브젝트가 계속 계산됩니다.프로비저닝 사용 사례에서 다음 명령을 사용하여 재부팅이 완료된 후 주석을 제거합니다.
$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached-'
9장. 베어 메탈 이벤트 릴레이를 사용하여 베어 메탈 이벤트 모니터링
Bare Metal Event Relay는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
9.1. 베어 메탈 이벤트 정보
Bare Metal Event Relay Operator는 더 이상 사용되지 않습니다. Bare Metal Event Relay Operator를 사용하여 베어 메탈 호스트를 모니터링하는 기능은 향후 OpenShift Container Platform 릴리스에서 제거됩니다.
Bare Metal Event Relay를 사용하여 OpenShift Container Platform 클러스터에서 실행되는 애플리케이션을 기본 베어 메탈 호스트에서 생성된 이벤트에 서브스크립션합니다. Redfish 서비스는 노드에 이벤트를 게시하고 고급 메시지 큐에 서브스크립션된 애플리케이션으로 전송합니다.
베어 메탈 이벤트는 DCTF(Distributed Management Task Force)의 지침에 따라 개발된 오픈 Redfish 표준을 기반으로 합니다. Redfish는 REST API를 사용하여 보안 업계 표준 프로토콜을 제공합니다. 이 프로토콜은 분산, 컨버지드 또는 소프트웨어 정의 리소스 및 인프라를 관리하는 데 사용됩니다.
Redfish를 통해 게시된 하드웨어 관련 이벤트는 다음과 같습니다.
- 온도 제한 위반
- 서버 상태
- 팬 상태
Bare Metal Event Relay Operator를 배포하여 베어 메탈 이벤트 사용을 시작하고 애플리케이션에 서비스에 가입하십시오. Bare Metal Event Relay Operator는 Redfish 베어 메탈 이벤트 서비스의 라이프사이클을 설치하고 관리합니다.
베어 메탈 이벤트 릴레이는 베어 메탈 인프라에서 프로비저닝된 단일 노드 클러스터에서 Redfish 가능 장치에서만 작동합니다.
9.2. 베어 메탈 이벤트 작동 방식
Bare Metal Event Relay를 사용하면 베어 메탈 클러스터에서 실행되는 애플리케이션이 Redfish 하드웨어 변경 및 온도 임계값 위반, 디스크 손실, 정전 및 메모리 실패와 같은 Redfish 하드웨어 변경 및 장애에 빠르게 대응할 수 있습니다. 이러한 하드웨어 이벤트는 HTTP 전송 또는 AMQP 메커니즘을 사용하여 전달됩니다. 메시징 서비스의 대기 시간은 10~20밀리초입니다.
베어 메탈 이벤트 릴레이는 하드웨어 이벤트에 대한 게시-서브스크립션 서비스를 제공합니다. 애플리케이션은 REST API를 사용하여 이벤트를 구독할 수 있습니다. 베어 메탈 이벤트 릴레이는 Redfish OpenAPI v1.8 이상을 준수하는 하드웨어를 지원합니다.
9.2.1. 베어 메탈 이벤트 릴레이 데이터 흐름
다음 그림은 베어 메탈 이벤트 데이터 흐름의 예를 보여줍니다.
그림 9.1. 베어 메탈 이벤트 릴레이 데이터 흐름
9.2.1.1. Operator에서 관리하는 Pod
Operator는 사용자 정의 리소스를 사용하여 HardwareEvent CR을 사용하여 Bare Metal Event Relay 및 해당 구성 요소가 포함된 Pod를 관리합니다.
9.2.1.2. Bare Metal Event Relay
시작 시 베어 메탈 이벤트 릴레이는 Redfish API를 쿼리하고 사용자 지정 레지스트리를 포함한 모든 메시지 레지스트리를 다운로드합니다. 그런 다음 Bare Metal Event Relay가 Redfish 하드웨어에서 서브스크립션 이벤트를 수신하기 시작합니다.
Bare Metal Event Relay를 사용하면 베어 메탈 클러스터에서 실행되는 애플리케이션이 Redfish 하드웨어 변경 및 온도 임계값 위반, 디스크 손실, 정전 및 메모리 실패와 같은 Redfish 하드웨어 변경 및 장애에 빠르게 대응할 수 있습니다. 이벤트는 HardwareEvent CR을 사용하여 보고합니다.
9.2.1.3. 클라우드 네이티브 이벤트
CCNE(클라우드 네이티브 이벤트)는 이벤트 데이터 형식을 정의하기 위한 REST API 사양입니다.
9.2.1.4. CNCF CloudEvents
CloudEvents 는 이벤트 데이터 형식을 정의하기 위해 CCNCF(Cloud Native Computing Foundation)에서 개발한 벤더 중립 사양입니다.
9.2.1.5. HTTP 전송 또는 AMQP 디스패치 라우터
HTTP 전송 또는 AMQP 디스패치 라우터는 게시자와 구독자 간의 메시지 전달 서비스를 담당합니다.
HTTP 전송은 PTP 및 베어 메탈 이벤트의 기본 전송입니다. 가능한 경우 PTP 및 베어 메탈 이벤트에 AMQP 대신 HTTP 전송을 사용합니다. AMQ Interconnect는 2024년 6월 30일부터 EOL입니다. AMQ Interconnect의 ELS(Extended Life Cycle Support)는 2029년 11월 29일에 종료됩니다. 자세한 내용은 Red Hat AMQ Interconnect 지원 상태를 참조하십시오.
9.2.1.6. 클라우드 이벤트 프록시 사이드카
클라우드 이벤트 프록시 사이드카 컨테이너 이미지는 O-RAN API 사양을 기반으로 하며 하드웨어 이벤트에 대한 게시-구독 이벤트 프레임워크를 제공합니다.
9.2.2. Redfish 메시지 구문 분석 서비스
Redfish 이벤트를 처리하는 것 외에도 Bare Metal Event Relay는 Message 속성 없이 이벤트에 대한 메시지 구문 분석 기능을 제공합니다. 프록시는 시작될 때 하드웨어에서 벤더별 레지스트리를 포함하여 모든 Redfish 메시지 레지스트리를 다운로드합니다. 이벤트에 Message 속성이 포함되어 있지 않은 경우 프록시는 Redfish 메시지 레지스트리를 사용하여 Message 및 Resolution 속성을 구성하고 이벤트를 클라우드 이벤트 프레임워크에 전달하기 전에 이벤트에 추가합니다. 이 서비스를 사용하면 Redfish 이벤트의 메시지 크기와 전송 대기 시간이 단축될 수 있습니다.
9.2.3. CLI를 사용하여 베어 메탈 이벤트 릴레이 설치
클러스터 관리자는 CLI를 사용하여 Bare Metal Event Relay Operator를 설치할 수 있습니다.
사전 요구 사항
- BMC(RedFish-enabled Baseboard Management Controller)가 있는 노드를 사용하여 베어 메탈 하드웨어에 설치된 클러스터입니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
베어 메탈 이벤트 릴레이의 네임스페이스를 생성합니다.
다음 YAML을
베어 메탈-events-namespace.yaml파일에 저장합니다.apiVersion: v1 kind: Namespace metadata: name: openshift-bare-metal-events labels: name: openshift-bare-metal-events openshift.io/cluster-monitoring: "true"NamespaceCR을 생성합니다.$ oc create -f bare-metal-events-namespace.yaml
Bare Metal Event Relay Operator에 대한 Operator 그룹을 생성합니다.
다음 YAML을
bare-metal-events-operatorgroup.yaml파일에 저장합니다.apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: bare-metal-event-relay-group namespace: openshift-bare-metal-events spec: targetNamespaces: - openshift-bare-metal-events
OperatorGroupCR을 생성합니다.$ oc create -f bare-metal-events-operatorgroup.yaml
베어 메탈 이벤트 릴레이를 구독합니다.
다음 YAML을
bare-metal-events-sub.yaml파일에 저장합니다.apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: bare-metal-event-relay-subscription namespace: openshift-bare-metal-events spec: channel: "stable" name: bare-metal-event-relay source: redhat-operators sourceNamespace: openshift-marketplace
SubscriptionCR을 생성합니다.$ oc create -f bare-metal-events-sub.yaml
검증
Bare Metal Event Relay Operator가 설치되었는지 확인하려면 다음 명령을 실행합니다.
$ oc get csv -n openshift-bare-metal-events -o custom-columns=Name:.metadata.name,Phase:.status.phase
9.2.4. 웹 콘솔을 사용하여 베어 메탈 이벤트 릴레이 설치
클러스터 관리자는 웹 콘솔을 사용하여 Bare Metal Event Relay Operator를 설치할 수 있습니다.
사전 요구 사항
- BMC(RedFish-enabled Baseboard Management Controller)가 있는 노드를 사용하여 베어 메탈 하드웨어에 설치된 클러스터입니다.
-
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
OpenShift Container Platform 웹 콘솔을 사용하여 Bare Metal Event Relay를 설치합니다.
- OpenShift Container Platform 웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
- 사용 가능한 Operator 목록에서 Bare Metal Event Relay 를 선택한 다음 설치를 클릭합니다.
- Operator 설치 페이지에서 네임스페이스 를 선택하거나 생성한 후 openshift-bare-metal-events 를 선택한 다음 설치를 클릭합니다.
검증
선택 사항: 다음 검사를 수행하여 Operator가 성공적으로 설치되었는지 확인할 수 있습니다.
- Operator → 설치된 Operator 페이지로 전환합니다.
InstallSucceeded 상태로 프로젝트에 Bare Metal Event Relay 가 나열되어 있는지 확인합니다.
참고설치 중에 Operator는 실패 상태를 표시할 수 있습니다. 나중에 InstallSucceeded 메시지와 함께 설치에 성공하면 이 실패 메시지를 무시할 수 있습니다.
Operator가 설치된 것으로 나타나지 않으면 다음과 같이 추가 문제 해결을 수행합니다.
- Operator → 설치된 Operator 페이지로 이동하고 Operator 서브스크립션 및 설치 계획 탭의 상태에 장애나 오류가 있는지 검사합니다.
- 워크로드 → Pod 페이지로 이동하여 프로젝트 네임스페이스에서 Pod 로그를 확인합니다.
9.3. AMQ 메시징 버스 설치
노드에서 게시자와 구독자 간에 Redfish 베어 메탈 이벤트 알림을 전달하려면 노드에서 로컬로 실행되도록 AMQ 메시징 버스를 설치하고 구성할 수 있습니다. 클러스터에서 사용할 AMQ Interconnect Operator를 설치하여 이 작업을 수행합니다.
HTTP 전송은 PTP 및 베어 메탈 이벤트의 기본 전송입니다. 가능한 경우 PTP 및 베어 메탈 이벤트에 AMQP 대신 HTTP 전송을 사용합니다. AMQ Interconnect는 2024년 6월 30일부터 EOL입니다. AMQ Interconnect의 ELS(Extended Life Cycle Support)는 2029년 11월 29일에 종료됩니다. 자세한 내용은 Red Hat AMQ Interconnect 지원 상태를 참조하십시오.
사전 요구 사항
-
OpenShift Container Platform CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
-
AMQ Interconnect Operator를 자체
amq-interconnect네임스페이스에 설치합니다. AMQ Interconnect Operator 설치를 참조하십시오.
검증
AMQ Interconnect Operator를 사용할 수 있고 필요한 Pod가 실행 중인지 확인합니다.
$ oc get pods -n amq-interconnect
출력 예
NAME READY STATUS RESTARTS AGE amq-interconnect-645db76c76-k8ghs 1/1 Running 0 23h interconnect-operator-5cb5fc7cc-4v7qm 1/1 Running 0 23h
필요한
bare-metal-event-relay베어 메탈 이벤트 생산자 Pod가openshift-bare-metal-events네임스페이스에서 실행 중인지 확인합니다.$ oc get pods -n openshift-bare-metal-events
출력 예
NAME READY STATUS RESTARTS AGE hw-event-proxy-operator-controller-manager-74d5649b7c-dzgtl 2/2 Running 0 25s
9.4. 클러스터 노드의 Redfish BMC 베어 메탈 이벤트 구독
노드의 BMCEventSubscription CR(사용자 정의 리소스)을 생성하고 이벤트에 대한 HardwareEvent CR을 생성하고 BMC에 대한 Secret CR을 생성하여 클러스터의 노드에서 생성된 Redfish BMC 이벤트를 구독할 수 있습니다.
9.4.1. 베어 메탈 이벤트 구독
BMC(Baseboard Management Controller)를 구성하여 OpenShift Container Platform 클러스터에서 실행되는 서브스크립션 애플리케이션에 베어 메탈 이벤트를 보낼 수 있습니다. Redfish 베어 메탈 이벤트의 예로는 장치 온도 증가 또는 장치 제거가 포함됩니다. REST API를 사용하여 애플리케이션을 베어 메탈 이벤트에 서브스크립션합니다.
Redfish를 지원하고 벤더 인터페이스가 redfish 또는 idrac-redfish 로 설정된 물리적 하드웨어에 대한 BMCEventSubscription CR(사용자 정의 리소스)만 생성할 수 있습니다.
BMCEventSubscription CR을 사용하여 사전 정의된 Redfish 이벤트를 구독합니다. Redfish 표준에서는 특정 경고 및 임계값을 생성할 수 있는 옵션을 제공하지 않습니다. 예를 들어 인클로저의 온도가 40>-< Celsius를 초과하는 경우 경고 이벤트를 수신하려면 공급 업체의 권장 사항에 따라 이벤트를 수동으로 구성해야 합니다.
BMCEventSubscription CR을 사용하여 노드의 베어 메탈 이벤트를 구독하려면 다음 절차를 수행합니다.
사전 요구 사항
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - BMC의 사용자 이름과 암호를 가져옵니다.
클러스터에 Redfish 지원 BMC(Baseboard Management Controller)를 사용하여 베어 메탈 노드를 배포하고 BMC에서 Redfish 이벤트를 활성화합니다.
참고특정 하드웨어에서 Redfish 이벤트를 활성화하는 것은 이 정보의 범위를 벗어납니다. 특정 하드웨어에 대한 Redfish 이벤트 활성화에 대한 자세한 내용은 BMC 제조업체 설명서를 참조하십시오.
프로세스
다음
curl명령을 실행하여 노드 하드웨어에 RedfishEventService가 활성화되어 있는지 확인합니다.$ curl https://<bmc_ip_address>/redfish/v1/EventService --insecure -H 'Content-Type: application/json' -u "<bmc_username>:<password>"
다음과 같습니다.
- bmc_ip_address
- Redfish 이벤트가 생성되는 BMC의 IP 주소입니다.
출력 예
{ "@odata.context": "/redfish/v1/$metadata#EventService.EventService", "@odata.id": "/redfish/v1/EventService", "@odata.type": "#EventService.v1_0_2.EventService", "Actions": { "#EventService.SubmitTestEvent": { "EventType@Redfish.AllowableValues": ["StatusChange", "ResourceUpdated", "ResourceAdded", "ResourceRemoved", "Alert"], "target": "/redfish/v1/EventService/Actions/EventService.SubmitTestEvent" } }, "DeliveryRetryAttempts": 3, "DeliveryRetryIntervalSeconds": 30, "Description": "Event Service represents the properties for the service", "EventTypesForSubscription": ["StatusChange", "ResourceUpdated", "ResourceAdded", "ResourceRemoved", "Alert"], "EventTypesForSubscription@odata.count": 5, "Id": "EventService", "Name": "Event Service", "ServiceEnabled": true, "Status": { "Health": "OK", "HealthRollup": "OK", "State": "Enabled" }, "Subscriptions": { "@odata.id": "/redfish/v1/EventService/Subscriptions" } }다음 명령을 실행하여 클러스터의 Bare Metal Event Relay 서비스 경로를 가져옵니다.
$ oc get route -n openshift-bare-metal-events
출력 예
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hw-event-proxy hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com hw-event-proxy-service 9087 edge None
BMCEventSubscription리소스를 생성하여 Redfish 이벤트를 구독합니다.다음 YAML을
bmc_sub.yaml파일에 저장합니다.apiVersion: metal3.io/v1alpha1 kind: BMCEventSubscription metadata: name: sub-01 namespace: openshift-machine-api spec: hostName: <hostname> 1 destination: <proxy_service_url> 2 context: ''
- 1
- Redfish 이벤트가 생성되는 작업자 노드의 이름 또는 UUID를 지정합니다.
- 2
- 베어 메탈 이벤트 프록시 서비스를 지정합니다(예:
https://hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com/webhook).
BMCEventSubscriptionCR을 생성합니다.$ oc create -f bmc_sub.yaml
선택 사항: BMC 이벤트 서브스크립션을 삭제하려면 다음 명령을 실행합니다.
$ oc delete -f bmc_sub.yaml
선택 사항:
BMCEventSubscriptionCR을 생성하지 않고 Redfish 이벤트 서브스크립션을 수동으로 생성하려면 BMC 사용자 이름과 암호를 지정하여 다음curl명령을 실행합니다.$ curl -i -k -X POST -H "Content-Type: application/json" -d '{"Destination": "https://<proxy_service_url>", "Protocol" : "Redfish", "EventTypes": ["Alert"], "Context": "root"}' -u <bmc_username>:<password> 'https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions' –v다음과 같습니다.
- proxy_service_url
-
베어 메탈 이벤트 프록시 서비스(예:
https://hw-event-proxy-openshift-bare-metal-events.apps.compute-1.example.com/webhook)입니다.
- bmc_ip_address
- Redfish 이벤트가 생성되는 BMC의 IP 주소입니다.
출력 예
HTTP/1.1 201 Created Server: AMI MegaRAC Redfish Service Location: /redfish/v1/EventService/Subscriptions/1 Allow: GET, POST Access-Control-Allow-Origin: * Access-Control-Expose-Headers: X-Auth-Token Access-Control-Allow-Headers: X-Auth-Token Access-Control-Allow-Credentials: true Cache-Control: no-cache, must-revalidate Link: <http://redfish.dmtf.org/schemas/v1/EventDestination.v1_6_0.json>; rel=describedby Link: <http://redfish.dmtf.org/schemas/v1/EventDestination.v1_6_0.json> Link: </redfish/v1/EventService/Subscriptions>; path= ETag: "1651135676" Content-Type: application/json; charset=UTF-8 OData-Version: 4.0 Content-Length: 614 Date: Thu, 28 Apr 2022 08:47:57 GMT
9.4.2. curl을 사용하여 Redfish 베어 메탈 이벤트 서브스크립션 쿼리
일부 하드웨어 벤더는 Redfish 하드웨어 이벤트 서브스크립션의 양을 제한합니다. curl 을 사용하여 Redfish 이벤트 서브스크립션 수를 쿼리할 수 있습니다.
사전 요구 사항
- BMC의 사용자 이름과 암호를 가져옵니다.
- 클러스터에 Redfish 사용 BMC(Baseboard Management Controller)를 사용하여 베어 메탈 노드를 배포하고 BMC에서 Redfish 하드웨어 이벤트를 활성화합니다.
프로세스
다음
curl명령을 실행하여 BMC의 현재 서브스크립션을 확인합니다.$ curl --globoff -H "Content-Type: application/json" -k -X GET --user <bmc_username>:<password> https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions
다음과 같습니다.
- bmc_ip_address
- Redfish 이벤트가 생성되는 BMC의 IP 주소입니다.
출력 예
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 435 100 435 0 0 399 0 0:00:01 0:00:01 --:--:-- 399 { "@odata.context": "/redfish/v1/$metadata#EventDestinationCollection.EventDestinationCollection", "@odata.etag": "" 1651137375 "", "@odata.id": "/redfish/v1/EventService/Subscriptions", "@odata.type": "#EventDestinationCollection.EventDestinationCollection", "Description": "Collection for Event Subscriptions", "Members": [ { "@odata.id": "/redfish/v1/EventService/Subscriptions/1" }], "Members@odata.count": 1, "Name": "Event Subscriptions Collection" }이 예에서 단일 서브스크립션이
/redfish/v1/EventService/Subscriptions/1로 구성되어 있습니다.선택 사항:
curl을 사용하여/redfish/v1/EventService/Subscriptions/1서브스크립션을 제거하려면 BMC 사용자 이름과 암호를 지정하여 다음 명령을 실행합니다.$ curl --globoff -L -w "%{http_code} %{url_effective}\n" -k -u <bmc_username>:<password >-H "Content-Type: application/json" -d '{}' -X DELETE https://<bmc_ip_address>/redfish/v1/EventService/Subscriptions/1다음과 같습니다.
- bmc_ip_address
- Redfish 이벤트가 생성되는 BMC의 IP 주소입니다.
9.4.3. 베어 메탈 이벤트 및 Secret CR 생성
베어 메탈 이벤트 사용을 시작하려면 Redfish 하드웨어가 있는 호스트에 대한 HardwareEvent CR(사용자 정의 리소스)을 생성합니다. 하드웨어 이벤트 및 오류는 hw-event-proxy 로그에 보고됩니다.
사전 요구 사항
-
OpenShift Container Platform CLI(
oc)를 설치했습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다. - 베어 메탈 이벤트 릴레이를 설치했습니다.
-
BMC Redfish 하드웨어에 대한
BMCEventSubscriptionCR을 생성했습니다.
프로세스
HardwareEventCR(사용자 정의 리소스)을 생성합니다.참고여러
HardwareEvent리소스가 허용되지 않습니다.다음 YAML을
hw-event.yaml파일에 저장합니다.apiVersion: "event.redhat-cne.org/v1alpha1" kind: "HardwareEvent" metadata: name: "hardware-event" spec: nodeSelector: node-role.kubernetes.io/hw-event: "" 1 logLevel: "debug" 2 msgParserTimeout: "10" 3- 1
- 필수 항목입니다.
nodeSelector필드를 사용하여 지정된 레이블이 있는 노드를 대상으로 지정합니다(예:node-role.kubernetes.io/hw-event: "").참고OpenShift Container Platform 4.13 이상에서는 베어 메탈 이벤트에 HTTP 전송을 사용할 때
HardwareEvent리소스에서spec.transportHost필드를 설정할 필요가 없습니다. 베어 메탈 이벤트에 AMQP 전송을 사용하는 경우에만transportHost를 설정합니다. - 2
- 선택 사항: 기본값은
debug입니다.hw-event-proxy로그에서 로그 수준을 설정합니다. 다음과 같은 로그 수준을 사용할 수 있습니다.fatal,error,warning,info,debug,trace. - 3
- 선택 사항: Message Parser의 시간 초과 값을 밀리초로 설정합니다. 메시지 구문 분석 요청이 시간 초과 내에 응답하지 않으면 원래 하드웨어 이벤트 메시지가 클라우드 네이티브 이벤트 프레임워크에 전달됩니다. 기본값은 10입니다.
클러스터에
HardwareEventCR을 적용합니다.$ oc create -f hardware-event.yaml
하드웨어 이벤트 프록시가 베어 메탈 호스트의 Redfish 메시지 레지스트리에 액세스할 수 있는 BMC 사용자 이름 및 암호
SecretCR을 생성합니다.hw-event-bmc-secret.yaml파일에 다음 YAML을 저장합니다.apiVersion: v1 kind: Secret metadata: name: redfish-basic-auth type: Opaque stringData: 1 username: <bmc_username> password: <bmc_password> # BMC host DNS or IP address hostaddr: <bmc_host_ip_address>- 1
stringData아래에 다양한 항목의 일반 텍스트 값을 입력합니다.
SecretCR을 생성합니다.$ oc create -f hw-event-bmc-secret.yaml
추가 리소스
9.5. 베어 메탈 이벤트 REST API 참조에 애플리케이션 구독
베어 메탈 이벤트 REST API를 사용하여 애플리케이션을 상위 노드에서 생성된 베어 메탈 이벤트에 등록합니다.
리소스 주소 /cluster/node/<node_name>/redfish/event 를 사용하여 애플리케이션을 Redfish 이벤트에 구독합니다. 여기서 < node_name >은 애플리케이션을 실행하는 클러스터 노드입니다.
별도의 애플리케이션 Pod에 cloud-event-consumer 애플리케이션 컨테이너 및 cloud-event-proxy 사이드카 컨테이너를 배포합니다. cloud-event-consumer 애플리케이션은 애플리케이션 Pod의 cloud-event-proxy 컨테이너를 서브스크립션합니다.
다음 API 끝점을 사용하여 애플리케이션 Pod의 http://localhost:8089/api/ocloudNotifications/v1/ 에서 cloud-event-consumer 컨테이너에서 게시한 Redfish 이벤트에 cloud-event- consumer 애플리케이션을 서브스크립션합니다.
/api/ocloudNotifications/v1/subscriptions-
POST: 새 서브스크립션을 생성합니다. -
GET: 서브스크립션 목록 검색합니다.
-
/api/ocloudNotifications/v1/subscriptions/<subscription_id>-
PUT: 지정된 서브스크립션 ID에 대한 새 상태 ping 요청을 생성합니다.
-
/api/ocloudNotifications/v1/health-
GET:ocloudNotificationsAPI의 상태를 반환합니다.
-
9089 는 애플리케이션 Pod에 배포된 cloud-event-consumer 컨테이너의 기본 포트입니다. 필요에 따라 애플리케이션에 대해 다른 포트를 구성할 수 있습니다.
api/ocloudNotifications/v1/subscriptions
HTTP 방법
GET api/ocloudNotifications/v1/subscriptions
설명
서브스크립션 목록을 반환합니다. 서브스크립션이 존재하는 경우 200 OK 상태 코드가 서브스크립션 목록과 함께 반환됩니다.
API 응답 예
[
{
"id": "ca11ab76-86f9-428c-8d3a-666c24e34d32",
"endpointUri": "http://localhost:9089/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions/ca11ab76-86f9-428c-8d3a-666c24e34d32",
"resource": "/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}
]
HTTP 방법
POST api/ocloudNotifications/v1/subscriptions
설명
새 서브스크립션을 생성합니다. 서브스크립션이 성공적으로 생성되었거나 이미 존재하는 경우 201 Created 상태 코드가 반환됩니다.
표 9.1. 쿼리 매개변수
| 매개변수 | 유형 |
|---|---|
| subscription | data |
페이로드 예
{
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions",
"resource": "/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}
api/ocloudNotifications/v1/subscriptions/<subscription_id>
HTTP 방법
GET api/ocloudNotifications/v1/subscriptions/<subscription_id>
설명
ID <subscription _id>가 있는 서브스크립션 세부 정보를 반환합니다.
표 9.2. 쿼리 매개변수
| 매개변수 | 유형 |
|---|---|
|
| string |
API 응답 예
{
"id":"ca11ab76-86f9-428c-8d3a-666c24e34d32",
"endpointUri":"http://localhost:9089/api/ocloudNotifications/v1/dummy",
"uriLocation":"http://localhost:8089/api/ocloudNotifications/v1/subscriptions/ca11ab76-86f9-428c-8d3a-666c24e34d32",
"resource":"/cluster/node/openshift-worker-0.openshift.example.com/redfish/event"
}
api/ocloudNotifications/v1/health/
HTTP 방법
GET api/ocloudNotifications/v1/health/
설명
ocloudNotifications REST API의 상태를 반환합니다.
API 응답 예
OK
9.6. PTP 또는 베어 메탈 이벤트에 HTTP 전송을 사용하도록 소비자 애플리케이션 마이그레이션
이전에 PTP 또는 베어 메탈 이벤트 소비자 애플리케이션을 배포한 경우 HTTP 메시지 전송을 사용하도록 애플리케이션을 업데이트해야 합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다. - PTP Operator 또는 Bare Metal Event Relay를 기본적으로 HTTP 전송을 사용하는 버전 4.13 이상으로 업데이트했습니다.
프로세스
HTTP 전송을 사용하도록 이벤트 소비자 애플리케이션을 업데이트합니다. 클라우드 이벤트 사이드카 배포에 대한
http-event-publishers변수를 설정합니다.예를 들어 PTP 이벤트가 구성된 클러스터에서 다음 YAML 스니펫에서는 클라우드 이벤트 사이드카 배포를 보여줍니다.
containers: - name: cloud-event-sidecar image: cloud-event-sidecar args: - "--metrics-addr=127.0.0.1:9091" - "--store-path=/store" - "--transport-host=consumer-events-subscription-service.cloud-events.svc.cluster.local:9043" - "--http-event-publishers=ptp-event-publisher-service-NODE_NAME.openshift-ptp.svc.cluster.local:9043" 1 - "--api-port=8089"- 1
- PTP Operator는
NODE_NAME을 PTP 이벤트를 생성하는 호스트로 자동으로 해결합니다. 예를 들면compute-1.example.com입니다.
베어 메탈 이벤트가 구성된 클러스터에서 클라우드 이벤트 사이드카 배포 CR에서
http-event-publishers필드를hw-event-publisher-service.openshift-bare-metal-events.svc.cluster.local:9043으로 설정합니다.이벤트 소비자 애플리케이션과 함께
consumer-events-subscription-service서비스를 배포합니다. 예를 들면 다음과 같습니다.apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: "true" service.alpha.openshift.io/serving-cert-secret-name: sidecar-consumer-secret name: consumer-events-subscription-service namespace: cloud-events labels: app: consumer-service spec: ports: - name: sub-port port: 9043 selector: app: consumer clusterIP: None sessionAffinity: None type: ClusterIP
10장. 대규모 페이지의 기능과 애플리케이션에서 대규모 페이지를 사용하는 방법
10.1. 대규모 페이지의 기능
메모리는 페이지라는 블록으로 관리됩니다. 대부분의 시스템에서 한 페이지는 4Ki입니다. 1Mi 메모리는 256페이지와 같고 1Gi 메모리는 256,000페이지에 해당합니다. CPU에는 하드웨어에서 이러한 페이지 목록을 관리하는 내장 메모리 관리 장치가 있습니다. TLB(Translation Lookaside Buffer)는 가상-물리적 페이지 매핑에 대한 소규모 하드웨어 캐시입니다. TLB에 하드웨어 명령어로 전달된 가상 주소가 있으면 매핑을 신속하게 확인할 수 있습니다. 가상 주소가 없으면 TLB 누락이 발생하고 시스템에서 소프트웨어 기반 주소 변환 속도가 느려져 성능 문제가 발생합니다. TLB 크기는 고정되어 있으므로 TLB 누락 가능성을 줄이는 유일한 방법은 페이지 크기를 늘리는 것입니다.
대규모 페이지는 4Ki보다 큰 메모리 페이지입니다. x86_64 아키텍처에서 일반적인 대규모 페이지 크기는 2Mi와 1Gi입니다. 다른 아키텍처에서는 크기가 달라집니다. 대규모 페이지를 사용하려면 애플리케이션이 인식할 수 있도록 코드를 작성해야 합니다. THP(투명한 대규모 페이지)에서는 애플리케이션 지식 없이 대규모 페이지 관리를 자동화하려고 하지만 한계가 있습니다. 특히 페이지 크기 2Mi로 제한됩니다. THP에서는 THP 조각 모음 작업으로 인해 메모리 사용률이 높아지거나 조각화가 발생하여 노드에서 성능이 저하될 수 있으며 이로 인해 메모리 페이지가 잠길 수 있습니다. 이러한 이유로 일부 애플리케이션은 THP 대신 사전 할당된 대규모 페이지를 사용하도록 설계(또는 권장)할 수 있습니다.
OpenShift Container Platform에서는 Pod의 애플리케이션이 사전 할당된 대규모 페이지를 할당하고 사용할 수 있습니다.
10.2. 앱에서 대규모 페이지를 사용하는 방법
노드에서 대규모 페이지 용량을 보고하려면 노드가 대규모 페이지를 사전 할당해야 합니다. 노드는 단일 크기의 대규모 페이지만 사전 할당할 수 있습니다.
대규모 페이지는 hugepages-<size> 리소스 이름으로 컨테이너 수준 리소스 요구사항에 따라 사용할 수 있습니다. 여기서 크기는 특정 노드에서 지원되는 정수 값이 사용된 가장 간단한 바이너리 표현입니다. 예를 들어 노드에서 2,048KiB 페이지 크기를 지원하는 경우 예약 가능한 리소스 hugepages-2Mi를 공개합니다. CPU 또는 메모리와 달리 대규모 페이지는 초과 커밋을 지원하지 않습니다.
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi 1
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
hugepages의 메모리 양은 할당할 정확한 양으로 지정하십시오. 이 값을hugepages의 메모리 양과 페이지 크기를 곱한 값으로 지정하지 마십시오. 예를 들어 대규모 페이지 크기가 2MB이고 애플리케이션에 100MB의 대규모 페이지 지원 RAM을 사용하려면 50개의 대규모 페이지를 할당합니다. OpenShift Container Platform에서 해당 계산을 처리합니다. 위의 예에서와 같이100MB를 직접 지정할 수 있습니다.
특정 크기의 대규모 페이지 할당
일부 플랫폼에서는 여러 대규모 페이지 크기를 지원합니다. 특정 크기의 대규모 페이지를 할당하려면 대규모 페이지 부팅 명령 매개변수 앞에 대규모 페이지 크기 선택 매개변수 hugepagesz=<size>를 지정합니다. <size> 값은 바이트 단위로 지정해야 하며 스케일링 접미사 [kKmMgG]를 선택적으로 사용할 수 있습니다. 기본 대규모 페이지 크기는 default_hugepagesz=<size> 부팅 매개변수로 정의할 수 있습니다.
대규모 페이지 요구사항
- 대규모 페이지 요청은 제한과 같아야 합니다. 제한은 지정되었으나 요청은 지정되지 않은 경우 제한이 기본값입니다.
- 대규모 페이지는 Pod 범위에서 격리됩니다. 컨테이너 격리는 향후 반복에서 계획됩니다.
-
대규모 페이지에서 지원하는
EmptyDir볼륨은 Pod 요청보다 더 많은 대규모 페이지 메모리를 사용하면 안 됩니다. -
SHM_HUGETLB로shmget()를 통해 대규모 페이지를 사용하는 애플리케이션은 proc/sys/vm/hugetlb_shm_group과 일치하는 보조 그룹을 사용하여 실행되어야 합니다.
10.3. Downward API를 사용하여 Huge Page 리소스 사용
Downward API를 사용하여 컨테이너에서 사용하는 Huge Page 리소스에 대한 정보를 삽입할 수 있습니다.
리소스 할당을 환경 변수, 볼륨 플러그인 또는 둘 다로 삽입할 수 있습니다. 컨테이너에서 개발하고 실행하는 애플리케이션은 지정된 볼륨에서의 환경 변수 또는 파일을 읽고 사용할 수 있는 리소스를 확인할 수 있습니다.
프로세스
다음 예와 유사한
hugepages-volume-pod.yaml파일을 생성합니다.apiVersion: v1 kind: Pod metadata: generateName: hugepages-volume- labels: app: hugepages-example spec: containers: - securityContext: capabilities: add: [ "IPC_LOCK" ] image: rhel7:latest command: - sleep - inf name: example volumeMounts: - mountPath: /dev/hugepages name: hugepage - mountPath: /etc/podinfo name: podinfo resources: limits: hugepages-1Gi: 2Gi memory: "1Gi" cpu: "1" requests: hugepages-1Gi: 2Gi env: - name: REQUESTS_HUGEPAGES_1GI <.> valueFrom: resourceFieldRef: containerName: example resource: requests.hugepages-1Gi volumes: - name: hugepage emptyDir: medium: HugePages - name: podinfo downwardAPI: items: - path: "hugepages_1G_request" <.> resourceFieldRef: containerName: example resource: requests.hugepages-1Gi divisor: 1Gi<.>
requests.hugepages-1Gi에서 리소스 사용을 읽고 값을REQUESTS_HUGEPAGES_1GI환경 변수로 표시하도록 지정합니다. <.>는requests.hugepages-1Gi에서 리소스 사용을 읽고 값을 파일/etc/podinfo/hugepages_1G_request로 표시하도록 지정합니다.volume-pod.yaml파일에서 Pod를 생성합니다.$ oc create -f hugepages-volume-pod.yaml
검증
REQUESTS_HUGEPAGES_1GI환경 변수 값을 확인합니다.$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- env | grep REQUESTS_HUGEPAGES_1GI출력 예
REQUESTS_HUGEPAGES_1GI=2147483648
/etc/podinfo/hugepages_1G_request파일의 값을 확인합니다.$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- cat /etc/podinfo/hugepages_1G_request출력 예
2
10.4. 부팅 시 대규모 페이지 구성
노드는 OpenShift Container Platform 클러스터에서 사용되는 대규모 페이지를 사전 할당해야 합니다. 대규모 페이지 예약은 부팅 시 예약하는 방법과 런타임 시 예약하는 방법 두 가지가 있습니다. 부팅 시 예약은 메모리가 아직 많이 조각화되어 있지 않으므로 성공할 가능성이 높습니다. Node Tuning Operator는 현재 특정 노드에서 대규모 페이지에 대한 부팅 시 할당을 지원합니다.
프로세스
노드 재부팅을 최소화하려면 다음 단계를 순서대로 수행해야 합니다.
동일한 대규모 페이지 설정이 필요한 모든 노드에 하나의 레이블을 지정합니다.
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=
다음 콘텐츠로 파일을 생성하고 이름을
hugepages-tuned-boottime.yaml로 지정합니다.apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages 1 namespace: openshift-cluster-node-tuning-operator spec: profile: 2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 3 name: openshift-node-hugepages recommend: - machineConfigLabels: 4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepages
Tuned
hugepages오브젝트를 생성합니다.$ oc create -f hugepages-tuned-boottime.yaml
다음 콘텐츠로 파일을 생성하고 이름을
hugepages-mcp.yaml로 지정합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""머신 구성 풀을 생성합니다.
$ oc create -f hugepages-mcp.yaml
조각화되지 않은 메모리가 충분한 경우 worker-hp 머신 구성 풀의 모든 노드에 50개의 2Mi 대규모 페이지가 할당되어 있어야 합니다.
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100MiTuneD 부트로더 플러그인은 RHCOS(Red Hat Enterprise Linux CoreOS) 작업자 노드만 지원합니다.
10.5. 투명한 대규모 페이지 비활성화
THP(Transparent Huge Pages)는 대규모 페이지를 생성, 관리 및 사용하는 대부분의 측면을 자동화하려고 합니다. THP는 대규모 페이지를 자동으로 관리하므로 모든 유형의 워크로드에 대해 항상 최적으로 처리되는 것은 아닙니다. THP는 많은 애플리케이션이 자체적으로 대규모 페이지를 처리하므로 성능 회귀를 유발할 수 있습니다. 따라서 THP를 비활성화하는 것이 좋습니다. 다음 단계에서는 Node Tuning Operator(NTO)를 사용하여 THP를 비활성화하는 방법을 설명합니다.
프로세스
다음 콘텐츠를 사용하여 파일을 생성하고 이름을
thp-disable-tuned.yaml로 지정합니다.apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: thp-workers-profile namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom tuned profile for OpenShift to turn off THP on worker nodes include=openshift-node [vm] transparent_hugepages=never name: openshift-thp-never-worker recommend: - match: - label: node-role.kubernetes.io/worker priority: 25 profile: openshift-thp-never-workerTuned 오브젝트를 생성합니다.
$ oc create -f thp-disable-tuned.yaml
활성 프로필 목록을 확인합니다.
$ oc get profile -n openshift-cluster-node-tuning-operator
검증
노드 중 하나에 로그인하고 일반 THP 검사를 수행하여 노드가 프로필을 성공적으로 적용했는지 확인합니다.
$ cat /sys/kernel/mm/transparent_hugepage/enabled
출력 예
always madvise [never]
11장. 짧은 대기 시간 튜닝
11.1. 클러스터 노드에 대한 짧은 대기 시간 튜닝 이해
엣지 컴퓨팅은 대기 시간 및 혼잡 문제를 줄이고 통신 및 5G 네트워크 애플리케이션의 애플리케이션 성능을 개선하는 데 중요한 역할을 합니다. 5G의 네트워크 성능 요구 사항을 충족하기 위해서는 대기 시간이 가장 낮은 네트워크 아키텍처를 유지하는 것이 중요합니다. 4G 기술에 비해 평균 대기 시간은 50ms이고 5G는 1ms 이하의 대기 시간에 도달할 수 있습니다. 이렇게 대기 시간이 감소하면 무선 처리량이 10배 증가합니다.
11.1.1. 짧은 대기 시간 정보
Telco 공간에 배포된 많은 애플리케이션에서는 제로 패킷 손실이 가능한 짧은 대기 시간을 요구하고 있습니다. 제로 패킷 손실 튜닝은 네트워크 성능을 저하시키는 고유한 문제를 완화하는 데 도움이 됩니다. 자세한 내용은 RHOSP(Red Hat OpenStack Platform)에서 제로 패킷 손실 튜닝을 참조하십시오.
Edge 컴퓨팅 이니셔티브는 대기 시간을 줄이는 데에도 큰 역할을 합니다. 클라우드 엣지에 있고 사용자에게 더 가깝다고 생각하십시오. 이렇게 되면 멀리 있는 데이터 센터와 사용자 간 거리를 크게 줄여 애플리케이션 응답 시간과 성능 대기 시간이 단축됩니다.
관리자는 많은 엣지 사이트와 로컬 서비스를 중앙 집중식으로 관리하여 가능한 한 가장 낮은 관리 비용으로 모든 배포를 실행할 수 있어야 합니다. 또한, 실시간 짧은 대기 시간과 높은 성능을 실현할 수 있도록 클러스터의 특정 노드를 쉽게 배포하고 구성할 수 있어야 합니다. 대기 시간이 짧은 노드는 CNF(클라우드 네이티브 네트워크 기능) 및 DPDK(데이터 플레인 개발 키트)와 같은 애플리케이션에 유용합니다.
OpenShift Container Platform에서는 현재 실시간 실행과 짧은 대기 시간(약 20마이크로초 미만의 반응 시간)을 지원하기 위해 OpenShift Container Platform 클러스터의 소프트웨어를 튜닝하는 메커니즘을 제공합니다. 이 메커니즘에는 커널 및 OpenShift Container Platform 설정 값 튜닝, 커널 설치, 머신 재구성이 포함되어 있습니다. 하지만 이 방법을 사용하려면 4가지 Operator를 설정해야 하며 수동으로 수행할 경우 복잡하고 실수하기 쉬운 많은 구성을 수행해야 합니다.
OpenShift Container Platform은 Node Tuning Operator를 사용하여 OpenShift Container Platform 애플리케이션에 대해 짧은 대기 시간 성능을 실현할 수 있도록 자동 튜닝을 구현합니다. 클러스터 관리자는 이 성능 프로필 구성을 사용하여 보다 안정적인 방식으로 이러한 변경을 더욱 쉽게 수행할 수 있습니다. 관리자는 커널을 kernel-rt로 업데이트할지 여부를 지정하고, Pod 인프라 컨테이너를 포함하여 클러스터 및 운영 체제 하우스키핑 작업을 위해 CPU를 예약하고, 애플리케이션 컨테이너의 CPU를 분리하여 워크로드를 실행할 수 있습니다.
OpenShift Container Platform 4.14에서는 클러스터에 성능 프로필을 적용하면 클러스터의 모든 노드가 재부팅됩니다. 이 재부팅에는 성능 프로필의 대상이 아닌 컨트롤 플레인 노드 및 작업자 노드가 포함됩니다. 이 릴리스에서는 RHEL 9과 일치하는 Linux 제어 그룹 버전 2(cgroup v2)를 사용하므로 OpenShift Container Platform 4.14에서 알려진 문제입니다. 성능 프로파일과 관련된 짧은 대기 시간 튜닝 기능은 cgroup v2를 지원하지 않으므로 노드가 재부팅되어 cgroup v1 구성으로 다시 전환합니다.
클러스터의 모든 노드를 cgroups v2 구성으로 되돌리려면 Node 리소스를 편집해야 합니다. (OCPBUGS-16976)
현재 cgroup v2에서는 CPU 부하 분산을 비활성화하는 것은 지원되지 않습니다. 따라서 cgroup v2가 활성화된 경우 성능 프로필에서 원하는 동작이 없을 수 있습니다. 성능 프로필을 사용하는 경우에는 cgroup v2를 활성화하는 것은 권장되지 않습니다.
OpenShift Container Platform은 다양한 산업 환경의 요구 사항을 충족하기 위해 PerformanceProfile 을 조정할 수 있는 Node Tuning Operator에 대한 워크로드 힌트도 지원합니다. 워크로드 힌트는 highPowerConsumption (확장된 전력 소비 비용에서 낮은 대기 시간) 및 realTime (하이선 대기 시간에 제공되는 우선 순위)에 사용할 수 있습니다. 이러한 힌트에 대한 true/false 설정의 조합을 사용하여 애플리케이션별 워크로드 프로필 및 요구 사항을 처리할 수 있습니다.
워크로드 힌트는 산업 부문 설정에 대한 성능의 미세 조정을 단순화합니다. "one size fits all" 접근 방식 대신 워크로드 힌트는 우선 순위 배치와 같은 사용 패턴을 제공할 수 있습니다.
- 짧은 대기 시간
- 실시간 기능
- 효율적인 전원 사용
이상적으로 이전에 나열된 모든 항목의 우선 순위가 지정됩니다. 그러나 이러한 항목 중 일부는 다른 항목의 비용이 부과됩니다. Node Tuning Operator는 이제 워크로드 기대치를 인식하고 워크로드의 요구 사항을 보다 효과적으로 충족할 수 있습니다. 이제 클러스터 관리자가 워크로드가 중단되는 사용 사례를 지정할 수 있습니다. Node Tuning Operator는 PerformanceProfile 을 사용하여 워크로드에 대한 성능 설정을 미세 조정합니다.
애플리케이션이 작동하는 환경에는 해당 동작에 영향을 미칩니다. 엄격한 대기 시간 요구 사항이 없는 일반적인 데이터 센터의 경우 일부 고성능 워크로드 Pod에 대해 CPU 파티셔닝을 활성화하는 최소 기본 튜닝만 필요합니다. 대기 시간이 더 높은 데이터 센터와 워크로드의 경우 전력 소비를 최적화하기 위해 여전히 조치를 취할 수 있습니다. 가장 복잡한 경우는 제조 장치 및 소프트웨어 정의 라디오와 같은 대기 시간에 민감한 장비에 가까운 클러스터입니다. 이러한 마지막 배포 클래스를 종종 Far edge라고 합니다. Far edge 배포의 경우 매우 낮은 대기 시간은 최고의 우선 순위이며 전원 관리를 통해 달성됩니다.
11.1.2. 짧은 대기 시간과 실시간 애플리케이션의 하이퍼 스레딩 정보
하이퍼 스레딩은 물리적 CPU 프로세서 코어가 두 개의 논리 코어로 작동하여 두 개의 독립 스레드를 동시에 실행할 수 있는 Intel 프로세서 기술입니다. 하이퍼 스레딩을 사용하면 병렬 처리가 도움이 되는 특정 워크로드 유형에 대해 시스템 처리량을 개선할 수 있습니다. 기본 OpenShift Container Platform 구성에서는 Hyper-Threading이 활성화되어야 합니다.
통신 애플리케이션의 경우 가능한 한 대기 시간을 최소화하도록 애플리케이션 인프라를 설계하는 것이 중요합니다. 하이퍼 스레딩은 성능 속도를 저하시킬 수 있으며 짧은 대기 시간이 필요한 컴퓨팅 집약적인 워크로드의 처리량에 부정적인 영향을 미칠 수 있습니다. 하이퍼 스레딩을 비활성화하면 예측 가능한 성능이 보장되고 이러한 워크로드의 처리 시간이 줄어들 수 있습니다.
OpenShift Container Platform을 실행하는 하드웨어에 따라 하이퍼 스레딩 구현 및 구성이 다릅니다. 해당 하드웨어와 관련된 Hyper-Threading 구현에 대한 자세한 내용은 관련 호스트 하드웨어 튜닝 정보를 참조하십시오. 하이퍼 스레딩을 비활성화하면 클러스터 코어당 비용이 증가할 수 있습니다.
추가 리소스
11.2. 성능 프로필을 사용하여 짧은 대기 시간을 실현하도록 노드 튜닝
클러스터 성능 프로필을 사용하여 짧은 대기 시간을 위해 노드를 조정합니다. 인프라 및 애플리케이션 컨테이너의 CPU를 제한하고, 대규모 페이지, 하이퍼 스레딩을 구성하고, 대기 시간에 민감한 프로세스를 위해 CPU 파티션을 구성할 수 있습니다.
추가 리소스
11.2.1. 성능 프로파일 작성
Performance Profile Creator(PPC)와 이를 사용하여 성능 프로필을 만드는 방법을 설명합니다.
11.2.1.1. 성능 프로파일 작성툴 정보
PPC(Performance Profile Creator)는 성능 프로필을 생성하는 데 사용되는 Node Tuning Operator와 함께 제공되는 명령줄 툴입니다. 이 툴은 클러스터의 must-gather 데이터와 여러 사용자가 제공하는 프로필 인수를 사용합니다. PPC는 하드웨어 및 토폴로지에 적합한 성능 프로필을 생성합니다.
툴은 다음 방법 중 하나로 실행됩니다.
-
podman호출 - 래퍼 스크립트 호출
11.2.1.2. must-gather 명령을 사용하여 클러스터에 대한 데이터 수집
PPC(Performance Profile creator) 툴에는 must-gather 데이터가 필요합니다. 클러스터 관리자는 must-gather 명령을 실행하여 클러스터에 대한 정보를 캡처합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. -
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
선택 사항: 라벨이 있는 일치하는 머신 구성 풀이 있는지 확인합니다.
$ oc describe mcp/worker-rt
출력 예
Name: worker-rt Namespace: Labels: machineconfiguration.openshift.io/role=worker-rt
일치하는 라벨이 없는 경우 MCP 이름과 일치하는 MCP(Machine config pool)의 레이블을 추가합니다.
$ oc label mcp <mcp_name> machineconfiguration.openshift.io/role=<mcp_name>
-
must-gather데이터를 저장하려는 디렉터리로 이동합니다. 다음 명령을 실행하여 클러스터 정보를 수집합니다.
$ oc adm must-gather
선택 사항:
must-gather디렉터리에서 압축 파일을 생성합니다.$ tar cvaf must-gather.tar.gz must-gather/
참고Performance Profile Creator 래퍼 스크립트를 실행하는 경우 압축 출력이 필요합니다.
11.2.1.3. Podman을 사용하여 Performance Profile Creator 실행
클러스터 관리자는 podman 및 Performance Profile Creator를 실행하여 성능 프로필을 만들 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - 클러스터가 베어 메탈 하드웨어에 설치되어 있어야 합니다.
-
podman및 OpenShift CLI(oc)가 설치된 노드가 있습니다. - Node Tuning Operator 이미지에 액세스할 수 있습니다.
프로세스
머신 구성 풀을 확인합니다.
$ oc get mcp
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
Podman을 사용하여
registry.redhat.io에 인증합니다.$ podman login registry.redhat.io
Username: <username> Password: <password>
선택 사항: PPC 툴에 대한 도움말을 표시합니다.
$ podman run --rm --entrypoint performance-profile-creator registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.15 -h
출력 예
A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --offlined-cpu-count int Number of offlined CPUs --per-pod-power-management Enable Per Pod Power Management --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled검색 모드에서 Performance Profile Creator 툴을 실행합니다.
참고검색 모드는
must-gather의 출력을 사용하여 클러스터를 검사합니다. 생성된 출력에는 다음 조건에 대한 정보가 포함됩니다.- 할당된 CPU ID로 NUMA 셀 파티셔닝
- Hyper-Threading 사용 여부
이 정보를 사용하여 Performance Profile Creator 툴에 제공된 일부 인수에 대해 적절한 값을 설정할 수 있습니다.
$ podman run --entrypoint performance-profile-creator -v <path_to_must-gather>/must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.15 --info log --must-gather-dir-path /must-gather
참고이 명령은 Performance Profile Creator 툴을
podman의 새 진입점으로 사용합니다. 호스트의must-gather데이터를 컨테이너 이미지에 매핑하고 필요한 사용자 제공 프로필 인수를 호출하여my-performance-profile.yaml파일을 생성합니다.-v옵션은 다음 구성 요소 중 하나에 대한 경로일 수 있습니다.-
must-gather출력 디렉터리 -
must-gather압축 해제된 .tar 파일이 포함된 기존 디렉터리
info옵션에는 출력 형식을 지정하는 값이 필요합니다. 가능한 값은 log 및 JSON입니다. JSON 형식은 디버깅을 위해 예약되어 있습니다.podman을 실행합니다.$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.15 --mcp-name=worker-cnf --reserved-cpu-count=4 --rt-kernel=true --split-reserved-cpus-across-numa=false --must-gather-dir-path /must-gather --power-consumption-mode=ultra-low-latency --offlined-cpu-count=6 > my-performance-profile.yaml
참고Performance Profile Creator 인수는 Performance Profile Creator 인수 테이블에 표시됩니다. 다음 인수가 필요합니다.
-
reserved-cpu-count -
mcp-name -
rt-kernel
이 예제의
mcp-name인수는oc get mcp명령의 출력에 따라worker-cnf로 설정됩니다. 단일 노드 OpenShift의 경우--mcp-name=master를 사용합니다.-
생성된 YAML 파일을 검토합니다.
$ cat my-performance-profile.yaml
출력 예
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 2-39,48-79 offlined: 42-47 reserved: 0-1,40-41 machineConfigPoolSelector: machineconfiguration.openshift.io/role: worker-cnf nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: true workloadHints: highPowerConsumption: true realTime: true생성된 프로필을 적용합니다.
$ oc apply -f my-performance-profile.yaml
추가 리소스
-
must-gather툴에 대한 자세한 내용은 클러스터에 대한 데이터 수집을 참조하십시오.
11.2.1.3.1. podman을 실행하여 성능 프로파일을 만드는 방법
다음 예제에서는 podman을 실행하여 NUMA 노드 간에 분할될 예약된 20개의 CPU가 있는 성능 프로필을 생성하는 방법을 보여줍니다.
노드 하드웨어 구성:
- 80 CPU
- 하이퍼 스레딩 활성화
- 두 개의 NUMA 노드
- 짝수 번호의 CPU는 NUMA 노드 0에서 실행되고 홀수 번호의 CPU는 NUMA 노드 1에서 실행
podman을 실행하여 성능 프로필을 생성합니다.
$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.15 --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true --split-reserved-cpus-across-numa=true --must-gather-dir-path /must-gather > my-performance-profile.yaml
생성된 프로필은 다음 YAML에 설명되어 있습니다.
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: performance
spec:
cpu:
isolated: 10-39,50-79
reserved: 0-9,40-49
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numa:
topologyPolicy: restricted
realTimeKernel:
enabled: true이 경우 NUMA 노드 0에 CPU 10개가 예약되고 NUMA 노드 1에 CPU 10개가 예약됩니다.
11.2.1.3.2. Performance Profile Creator 래퍼 스크립트 실행
성능 프로필 래퍼 스크립트는 PPC(Performance Profile Creator) 툴의 실행을 간소화합니다. podman 실행과 관련된 복잡성을 숨기고 매핑 디렉터리를 지정하면 성능 프로필을 만들 수 있습니다.
사전 요구 사항
- Node Tuning Operator 이미지에 액세스할 수 있습니다.
-
must-gathertarball에 액세스합니다.
프로세스
예를 들어 다음과 같이
run-perf-profile-creator.sh라는 이름의 파일을 로컬 시스템에 생성합니다$ vi run-perf-profile-creator.sh
다음 코드를 파일에 붙여넣습니다.
#!/bin/bash readonly CONTAINER_RUNTIME=${CONTAINER_RUNTIME:-podman} readonly CURRENT_SCRIPT=$(basename "$0") readonly CMD="${CONTAINER_RUNTIME} run --entrypoint performance-profile-creator" readonly IMG_EXISTS_CMD="${CONTAINER_RUNTIME} image exists" readonly IMG_PULL_CMD="${CONTAINER_RUNTIME} image pull" readonly MUST_GATHER_VOL="/must-gather" NTO_IMG="registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.15" MG_TARBALL="" DATA_DIR="" usage() { print "Wrapper usage:" print " ${CURRENT_SCRIPT} [-h] [-p image][-t path] -- [performance-profile-creator flags]" print "" print "Options:" print " -h help for ${CURRENT_SCRIPT}" print " -p Node Tuning Operator image" print " -t path to a must-gather tarball" ${IMG_EXISTS_CMD} "${NTO_IMG}" && ${CMD} "${NTO_IMG}" -h } function cleanup { [ -d "${DATA_DIR}" ] && rm -rf "${DATA_DIR}" } trap cleanup EXIT exit_error() { print "error: $*" usage exit 1 } print() { echo "$*" >&2 } check_requirements() { ${IMG_EXISTS_CMD} "${NTO_IMG}" || ${IMG_PULL_CMD} "${NTO_IMG}" || \ exit_error "Node Tuning Operator image not found" [ -n "${MG_TARBALL}" ] || exit_error "Must-gather tarball file path is mandatory" [ -f "${MG_TARBALL}" ] || exit_error "Must-gather tarball file not found" DATA_DIR=$(mktemp -d -t "${CURRENT_SCRIPT}XXXX") || exit_error "Cannot create the data directory" tar -zxf "${MG_TARBALL}" --directory "${DATA_DIR}" || exit_error "Cannot decompress the must-gather tarball" chmod a+rx "${DATA_DIR}" return 0 } main() { while getopts ':hp:t:' OPT; do case "${OPT}" in h) usage exit 0 ;; p) NTO_IMG="${OPTARG}" ;; t) MG_TARBALL="${OPTARG}" ;; ?) exit_error "invalid argument: ${OPTARG}" ;; esac done shift $((OPTIND - 1)) check_requirements || exit 1 ${CMD} -v "${DATA_DIR}:${MUST_GATHER_VOL}:z" "${NTO_IMG}" "$@" --must-gather-dir-path "${MUST_GATHER_VOL}" echo "" 1>&2 } main "$@"이 스크립트에 모든 사용자에 대한 실행 권한을 추가합니다.
$ chmod a+x run-perf-profile-creator.sh
선택 사항:
run-perf-profile-creator.sh명령 사용을 표시합니다.$ ./run-perf-profile-creator.sh -h
예상 출력
Wrapper usage: run-perf-profile-creator.sh [-h] [-p image][-t path] -- [performance-profile-creator flags] Options: -h help for run-perf-profile-creator.sh -p Node Tuning Operator image 1 -t path to a must-gather tarball 2 A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --offlined-cpu-count int Number of offlined CPUs --per-pod-power-management Enable Per Pod Power Management --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled
참고두 가지 유형의 인수가 있습니다.
-
래퍼 인수 즉
-h,-p및-t - PPC 인수
-
래퍼 인수 즉
검색 모드에서 performance profile creator 툴을 실행합니다.
참고검색 모드는
must-gather의 출력을 사용하여 클러스터를 검사합니다. 생성된 출력에는 다음에 대한 정보가 포함됩니다.- 할당된 CPU ID로 NUMA 셀 파티션을 분할
- 하이퍼스레딩 활성화 여부
이 정보를 사용하여 Performance Profile Creator 툴에 제공된 일부 인수에 대해 적절한 값을 설정할 수 있습니다.
$ ./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --info=log
참고info옵션에는 출력 형식을 지정하는 값이 필요합니다. 가능한 값은 log 및 JSON입니다. JSON 형식은 디버깅을 위해 예약되어 있습니다.머신 구성 풀을 확인합니다.
$ oc get mcp
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
성능 프로파일을 생성합니다.
$ ./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --mcp-name=worker-cnf --reserved-cpu-count=2 --rt-kernel=true > my-performance-profile.yaml
참고Performance Profile Creator 인수는 Performance Profile Creator 인수 테이블에 표시됩니다. 다음 인수가 필요합니다.
-
reserved-cpu-count -
mcp-name -
rt-kernel
이 예제의
mcp-name인수는oc get mcp명령의 출력에 따라worker-cnf로 설정됩니다. 단일 노드 OpenShift의 경우--mcp-name=master를 사용합니다.-
생성된 YAML 파일을 검토합니다.
$ cat my-performance-profile.yaml
출력 예
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 1-39,41-79 reserved: 0,40 nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: false생성된 프로필을 적용합니다.
참고프로필을 적용하기 전에 Node Tuning Operator를 설치합니다.
$ oc apply -f my-performance-profile.yaml
11.2.1.3.3. Performance Profile Creator 인수
표 11.1. Performance Profile Creator 인수
| 인수 | 설명 |
|---|---|
|
| 하이퍼스레딩을 비활성화합니다.
가능한 값:
기본값: 주의
이 인수가 |
|
|
이는 클러스터 정보를 캡처하며 검색 모드에서만 사용됩니다. 검색 모드에서는 가능한 값은 다음과 같습니다.
기본값: |
|
|
대상 머신에 해당하는 MCP 이름 (예: |
|
| 디렉터리 경로를 수집해야 합니다. 이 매개 변수는 필수입니다.
사용자가 래퍼 스크립트 |
|
| 오프라인 CPU 수입니다. 참고 이 값은 0보다 큰 자연수여야 합니다. 논리 프로세서가 충분하지 않으면 오류 메시지가 기록됩니다. 메시지는 다음과 같습니다. Error: failed to compute the reserved and isolated CPUs: please ensure that reserved-cpu-count plus offlined-cpu-count should be in the range [0,1] Error: failed to compute the reserved and isolated CPUs: please specify the offlined CPU count in the range [0,1] |
|
| 전력 소비 모드입니다. 가능한 값은 다음과 같습니다.
기본값: |
|
|
Pod 전원 관리당 활성화.
가능한 값:
기본값: |
|
|
생성할 성능 프로파일의 이름입니다. 기본값: |
|
| 예약된 CPU 수입니다. 이 매개 변수는 필수입니다. 참고 이것은 자연수여야 합니다. 0 값은 허용되지 않습니다. |
|
| 실시간 커널을 활성화합니다. 이 매개 변수는 필수입니다.
가능한 값: |
|
| NUMA 노드에서 예약된 CPU를 분할합니다.
가능한 값:
기본값: |
|
| 생성할 성능 프로필의 Kubelet Topology Manager 정책입니다. 가능한 값은 다음과 같습니다.
기본값: |
|
| DPDK(사용자 수준 네트워킹)가 활성화된 상태에서 실행합니다.
가능한 값:
기본값: |
11.2.1.4. 성능 프로필 참조
다음 참조 성능 프로필을 기반으로 사용하여 고유한 사용자 지정 프로필을 개발할 수 있습니다.
11.2.1.4.1. OpenStack에서 OVS-DPDK를 사용하는 클러스터의 성능 프로필 템플릿
RHOSP(Red Hat OpenStack Platform)에서 OVS-DPDK(Data Plane Development Kit)를 사용하여 Open vSwitch를 사용하는 클러스터의 머신 성능을 최대화하려면 성능 프로필을 사용할 수 있습니다.
다음 성능 프로필 템플릿을 사용하여 배포에 대한 프로필을 생성할 수 있습니다.
OVS-DPDK를 사용하는 클러스터의 성능 프로필 템플릿
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: cnf-performanceprofile
spec:
additionalKernelArgs:
- nmi_watchdog=0
- audit=0
- mce=off
- processor.max_cstate=1
- idle=poll
- intel_idle.max_cstate=0
- default_hugepagesz=1GB
- hugepagesz=1G
- intel_iommu=on
cpu:
isolated: <CPU_ISOLATED>
reserved: <CPU_RESERVED>
hugepages:
defaultHugepagesSize: 1G
pages:
- count: <HUGEPAGES_COUNT>
node: 0
size: 1G
nodeSelector:
node-role.kubernetes.io/worker: ''
realTimeKernel:
enabled: false
globallyDisableIrqLoadBalancing: true
CPU_ISOLATED,CPU_RESERVED 및 HUGEPAGES_COUNT 키에 대한 구성에 적합한 값을 삽입합니다.
11.2.1.4.2. Telco RAN DU 참조 설계 성능 프로파일 템플릿
다음 성능 프로필은 상용 하드웨어에서 OpenShift Container Platform 클러스터에 대한 노드 수준 성능 설정을 구성하여 Telco RAN DU 워크로드를 호스팅합니다.
Telco RAN DU 참조 성능 프로파일
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
# if you change this name make sure the 'include' line in TunedPerformancePatch.yaml
# matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name}
# Also in file 'validatorCRs/informDuValidator.yaml':
# name: 50-performance-${PerformanceProfile.metadata.name}
name: openshift-node-performance-profile
annotations:
ran.openshift.io/reference-configuration: "ran-du.redhat.com"
spec:
additionalKernelArgs:
- "rcupdate.rcu_normal_after_boot=0"
- "efi=runtime"
- "vfio_pci.enable_sriov=1"
- "vfio_pci.disable_idle_d3=1"
- "module_blacklist=irdma"
cpu:
isolated: $isolated
reserved: $reserved
hugepages:
defaultHugepagesSize: $defaultHugepagesSize
pages:
- size: $size
count: $count
node: $node
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/$mcp: ""
nodeSelector:
node-role.kubernetes.io/$mcp: ''
numa:
topologyPolicy: "restricted"
# To use the standard (non-realtime) kernel, set enabled to false
realTimeKernel:
enabled: true
workloadHints:
# WorkloadHints defines the set of upper level flags for different type of workloads.
# See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints
# for detailed descriptions of each item.
# The configuration below is set for a low latency, performance mode.
realTime: true
highPowerConsumption: false
perPodPowerManagement: false
11.2.1.4.3. Telco 코어 참조 설계 성능 프로파일 템플릿
다음 성능 프로필은 상용 하드웨어에서 OpenShift Container Platform 클러스터에 대한 노드 수준 성능 설정을 구성하여 통신 핵심 워크로드를 호스팅합니다.
Telco 코어 참조 성능 프로파일
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
# if you change this name make sure the 'include' line in TunedPerformancePatch.yaml
# matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name}
# Also in file 'validatorCRs/informDuValidator.yaml':
# name: 50-performance-${PerformanceProfile.metadata.name}
name: openshift-node-performance-profile
annotations:
ran.openshift.io/reference-configuration: "ran-du.redhat.com"
spec:
additionalKernelArgs:
- "rcupdate.rcu_normal_after_boot=0"
- "efi=runtime"
- "vfio_pci.enable_sriov=1"
- "vfio_pci.disable_idle_d3=1"
- "module_blacklist=irdma"
cpu:
isolated: $isolated
reserved: $reserved
hugepages:
defaultHugepagesSize: $defaultHugepagesSize
pages:
- size: $size
count: $count
node: $node
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/$mcp: ""
nodeSelector:
node-role.kubernetes.io/$mcp: ''
numa:
topologyPolicy: "restricted"
# To use the standard (non-realtime) kernel, set enabled to false
realTimeKernel:
enabled: true
workloadHints:
# WorkloadHints defines the set of upper level flags for different type of workloads.
# See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints
# for detailed descriptions of each item.
# The configuration below is set for a low latency, performance mode.
realTime: true
highPowerConsumption: false
perPodPowerManagement: false
11.2.2. 지원되는 성능 프로필 API 버전
Node Tuning Operator는 성능 프로필 apiVersion 필드에 대해 v2,v1, v1alpha1 을 지원합니다. v1 및 v1alpha1 API는 동일합니다. v2 API에는 기본값인 false 값을 사용하여 선택적 부울 필드 loballyDisableIrqLoadBalancing이 포함됩니다.
장치 인터럽트 처리를 사용하기 위해 성능 프로파일을 업그레이드
Node Tuning Operator 성능 프로파일 CRD(사용자 정의 리소스 정의)를 v1 또는 v1alpha1에서 v2로 업그레이드하는 경우 기존 프로필에서 globallyDisableIrqLoadBalancing 이 true 로 설정됩니다.
globallyDisableIrqLoadBalancing 은 Isolated CPU 세트에 대해 IRQ 로드 밸런싱이 비활성화됩니다. 옵션이 true 로 설정되면 Isolated CPU 세트에 대한 IRQ 로드 밸런싱이 비활성화됩니다. 옵션을 false 로 설정하면 모든 CPU에서 IRQ를 분산할 수 있습니다.
Node Tuning Operator API를 v1alpha1에서 v1로 업그레이드
Node Tuning Operator API 버전을 v1alpha1에서 v1로 업그레이드할 때 "None" 변환 전략을 사용하여 v1alpha1 성능 프로파일이 즉시 변환되고 API 버전 v1을 사용하여 Node Tuning Operator에 제공됩니다.
Node Tuning Operator API를 v1alpha1 또는 v1에서 v2로 업그레이드
이전 Node Tuning Operator API 버전에서 업그레이드할 때 기존 v1 및 v1alpha1 성능 프로파일은 true 값이 true 인 globallyDisableIrqLoadBalancing 필드를 삽입하는 변환 Webhook를 사용하여 변환됩니다.
11.2.3. 워크로드 힌트를 사용하여 노드 전력 소비 및 실시간 처리 구성
프로세스
-
"워크로드 힌트 이해"의 표에 설명된 대로 환경의 하드웨어 및 토폴로지에 적합한
PerformanceProfile을 생성합니다. 예상 워크로드와 일치하도록 프로필을 조정합니다. 이 예제에서는 가능한 가장 낮은 대기 시간을 위해 튜닝합니다. highPowerConsumption및realTime워크로드 힌트를 추가합니다. 둘 다 여기에서true로 설정됩니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: workload-hints spec: ... workloadHints: highPowerConsumption: true 1 realTime: true 2
성능 프로파일에서 realTime 워크로드 힌트 플래그가 true 로 설정된 경우 고정 CPU가 있는 보장된 모든 Pod에 cpu-quota.crio.io: disable 주석을 추가합니다. 이 주석은 Pod 내에서 프로세스 성능이 저하되지 않도록 하는 데 필요합니다. realTime 워크로드 힌트가 명시적으로 설정되지 않은 경우 기본값은 true 입니다.
다음 표에서는 전력 소비와 실시간 설정의 조합이 대기 시간에 미치는 영향에 대해 설명합니다.
표 11.2. 대기 시간에 전력 소비 및 실시간 설정 조합의 영향
| Performance Profile creator 설정 | 팁 | 환경 | 설명 |
|---|---|---|---|
| Default |
workloadHints: highPowerConsumption: false realTime: false | 대기 시간 요구 사항이 없는 처리량 클러스터 | CPU 파티셔닝을 통해서만 성능 달성. |
| low-latency |
workloadHints: highPowerConsumption: false realTime: true | 지역 데이터 센터 | 전력 관리, 대기 시간 및 처리량 간의 손상 등 에너지 절약과 대기 시간이 단축되는 것이 좋습니다. |
| Ultra-low-latency |
workloadHints: highPowerConsumption: true realTime: true | 원거리 엣지 클러스터, 대기 시간 중요한 워크로드 | 전력 소비 증가의 비용으로 절대 최소 대기 시간 및 최대 결정론에 최적화되어 있습니다. |
| Pod별 전원 관리 |
workloadHints: realTime: true highPowerConsumption: false perPodPowerManagement: true | 심각 및 중요하지 않은 워크로드 | Pod당 전원 관리를 허용합니다. |
11.2.4. 공동 배치된 높은 우선 순위 워크로드 및 낮은 우선 순위 워크로드를 실행하는 노드에 대한 전원 저장 구성
우선 순위가 높은 워크로드가 높은 노드의 대기 시간 또는 처리량에 영향을 미치지 않고 우선 순위가 높은 워크로드가 낮은 노드에 대한 전원을 절약할 수 있습니다. 워크로드 자체를 수정하지 않고도 전력 절감이 가능합니다.
이 기능은 Intel Ice Lake 이상 세대의 Intel CPU에서 지원됩니다. 프로세서의 기능은 높은 우선 순위 워크로드의 대기 시간 및 처리량에 영향을 미칠 수 있습니다.
사전 요구 사항
- BIOS에서 C-states 및 운영 체제를 활성화했습니다.
프로세스
per-pod-power-management인수가true로 설정된PerformanceProfile을 생성합니다.$ podman run --entrypoint performance-profile-creator -v \ /must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.15 \ --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true \ --split-reserved-cpus-across-numa=false --topology-manager-policy=single-numa-node \ --must-gather-dir-path /must-gather --power-consumption-mode=low-latency \ 1 --per-pod-power-management=true > my-performance-profile.yaml- 1
per-pod-power-management인수가true로 설정된 경우power-consumption-mode인수는default또는low-latency여야 합니다.
perPodPowerManagement가 있는PerformanceProfile의 예apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: [.....] workloadHints: realTime: true highPowerConsumption: false perPodPowerManagement: truePerformanceProfileCR(사용자 정의 리소스)에서 기본cpufreqgovernor를 추가 커널 인수로 설정합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: ... additionalKernelArgs: - cpufreq.default_governor=schedutil 1- 1
- 그러나
schedutilgovernor를 사용하는 것이 좋습니다. 그러나온디맨드또는전원 세이저와 같은 다른 governor를 사용할 수있습니다.
TunedPerformancePatchCR에서 최대 CPU 빈도를 설정합니다.spec: profile: - data: | [sysfs] /sys/devices/system/cpu/intel_pstate/max_perf_pct = <x> 1- 1
max_perf_pct는cpufreq드라이버가 지원되는 최대 cpu 빈도의 백분율로 설정할 수 있는 최대 빈도를 제어합니다. 이 값은 모든 CPU에 적용됩니다./sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_max_freq에서 지원되는 최대 빈도를 확인할 수 있습니다. 시작점으로 모든 CPU를 모든코어frequency로 제한하는 백분율로 사용할 수 있습니다.모든 코어의frequency는 코어가 완전히 비어 있을 때 모든 코어가 실행되는 빈도입니다.
11.2.5. 인프라 및 애플리케이션 컨테이너의 CPU 제한
일반 하우스키핑 및 워크로드 작업에서는 대기 시간에 민감한 프로세스에 영향을 줄 수 있는 방식으로 CPU를 사용합니다. 기본적으로 컨테이너 런타임은 모든 온라인 CPU를 사용하여 모든 컨테이너를 함께 실행하여 컨텍스트 스위치와 대기 시간이 급증할 수 있습니다. CPU를 파티셔닝하면 noisy 프로세스에서 서로 분리하여 대기 시간에 민감한 프로세스를 방해하지 않습니다. 다음 표에서는 Node Tuning Operator를 사용하여 노드를 조정한 후 CPU에서 프로세스가 실행되는 방법을 설명합니다.
표 11.3. 프로세스의 CPU 할당
| 프로세스 유형 | 세부 정보 |
|---|---|
|
| 대기 시간이 짧은 워크로드가 실행 중인 경우를 제외하고 모든 CPU에서 실행 |
| 인프라 Pod | 대기 시간이 짧은 워크로드가 실행 중인 경우를 제외하고 모든 CPU에서 실행 |
| 인터럽트 | 예약된 CPU로 리디렉션(OpenShift Container Platform 4.7 이상에서 선택 사항) |
| 커널 프로세스 | 예약된 CPU에 핀 |
| 대기 시간에 민감한 워크로드 Pod | 격리된 풀에서 특정 전용 CPU 세트에 고정 |
| OS 프로세스/systemd 서비스 | 예약된 CPU에 핀 |
모든 QoS 프로세스 유형, Burstable,BestEffort 또는 Guaranteed 의 Pod의 노드에 있는 코어의 할당 가능한 용량은 격리된 풀의 용량과 동일합니다. 예약된 풀의 용량은 클러스터 및 운영 체제 하우스키핑 작업에서 사용할 수 있는 노드의 총 코어 용량에서 제거됩니다.
예시 1
노드에는 100개의 코어 용량이 있습니다. 클러스터 관리자는 성능 프로필을 사용하여 분리된 풀에 50개의 코어와 예약된 풀에 50개의 코어를 할당합니다. 클러스터 관리자는 QoS 보장된 Pod에 25개의 코어를 할당하고 BestEffort 또는 Burstable Pod의 경우 25개의 코어를 할당합니다. 이는 격리된 풀의 용량과 일치합니다.
예시 2
노드에는 100개의 코어 용량이 있습니다. 클러스터 관리자는 성능 프로필을 사용하여 분리된 풀에 50개의 코어와 예약된 풀에 50개의 코어를 할당합니다. 클러스터 관리자는 QoS 보장된 Pod에 50개의 코어를 할당하고 BestEffort 또는 Burstable Pod의 코어 1개를 할당합니다. 이렇게 하면 격리된 풀의 용량을 하나의 코어로 초과합니다. CPU 용량이 부족하여 Pod 예약이 실패합니다.
사용할 정확한 파티셔닝 패턴은 하드웨어, 워크로드 특성 및 예상되는 시스템 로드와 같은 여러 요인에 따라 다릅니다. 일부 샘플 사용 사례는 다음과 같습니다.
- 대기 시간에 민감한 워크로드가 NIC(네트워크 인터페이스 컨트롤러)와 같은 특정 하드웨어를 사용하는 경우 격리된 풀의 CPU가 이 하드웨어에 최대한 가까운지 확인합니다. 최소한 동일한 NUMA(Non-Uniform Memory Access) 노드에 워크로드를 배치해야 합니다.
- 예약된 풀은 모든 인터럽트를 처리하는 데 사용됩니다. 시스템 네트워킹에 따라 들어오는 모든 패킷 인터럽트를 처리하기 위해 충분히 크기의 예비 풀을 할당합니다. 4.15 이상 버전에서 워크로드는 선택적으로 민감한 것으로 레이블을 지정할 수 있습니다.
예약 및 격리된 파티션에 사용해야 하는 특정 CPU에 대한 결정에는 자세한 분석과 측정이 필요합니다. 장치 및 메모리의 NUMA 선호도와 같은 요소가 역할을 합니다. 선택 사항은 워크로드 아키텍처 및 특정 사용 사례에 따라 다릅니다.
예약 및 격리된 CPU 풀은 겹치지 않아야 하며 작업자 노드에서 사용 가능한 모든 코어에 걸쳐 있어야 합니다.
하우스키핑 작업과 워크로드가 서로 방해하지 않도록 하려면 성능 프로필의 spec 섹션에 두 개의 CPU 그룹을 지정합니다.
-
isolated- 애플리케이션 컨테이너 워크로드에 대한 CPU를 지정합니다. 이러한 CPU는 대기 시간이 가장 짧습니다. 이 그룹의 프로세스에는 중단이 발생하지 않으므로 예를 들어 프로세스가 훨씬 더 높은 DPDK 제로 패킷 손실 대역폭에 도달할 수 있습니다. -
reserved- 클러스터 및 운영 체제 하우스키핑 작업의 CPU를 지정합니다.예약된그룹의 스레드는 종종 사용 중입니다.예약된그룹에서 대기 시간에 민감한 애플리케이션을 실행하지 마십시오. 대기 시간에 민감한 애플리케이션은격리된그룹에서 실행됩니다.
프로세스
- 환경의 하드웨어 및 토폴로지에 적합한 성능 프로필을 만듭니다.
인프라 및 애플리케이션 컨테이너에 대해
reserved및isolated하려는 CPU와 함께 예약 및 격리된 매개변수를 추가합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: infra-cpus spec: cpu: reserved: "0-4,9" 1 isolated: "5-8" 2 nodeSelector: 3 node-role.kubernetes.io/worker: ""
11.2.6. 클러스터의 하이퍼 스레딩 구성
OpenShift Container Platform 클러스터에 대한 Hyper-Threading을 구성하려면 성능 프로필의 CPU 스레드를 예약 또는 분리된 CPU 풀에 대해 구성된 동일한 코어로 설정합니다.
성능 프로필을 구성하고 호스트의 Hyper-Threading 구성을 변경하는 경우 PerformanceProfile YAML에서 CPU isolated 및 reserved 필드를 새 구성과 일치하도록 업데이트해야 합니다.
이전에 활성화된 호스트 Hyper-Threading 구성을 비활성화하면 PerformanceProfile YAML에 나열된 CPU 코어 ID가 올바르지 않을 수 있습니다. 이렇게 잘못된 구성으로 인해 나열된 CPU를 더 이상 찾을 수 없으므로 노드를 사용할 수 없게 될 가능성이 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - OpenShift CLI(oc)를 설치합니다.
프로세스
구성할 호스트의 모든 CPU에서 실행중인 스레드를 확인합니다.
클러스터에 로그인하고 다음 명령을 실행하여 호스트 CPU에서 실행중인 스레드를 볼 수 있습니다.
$ lscpu --all --extended
출력 예
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ 0 0 0 0 0:0:0:0 yes 4800.0000 400.0000 1 0 0 1 1:1:1:0 yes 4800.0000 400.0000 2 0 0 2 2:2:2:0 yes 4800.0000 400.0000 3 0 0 3 3:3:3:0 yes 4800.0000 400.0000 4 0 0 0 0:0:0:0 yes 4800.0000 400.0000 5 0 0 1 1:1:1:0 yes 4800.0000 400.0000 6 0 0 2 2:2:2:0 yes 4800.0000 400.0000 7 0 0 3 3:3:3:0 yes 4800.0000 400.0000
이 예에서는 4개의 물리적 CPU 코어에서 실행 중인 논리 CPU 코어가 8개 있습니다. CPU0 및 CPU4는 물리적 Core0에서 실행되고 CPU1 및 CPU5는 물리적 Core 1에서 실행되고 있습니다.
또는 특정 물리적 CPU 코어(아래 예제에서
cpu0)에 설정된 스레드를 보려면 쉘 프롬프트를 열고 다음을 실행합니다.$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
출력 예
0-4
PerformanceProfileYAML에서 분리 및 예약된 CPU를 적용합니다. 예를 들어 논리 코어 CPU0 및 CPU4를isolated로, 논리 코어 CPU1을 CPU3으로, CPU5를예약된CPU7으로 설정할 수 있습니다. 예약 및 분리된 CPU를 구성하면 Pod의 인프라 컨테이너는 예약된 CPU를 사용하고 애플리케이션 컨테이너는 분리된 CPU를 사용합니다.... cpu: isolated: 0,4 reserved: 1-3,5-7 ...참고예약 및 격리된 CPU 풀은 겹치지 않아야 하며 작업자 노드에서 사용 가능한 모든 코어에 걸쳐 있어야 합니다.
Hyper-Threading은 대부분의 Intel 프로세서에서 기본적으로 활성화되어 있습니다. Hyper-Threading을 활성화하면 특정 코어에서 처리되는 모든 스레드를 동일한 코어에서 분리하거나 처리해야 합니다.
하이퍼 스레딩을 활성화하면 모든 보장된 Pod에서 동시 멀티 스레딩(SMT) 수준의 여러 개를 사용하여 Pod가 실패할 수 있는 "noisy neighbor" 상황을 방지해야 합니다. 자세한 내용은 정적 정책 옵션을 참조하십시오.
11.2.6.1. 짧은 대기 시간 애플리케이션의 하이퍼 스레딩 비활성화
대기 시간이 짧은 처리를 위해 클러스터를 구성할 때 클러스터를 배포하기 전에 Hyper-Threading을 비활성화할지 여부를 고려하십시오. 하이퍼 스레딩을 비활성화하려면 다음 단계를 수행합니다.
- 하드웨어 및 토폴로지에 적합한 성능 프로필을 생성합니다.
nosmt를 추가 커널 인수로 설정합니다. 다음 성능 프로파일 예에서는 이 설정에 대해 설명합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - idle=poll - intel_idle.max_cstate=0 - nosmt cpu: isolated: 2-3 reserved: 0-1 hugepages: defaultHugepagesSize: 1G pages: - count: 2 node: 0 size: 1G nodeSelector: node-role.kubernetes.io/performance: '' realTimeKernel: enabled: true참고예약 및 분리된 CPU를 구성하면 Pod의 인프라 컨테이너는 예약된 CPU를 사용하고 애플리케이션 컨테이너는 분리된 CPU를 사용합니다.
11.2.7. 보장된 pod 분리 CPU의 장치 중단 처리 관리
Node Tuning Operator는 호스트 CPU를 Pod 인프라 컨테이너를 포함하여 클러스터 및 운영 체제 하우스키핑 작업을 위해 예약된 CPU와 워크로드를 실행하기 위해 애플리케이션 컨테이너의 분리된 CPU로 나누어 호스트 CPU를 관리할 수 있습니다. 이를 통해 대기 시간이 짧은 워크로드의 CPU를 분리된 상태로 설정할 수 있습니다.
장치 중단은 보장된 pod가 실행 중인 CPU를 제외하고 CPU의 과부하를 방지하기 위해 모든 분리된 CPU와 예약된 CPU 간에 균형을 유지합니다. pod에 관련 주석이 설정되어 있으면 보장된 Pod CPU가 장치 인터럽트를 처리하지 못합니다.
새로운 성능 프로파일 필드 globallyDisableIrqLoadBalancing은 장치 중단을 처리할지 여부를 관리하는 데 사용할 수 있습니다. 특정 워크로드의 경우 예약된 CPU가 장치 인터럽트를 처리하기에 충분하지 않으며, 이러한 이유로 장치 인터럽트는 분리된 CPU에서 전역적으로 비활성화되지 않습니다. 기본적으로 Node Tuning Operator는 분리된 CPU에서 장치 인터럽트를 비활성화하지 않습니다.
11.2.7.1. 노드의 유효한 IRQ 선호도 설정 찾기
일부 IRQ 컨트롤러는 IRQ 선호도 설정을 지원하지 않으며 항상 모든 온라인 CPU를 IRQ 마스크로 노출합니다. 이러한 IRQ 컨트롤러는 CPU 0에서 효과적으로 실행됩니다.
다음은 IRQ 선호도 설정에 대한 지원이 부족한 드라이버 및 하드웨어의 예입니다. 목록은 전혀 완전하지 않습니다.
-
megaraid_sas와 같은 일부 RAID 컨트롤러 드라이버 - 많은 비휘발성 메모리 표현(NVMe) 드라이버
- 마더보드(LOM) 네트워크 컨트롤러의 일부 LAN
-
드라이버는
managed_irqs사용
IRQ 선호도 설정을 지원하지 않는 이유는 프로세서 유형, IRQ 컨트롤러 또는 마더보드의 회로 연결과 같은 요인과 연관될 수 있습니다.
IRQ의 유효 선호도가 격리된 CPU로 설정된 경우 IRQ 선호도 설정을 지원하지 않는 일부 하드웨어 또는 드라이버의 서명일 수 있습니다. 효과적인 선호도를 찾으려면 호스트에 로그인하고 다음 명령을 실행합니다.
$ find /proc/irq -name effective_affinity -printf "%p: " -exec cat {} \;출력 예
/proc/irq/0/effective_affinity: 1 /proc/irq/1/effective_affinity: 8 /proc/irq/2/effective_affinity: 0 /proc/irq/3/effective_affinity: 1 /proc/irq/4/effective_affinity: 2 /proc/irq/5/effective_affinity: 1 /proc/irq/6/effective_affinity: 1 /proc/irq/7/effective_affinity: 1 /proc/irq/8/effective_affinity: 1 /proc/irq/9/effective_affinity: 2 /proc/irq/10/effective_affinity: 1 /proc/irq/11/effective_affinity: 1 /proc/irq/12/effective_affinity: 4 /proc/irq/13/effective_affinity: 1 /proc/irq/14/effective_affinity: 1 /proc/irq/15/effective_affinity: 1 /proc/irq/24/effective_affinity: 2 /proc/irq/25/effective_affinity: 4 /proc/irq/26/effective_affinity: 2 /proc/irq/27/effective_affinity: 1 /proc/irq/28/effective_affinity: 8 /proc/irq/29/effective_affinity: 4 /proc/irq/30/effective_affinity: 4 /proc/irq/31/effective_affinity: 8 /proc/irq/32/effective_affinity: 8 /proc/irq/33/effective_affinity: 1 /proc/irq/34/effective_affinity: 2
일부 드라이버는 커널 및 사용자 공간에 의해 내부적으로 관리되는 managed_irqs 를 사용합니다. 사용자 공간은 선호도를 변경할 수 없습니다. 경우에 따라 이러한 IRQ가 분리된 CPU에 할당될 수 있습니다. managed_irqs 에 대한 자세한 내용은 분리된 CPU를 대상으로 하는 경우에도 관리 인터럽트의 유사성을 변경할 수 없습니다.
11.2.7.2. 노드 인터럽트 유사성 구성
IRQ(장치 인터럽트 요청)를 수신할 수 있는 코어를 제어하도록 IRQ 동적 로드 밸런싱 클러스터 노드를 구성합니다.
사전 요구 사항
- 코어 격리의 경우 모든 서버 하드웨어 구성 요소에서 IRQ 선호도를 지원해야 합니다. 서버의 하드웨어 구성 요소가 IRQ 선호도를 지원하는지 확인하려면 서버의 하드웨어 사양을 보거나 하드웨어 공급자에게 문의하십시오.
프로세스
- cluster-admin 역할의 사용자로 OpenShift Container Platform 클러스터에 로그인합니다.
-
performance.openshift.io/v2를 사용하도록 성능 프로파일의apiVersion을 설정합니다. -
globallyDisableIrqLoadBalancing필드를 삭제제거하거나false로 설정합니다. 적절한 분리 및 예약된 CPU를 설정합니다. 다음 스니펫에서는 두 개의 CPU를 예약하는 프로파일을 보여줍니다.
isolatedCPU 세트에서 실행되는 Pod에 대해 IRQ 로드 밸런싱이 활성화됩니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: dynamic-irq-profile spec: cpu: isolated: 2-5 reserved: 0-1 ...참고예약 및 분리된 CPU를 구성하면 운영 체제 프로세스, 커널 프로세스 및 systemd 서비스가 예약된 CPU에서 실행됩니다. 인프라 Pod는 대기 시간이 짧은 워크로드가 실행되는 위치를 제외하고 모든 CPU에서 실행됩니다. 대기 시간이 짧은 워크로드 Pod는 격리된 풀의 전용 CPU에서 실행됩니다. 자세한 내용은 "인프라 및 애플리케이션 컨테이너용 CPU 제한"을 참조하십시오.
11.2.8. 대규모 페이지 구성
노드는 OpenShift Container Platform 클러스터에서 사용되는 대규모 페이지를 사전 할당해야 합니다. Node Tuning Operator를 사용하여 특정 노드에 대규모 페이지를 할당합니다.
OpenShift Container Platform에서는 대규모 페이지를 생성하고 할당하는 방법을 제공합니다. Node Tuning Operator는 성능 프로필을 사용하여 이 작업을 더 쉽게 수행할 수 있는 방법을 제공합니다.
예를 들어 성능 프로필의 hugepages pages 섹션에서 size, count 및 node(선택사항)로 된 여러 블록을 지정할 수 있습니다.
hugepages:
defaultHugepagesSize: "1G"
pages:
- size: "1G"
count: 4
node: 0 1- 1
node는 대규모 페이지가 할당된 NUMA 노드입니다.node를 생략하면 페이지가 모든 NUMA 노드에 균등하게 분산됩니다.
관련 머신 구성 풀 상태에 업데이트가 완료된 것으로 나타날 때까지 기다립니다.
대규모 페이지를 할당하기 위해 수행해야 하는 구성 단계는 이것이 전부입니다.
검증
구성을 검증하려면 노드의
/proc/meminfo파일을 참조하십시오.$ oc debug node/ip-10-0-141-105.ec2.internal
# grep -i huge /proc/meminfo
출력 예
AnonHugePages: ###### ## ShmemHugePages: 0 kB HugePages_Total: 2 HugePages_Free: 2 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: #### ## Hugetlb: #### ##
oc describe를 사용하여 새 크기를 보고합니다.$ oc describe node worker-0.ocp4poc.example.com | grep -i huge
출력 예
hugepages-1g=true hugepages-###: ### hugepages-###: ###
11.2.8.1. 여러 대규모 페이지 크기 할당
동일한 컨테이너에서 다양한 크기의 대규모 페이지를 요청할 수 있습니다. 이 경우 다양한 대규모 페이지 크기 요구사항이 있는 컨테이너로 구성된 더 복잡한 Pod를 정의할 수 있습니다.
예를 들어 1G 및 2M 크기를 정의할 수 있으며 Node Tuning Operator는 다음과 같이 노드에서 크기를 둘 다 구성합니다.
spec:
hugepages:
defaultHugepagesSize: 1G
pages:
- count: 1024
node: 0
size: 2M
- count: 4
node: 1
size: 1G11.2.9. Node Tuning Operator를 사용하여 NIC 대기열 감소
Node Tuning Operator를 사용하면 성능 향상을 위해 NIC 대기열을 줄일 수 있습니다. 성능 프로필을 사용하여 조정되므로 다양한 네트워크 장치에 대한 대기열을 사용자 지정할 수 있습니다.
11.2.9.1. 성능 프로파일을 사용하여 NIC 큐 조정
성능 프로파일을 사용하면 각 네트워크 장치의 대기열 수를 조정할 수 있습니다.
지원되는 네트워크 장치는 다음과 같습니다.
- 비가상 네트워크 장치
- 멀티 큐(채널)를 지원하는 네트워크 장치
지원되지 않는 네트워크 장치는 다음과 같습니다.
- Pure Software 네트워크 인터페이스
- 블록 장치
- Intel DPDK 가상 기능
사전 요구 사항
-
cluster-admin역할을 가진 사용자로 클러스터에 액세스합니다. -
OpenShift CLI(
oc)를 설치합니다.
프로세스
-
cluster-admin권한이 있는 사용자로 Node Tuning Operator를 실행하는 OpenShift Container Platform 클러스터에 로그인합니다. - 하드웨어 및 토폴로지에 적합한 성능 프로파일을 만들고 적용합니다. 프로파일 생성에 대한 지침은 "성능 프로파일 생성" 섹션을 참조하십시오.
생성된 성능 프로파일을 편집합니다.
$ oc edit -f <your_profile_name>.yaml
spec필드를net오브젝트로 채웁니다. 오브젝트 목록에는 다음 두 개의 필드가 포함될 수 있습니다.-
userLevelNetworking은 부울 플래그로 지정된 필수 필드입니다.userLevelNetworking이true인 경우 지원되는 모든 장치에 대해 대기열 수가 예약된 CPU 수로 설정됩니다. 기본값은false입니다. devices는 예약된 CPU 수로 큐를 설정할 장치 목록을 지정하는 선택적 필드입니다. 장치 목록이 비어 있으면 구성이 모든 네트워크 장치에 적용됩니다. 구성은 다음과 같습니다.interfacename: 이 필드는 인터페이스 이름을 지정하고, 양수 또는 음수일 수 있는 쉘 스타일 와일드카드를 지원합니다.-
와일드카드 구문의 예는 다음과 같습니다.
<string> .* -
음수 규칙 앞에는 느낌표가 붙습니다. 제외된 목록이 아닌 모든 장치에 넷 큐 변경 사항을 적용하려면
!<device>를 사용합니다(예:!eno1).
-
와일드카드 구문의 예는 다음과 같습니다.
-
vendorID: 접두사가0x인 16비트 16진수로 표시되는 네트워크 장치 공급업체 ID입니다. deviceID:0x접두사가 있는 16비트 16진수로 표시되는 네트워크 장치 ID(모델)입니다.참고deviceID가 지정되어 있는 경우vendorID도 정의해야 합니다. 장치 항목interfaceName,vendorID,vendorID및deviceID의 쌍에 지정된 모든 장치 식별자와 일치하는 장치는 네트워크 장치로 간주됩니다. 그러면 이 네트워크 장치의 네트워크 대기열 수가 예약된 CPU 수로 설정됩니다.두 개 이상의 장치가 지정되면 네트워크 대기열 수가 해당 장치 중 하나와 일치하는 모든 네트워크 장치로 설정됩니다.
-
다음 예제 성능 프로필을 사용하여 대기열 수를 모든 장치에 예약된 CPU 수로 설정합니다.
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/worker-cnf: ""다음 예제 성능 프로필을 사용하여 정의된 장치 식별자와 일치하는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다.
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "eth0" - interfaceName: "eth1" - vendorID: "0x1af4" deviceID: "0x1000" nodeSelector: node-role.kubernetes.io/worker-cnf: ""다음 예제 성능 프로필을 사용하여 인터페이스 이름
eth로 시작하는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "eth*" nodeSelector: node-role.kubernetes.io/worker-cnf: ""이 예제 성능 프로필을 사용하여 이름이
eno1이외의 인터페이스가 있는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "!eno1" nodeSelector: node-role.kubernetes.io/worker-cnf: ""인터페이스 이름
eth0,0x1af4의vendorID및0x1000의deviceID는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다. 성능 프로파일 예는 다음과 같습니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,55-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: "eth0" - vendorID: "0x1af4" deviceID: "0x1000" nodeSelector: node-role.kubernetes.io/worker-cnf: ""업데이트된 성능 프로필을 적용합니다.
$ oc apply -f <your_profile_name>.yaml
추가 리소스
11.2.9.2. 대기열 상태 확인
이 섹션에서는 다양한 성능 프로필과 변경 사항이 적용되었는지 확인하는 방법에 대한 여러 예시가 있습니다.
예시 1
이 예에서 네트워크 대기열 수는 지원되는 모든 장치에 대해 예약된 CPU 수(2)로 설정됩니다.
성능 프로필의 관련 섹션은 다음과 같습니다.
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
# ...다음 명령을 사용하여 장치와 연결된 대기열의 상태를 표시합니다.
참고성능 프로필이 적용된 노드에서 이 명령을 실행합니다.
$ ethtool -l <device>
프로필을 적용하기 전에 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 4
프로필이 적용된 후 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
- 결합된 채널은 지원되는 모든 장치에 대해 예약된 CPU의 총 수가 2임을 보여줍니다. 이는 성능 프로필에 구성된 항목과 일치합니다.
예시 2
이 예에서 네트워크 대기열 수는 특정 vendorID가 있는 지원되는 모든 네트워크 장치에 대해 예약된 CPU 수(2)로 설정됩니다.
성능 프로필의 관련 섹션은 다음과 같습니다.
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
devices:
- vendorID = 0x1af4
# ...다음 명령을 사용하여 장치와 연결된 대기열의 상태를 표시합니다.
참고성능 프로필이 적용된 노드에서 이 명령을 실행합니다.
$ ethtool -l <device>
프로필이 적용된 후 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
vendorID=0x1af4를 사용하는 지원되는 모든 장치에 대해 예약된 CPU의 총 수는 2입니다. 예를 들어vendorID=0x1af4가 있는 다른 네트워크 장치ens2가 별도로 존재하는 경우 총 네트워크 대기열 수는 2입니다. 이는 성능 프로필에 구성된 항목과 일치합니다.
예시 3
이 예에서 네트워크 대기열 수는 정의된 장치 식별자와 일치하는 지원되는 모든 네트워크 장치에 대해 예약된 CPU 수(2)로 설정됩니다.
udevadm info는 장치에 대한 자세한 보고서를 제공합니다. 이 예에서 장치는 다음과 같습니다.
# udevadm info -p /sys/class/net/ens4 ... E: ID_MODEL_ID=0x1000 E: ID_VENDOR_ID=0x1af4 E: INTERFACE=ens4 ...
# udevadm info -p /sys/class/net/eth0 ... E: ID_MODEL_ID=0x1002 E: ID_VENDOR_ID=0x1001 E: INTERFACE=eth0 ...
interfaceName이eth0인 장치 및 다음 성능 프로필이 있는vendorID=0x1af4가 있는 모든 장치에 대해 네트워크 대기열을 2로 설정합니다.apiVersion: performance.openshift.io/v2 metadata: name: performance spec: kind: PerformanceProfile spec: cpu: reserved: 0-1 #total = 2 isolated: 2-8 net: userLevelNetworking: true devices: - interfaceName = eth0 - vendorID = 0x1af4 ...프로필이 적용된 후 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1- 1
vendorID=0x1af4를 사용하는 지원되는 모든 장치에 대해 예약된 CPU의 총 개수가 2로 설정됩니다. 예를 들어vendorID=0x1af4가 있는 다른 네트워크 장치ens2가 있는 경우 총 네트워크 대기열도 2로 설정됩니다. 마찬가지로interfaceName이eth0인 장치에는 총 네트워크 대기열이 2로 설정됩니다.
11.2.9.3. NIC 대기열 조정과 관련된 로깅
할당된 장치를 자세히 설명하는 로그 메시지는 각 Tuned 데몬 로그에 기록됩니다. /var/log/tuned/tuned.log 파일에 다음 메시지가 기록될 수 있습니다.
성공적으로 할당된 장치를 자세히 설명하는
INFO메시지가 기록됩니다.INFO tuned.plugins.base: instance net_test (net): assigning devices ens1, ens2, ens3
장치를 할당할 수 없는 경우
WARNING메시지가 기록됩니다.WARNING tuned.plugins.base: instance net_test: no matching devices available
11.3. 실시간 및 짧은 대기 시간 워크로드 프로비저닝
많은 조직에서는 특히 금융 및 통신 업계에서 고성능 컴퓨팅과 낮은 예측 가능한 대기 시간이 필요합니다.
OpenShift Container Platform에서는 Node Tuning Operator에서 자동 튜닝을 구현하여 대기 시간이 짧은 성능과 OpenShift Container Platform 애플리케이션의 응답 시간을 일관되게 유지할 수 있습니다. 성능 프로필 구성을 사용하여 이러한 변경을 수행합니다. 커널을 kernel-rt로 업데이트하고, Pod 인프라 컨테이너를 포함하여 클러스터 및 운영 체제 하우스키핑 작업을 위해 CPU를 예약하고, 애플리케이션 컨테이너의 CPU를 분리하고, 사용되지 않는 CPU를 비활성화하여 전력 소비를 줄일 수 있습니다.
애플리케이션을 작성할 때 RHEL for Real Time 프로세스 및 스레드에 설명된 일반적인 권장 사항을 따르십시오.
11.3.1. 실시간 기능이 있는 작업자에 짧은 대기 시간 워크로드 예약
실시간 기능을 구성하는 성능 프로필이 적용되는 작업자 노드에 대기 시간이 짧은 워크로드를 예약할 수 있습니다.
특정 노드에 워크로드를 예약하려면 Pod CR(사용자 정의 리소스)의 라벨 선택기를 사용합니다. 라벨 선택기는 Node Tuning Operator에 의해 짧은 대기 시간을 위해 구성된 머신 구성 풀에 연결된 노드와 일치해야 합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다. - 대기 시간이 짧은 워크로드를 위해 작업자 노드를 조정하는 클러스터에 성능 프로필을 적용했습니다.
프로세스
대기 시간이 짧은 워크로드에 대한
PodCR을 생성하고 클러스터에 적용합니다. 예를 들면 다음과 같습니다.실시간 처리를 사용하도록 구성된
Pod사양의 예apiVersion: v1 kind: Pod metadata: name: dynamic-low-latency-pod annotations: cpu-quota.crio.io: "disable" 1 cpu-load-balancing.crio.io: "disable" 2 irq-load-balancing.crio.io: "disable" 3 spec: securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault containers: - name: dynamic-low-latency-pod image: "registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15" command: ["sleep", "10h"] resources: requests: cpu: 2 memory: "200M" limits: cpu: 2 memory: "200M" securityContext: allowPrivilegeEscalation: false capabilities: drop: [ALL] nodeSelector: node-role.kubernetes.io/worker-cnf: "" 4 runtimeClassName: performance-dynamic-low-latency-profile 5 # ...-
performance-<profile_name> 형식으로 Pod
runtimeClassName을 입력합니다. 여기서 <profile_name>은PerformanceProfileYAML의이름입니다. 이전 예에서이름은performance-dynamic-low-latency-profile입니다. Pod가 올바르게 실행되고 있는지 확인합니다. 상태가
running이어야 하며 올바른 cnf-worker 노드를 설정해야 합니다.$ oc get pod -o wide
예상 출력
NAME READY STATUS RESTARTS AGE IP NODE dynamic-low-latency-pod 1/1 Running 0 5h33m 10.131.0.10 cnf-worker.example.com
IRQ 동적 로드 밸런싱을 위해 구성된 Pod가 실행되는 CPU를 가져옵니다.
$ oc exec -it dynamic-low-latency-pod -- /bin/bash -c "grep Cpus_allowed_list /proc/self/status | awk '{print $2}'"예상 출력
Cpus_allowed_list: 2-3
검증
노드 구성이 올바르게 적용되었는지 확인합니다.
노드에 로그인하여 구성을 확인합니다.
$ oc debug node/<node-name>
노드 파일 시스템을 사용할 수 있는지 확인합니다.
sh-4.4# chroot /host
예상 출력
sh-4.4#
기본 시스템 CPU 선호도 마스크에
dynamic-Low-latency-podCPU(예: CPU 2 및 3)가 포함되어 있지 않은지 확인합니다.sh-4.4# cat /proc/irq/default_smp_affinity
출력 예
33
IRQ가
dynamic-low-latency-podCPU에서 실행되도록 구성되어 있지 않은지 확인합니다.sh-4.4# find /proc/irq/ -name smp_affinity_list -exec sh -c 'i="$1"; mask=$(cat $i); file=$(echo $i); echo $file: $mask' _ {} \;출력 예
/proc/irq/0/smp_affinity_list: 0-5 /proc/irq/1/smp_affinity_list: 5 /proc/irq/2/smp_affinity_list: 0-5 /proc/irq/3/smp_affinity_list: 0-5 /proc/irq/4/smp_affinity_list: 0 /proc/irq/5/smp_affinity_list: 0-5 /proc/irq/6/smp_affinity_list: 0-5 /proc/irq/7/smp_affinity_list: 0-5 /proc/irq/8/smp_affinity_list: 4 /proc/irq/9/smp_affinity_list: 4 /proc/irq/10/smp_affinity_list: 0-5 /proc/irq/11/smp_affinity_list: 0 /proc/irq/12/smp_affinity_list: 1 /proc/irq/13/smp_affinity_list: 0-5 /proc/irq/14/smp_affinity_list: 1 /proc/irq/15/smp_affinity_list: 0 /proc/irq/24/smp_affinity_list: 1 /proc/irq/25/smp_affinity_list: 1 /proc/irq/26/smp_affinity_list: 1 /proc/irq/27/smp_affinity_list: 5 /proc/irq/28/smp_affinity_list: 1 /proc/irq/29/smp_affinity_list: 0 /proc/irq/30/smp_affinity_list: 0-5
짧은 대기 시간을 위해 노드를 튜닝하면 보장된 CPU가 필요한 애플리케이션과 함께 실행 프로브를 사용하면 대기 시간이 급증할 수 있습니다. 대안으로 올바르게 구성된 네트워크 프로브 세트와 같은 다른 프로브를 사용합니다.
11.3.2. 보장된 QoS 클래스를 사용하여 Pod 생성
QoS 클래스가 Guaranteed로 지정된 Pod를 생성하는 경우 다음 사항에 유의하십시오.
- Pod의 모든 컨테이너에는 메모리 제한과 메모리 요청이 있어야 하며 동일해야 합니다.
- Pod의 모든 컨테이너에는 CPU 제한과 CPU 요청이 있어야 하며 동일해야 합니다.
다음 예에서는 컨테이너가 하나인 Pod의 구성 파일을 보여줍니다. 이 컨테이너에는 메모리 제한과 메모리 요청이 있으며 둘 다 200MiB입니다. 이 컨테이너에는 CPU 제한과 CPU 요청이 있으며 둘 다 CPU 1개입니다.
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
containers:
- name: qos-demo-ctr
image: <image-pull-spec>
resources:
limits:
memory: "200Mi"
cpu: "1"
requests:
memory: "200Mi"
cpu: "1"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]Pod를 생성합니다.
$ oc apply -f qos-pod.yaml --namespace=qos-example
Pod에 대한 자세한 정보를 봅니다.
$ oc get pod qos-demo --namespace=qos-example --output=yaml
출력 예
spec: containers: ... status: qosClass: Guaranteed참고컨테이너에 메모리 제한을 지정하고 메모리 요청을 지정하지 않으면 OpenShift Container Platform에서 제한과 일치하는 메모리 요청을 자동으로 할당합니다. 마찬가지로 컨테이너의 CPU 제한을 지정하고 CPU 요청을 지정하지 않으면 OpenShift Container Platform에서 제한과 일치하는 CPU 요청을 자동으로 할당합니다.
11.3.3. Pod에서 CPU 로드 밸런싱 비활성화
CPU 부하 분산을 비활성화하거나 활성화하는 기능은 CRI-O 수준에서 구현됩니다. CRI-O 아래의 코드는 다음 요구사항이 충족되는 경우에만 CPU 부하 분산을 비활성화하거나 활성화합니다.
Pod는
performance-<profile-name>런타임 클래스를 사용해야 합니다. 다음과 같이 성능 프로필의 상태를 보고 적절한 이름을 가져올 수 있습니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile ... status: ... runtimeClass: performance-manual
현재 cgroup v2에서는 CPU 부하 분산 비활성화가 지원되지 않습니다.
Node Tuning Operator는 관련 노드 아래에 고성능 런타임 처리기 구성 스니펫을 생성하고 클러스터 아래에 고성능 런타임 클래스를 생성합니다. CPU 부하 분산 구성 기능을 활성화하는 것을 제외하고는 기본 런타임 처리기와 동일한 콘텐츠가 있습니다.
Pod에 대해 CPU 부하 분산을 비활성화하려면 Pod 사양에 다음 필드가 포함되어야 합니다.
apiVersion: v1
kind: Pod
metadata:
#...
annotations:
#...
cpu-load-balancing.crio.io: "disable"
#...
#...
spec:
#...
runtimeClassName: performance-<profile_name>
#...CPU 관리자 static 정책이 활성화되어 있는 경우 전체 CPU를 사용하는 guaranteed QoS가 있는 Pod에 대해서만 CPU 부하 분산을 비활성화하십시오. 그렇지 않은 경우 CPU 부하 분산을 비활성화하면 클러스터에 있는 다른 컨테이너의 성능에 영향을 미칠 수 있습니다.
11.3.4. 우선순위가 높은 Pod의 전원 저장 모드 비활성화
워크로드가 실행되는 노드에 대한 절전을 구성할 때 우선 순위가 높은 워크로드가 영향을 받지 않도록 Pod를 구성할 수 있습니다.
절전 구성으로 노드를 구성할 때 Pod 수준에서 성능 구성으로 높은 우선 순위 워크로드를 구성해야 합니다. 즉, 구성이 Pod에서 사용하는 모든 코어에 적용됩니다.
Pod 수준에서 P-state 및 C-state를 비활성화하면 최상의 성능과 짧은 대기 시간을 위해 높은 우선 순위의 워크로드를 구성할 수 있습니다.
표 11.4. 우선 순위가 높은 워크로드 구성
| 주석 | 가능한 값 | 설명 |
|---|---|---|
|
|
|
이 주석을 사용하면 각 CPU에 대해 C-state를 활성화하거나 비활성화할 수 있습니다. 또는 C 상태에 대해 최대 대기 시간을 microseconds로 지정할 수도 있습니다. 예를 들어 |
|
|
지원되는 모든 |
각 CPU에 |
사전 요구 사항
- 우선 순위가 높은 워크로드 Pod가 예약된 노드의 성능 프로필에 절전을 구성했습니다.
프로세스
우선순위가 높은 워크로드 Pod에 필요한 주석을 추가합니다. 주석은
기본설정을 재정의합니다.우선순위가 높은 워크로드 주석의 예
apiVersion: v1 kind: Pod metadata: #... annotations: #... cpu-c-states.crio.io: "disable" cpu-freq-governor.crio.io: "performance" #... #... spec: #... runtimeClassName: performance-<profile_name> #...- Pod를 다시 시작하여 주석을 적용합니다.
11.3.5. CPU CFS 할당량 비활성화
고정 Pod의 CPU 제한을 제거하려면 cpu-quota.crio.io: "disable" 주석이 있는 Pod를 생성합니다. 이 주석은 Pod가 실행될 때 CPU를 완전히 공정 스케줄러(CFS) 할당량을 비활성화합니다.
cpu-quota.crio.io 가 비활성화된 Pod 사양의 예
apiVersion: v1
kind: Pod
metadata:
annotations:
cpu-quota.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
#...
CPU 관리자 정적 정책이 활성화된 경우 CPU CFS 할당량과 전체 CPU를 사용하는 보장된 QoS가 있는 Pod에만 CPU CFS 할당량을 비활성화합니다. 예를 들어 CPU 고정 컨테이너가 포함된 Pod입니다. 그렇지 않으면 CPU CFS 할당량을 비활성화하면 클러스터의 다른 컨테이너 성능에 영향을 미칠 수 있습니다.
추가 리소스
11.3.6. 고정된 컨테이너가 실행 중인 CPU에 대한 인터럽트 처리 비활성화
워크로드의 대기 시간을 단축하기 위해 일부 컨테이너에서는 장치 인터럽트를 처리하지 않도록 고정된 CPU가 필요합니다. pod 주석 irq-load-balancing.crio.io 는 고정된 컨테이너가 실행 중인 CPU에서 장치 인터럽트가 처리되었는지 여부를 정의하는 데 사용됩니다. CRI-O를 설정하면 Pod 컨테이너가 실행 중인 장치 인터럽트를 비활성화합니다.
개별 Pod에 속하는 컨테이너가 고정된 CPU의 인터럽트 처리를 비활성화하려면 성능 프로필에서 globallyDisableIrqLoadBalancing 이 false 로 설정되어 있는지 확인합니다. 그런 다음 Pod 사양에서 irq-load-balancing.crio.io Pod 주석을 비활성화하도록 설정합니다.
다음 Pod 사양에는 이 주석이 포함되어 있습니다.
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
irq-load-balancing.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...추가 리소스
11.4. 짧은 대기 시간 노드 튜닝 상태 디버깅
PerformanceProfile CR(사용자 정의 리소스) 상태 필드를 사용하여 튜닝 상태를 보고하고 클러스터 노드에서 대기 시간 문제를 디버깅합니다.
11.4.1. 짧은 대기 시간 CNF 튜닝 상태 디버깅
PerformanceProfile CR(사용자 정의 리소스)에는 튜닝 상태를 보고하고 대기 시간 성능 저하 문제를 디버깅하기 위한 상태 필드가 있습니다. 이러한 필드는 상태를 보고하여 Operator 조정 기능의 상태에 대해 설명합니다.
일반적으로 성능 프로필에 연결된 머신 구성 풀의 상태가 성능 저하 상태이면 PerformanceProfile이 성능 저하 상태가 되는 문제가 발생할 수 있습니다. 이 경우 머신 구성 풀에서 실패 메시지를 발행합니다.
Node Tuning Operator에는 performanceProfile.spec.status.Conditions 상태 필드가 포함되어 있습니다.
Status:
Conditions:
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Available
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Upgradeable
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Progressing
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Degraded
Status 필드에는 성능 프로필의 상태를 나타내는 Type 값을 지정하는 Conditions가 포함되어 있습니다.
Available- 모든 머신 구성 및 Tuned 프로필이 성공적으로 생성되었으며 구성 요소에서 처리해야 하는 클러스터에 사용할 수 있습니다(NTO, MCO, Kubelet).
Upgradeable- Operator에서 유지보수하는 리소스가 업그레이드하기에 안전한 상태인지를 나타냅니다.
Progressing- 성능 프로필의 배포 프로세스가 시작되었음을 나타냅니다.
Degraded다음과 같은 경우 오류를 표시합니다.
- 성능 프로필 검증에 실패했습니다.
- 모든 관련 구성 요소 생성이 성공적으로 완료되지 않았습니다.
이러한 각 유형에는 다음 필드가 포함되어 있습니다.
상태-
특정 유형의 상태(
true또는false)입니다. Timestamp- 트랜잭션 타임스탬프입니다.
Reason string- 머신에서 읽을 수 있는 이유입니다.
Message string- 상태 및 오류 세부 정보(있는 경우)를 설명하는 사람이 읽을 수 있는 이유입니다.
11.4.1.1. 머신 구성 풀
성능 프로필 및 생성된 제품은 연관 MCP(머신 구성 풀)에 따라 노드에 적용됩니다. MCP에는 rt-kernel의 커널 인수, kube 구성, 대규모 페이지 할당 및 배포를 포함하는 성능 프로필로 생성된 머신 구성 적용 진행에 대한 중요한 정보가 있습니다. Performance Profile 컨트롤러는 MCP의 변경 사항을 모니터링하고 그에 따라 성능 프로필 상태를 업데이트합니다.
MCP가 성능 프로필 상태로 반환하는 유일한 조건은 MCP가 Degraded 인 경우이며, 이로 인해 performanceProfile.status.condition.Degraded = true 입니다.
예제
다음은 생성된 연관 머신 구성 풀(worker-cnf)이 있는 성능 프로필의 예입니다.
연관 머신 구성 풀이 성능 저하 상태입니다.
# oc get mcp
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-2ee57a93fa6c9181b546ca46e1571d2d True False False 3 3 3 0 2d21h worker rendered-worker-d6b2bdc07d9f5a59a6b68950acf25e5f True False False 2 2 2 0 2d21h worker-cnf rendered-worker-cnf-6c838641b8a08fff08dbd8b02fb63f7c False True True 2 1 1 1 2d20h
MCP의
describe섹션은 이유를 보여줍니다.# oc describe mcp worker-cnf
출력 예
Message: Node node-worker-cnf is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found" Reason: 1 nodes are reporting degraded status on syncdegraded = true로 표시된 성능 프로필status필드 아래에도 성능 저하 상태가 표시되어야 합니다.# oc describe performanceprofiles performance
출력 예
Message: Machine config pool worker-cnf Degraded Reason: 1 nodes are reporting degraded status on sync. Machine config pool worker-cnf Degraded Message: Node yquinn-q8s5v-w-b-z5lqn.c.openshift-gce-devel.internal is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found". Reason: MCPDegraded Status: True Type: Degraded
11.4.2. Red Hat 지원을 받기 위한 짧은 대기 시간 튜닝 디버깅 데이터 수집
지원 사례를 여는 경우 클러스터에 대한 디버깅 정보를 Red Hat 지원에 제공하면 도움이 됩니다.
must-gather 툴을 사용하면 노드 튜닝과 NUMA 토폴로지, 짧은 대기 시간 설정으로 인한 문제를 디버깅하는 데 필요한 다른 정보를 비롯하여 OpenShift Container Platform 클러스터에 대한 진단 정보를 수집할 수 있습니다.
즉각 지원을 받을 수 있도록 OpenShift Container Platform 및 짧은 대기 시간 튜닝 둘 다에 대한 진단 정보를 제공하십시오.
11.4.2.1. must-gather 툴 정보
oc adm must-gather CLI 명령은 다음과 같이 문제를 디버깅하는 데 필요할 가능성이 높은 클러스터 정보를 수집합니다.
- 리소스 정의
- 감사 로그
- 서비스 로그
--image 인수를 포함하여 명령을 실행하는 경우 이미지를 하나 이상 지정할 수 있습니다. 이미지를 지정하면 툴에서 해당 기능 또는 제품과 관련된 데이터를 수집합니다. oc adm must-gather를 실행하면 클러스터에 새 Pod가 생성됩니다. 해당 Pod에 대한 데이터가 수집되어 must-gather.local로 시작하는 새 디렉터리에 저장됩니다. 이 디렉터리는 현재 작업 디렉터리에 생성됩니다.
11.4.2.2. 짧은 대기 시간 튜닝 데이터 수집
oc adm must-gather CLI 명령을 사용하여 다음과 같은 짧은 대기 시간 튜닝과 연관된 기능 및 오브젝트를 포함한 클러스터 정보를 수집합니다.
- Node Tuning Operator 네임스페이스 및 하위 오브젝트입니다.
-
MachineConfigPool및 연관MachineConfig오브젝트. - Node Tuning Operator 및 연관 Tuned 오브젝트.
- Linux 커널 명령줄 옵션.
- CPU 및 NUMA 토폴로지.
- 기본 PCI 장치 정보 및 NUMA 위치.
사전 요구 사항
-
cluster-admin역할을 가진 사용자로 클러스터에 액세스합니다. - OpenShift Container Platform CLI(oc)가 설치되어 있어야 합니다.
프로세스
-
must-gather데이터를 저장하려는 디렉터리로 이동합니다. 다음 명령을 실행하여 디버깅 정보를 수집합니다.
$ oc adm must-gather
출력 예
[must-gather ] OUT Using must-gather plug-in image: quay.io/openshift-release When opening a support case, bugzilla, or issue please include the following summary data along with any other requested information: ClusterID: 829er0fa-1ad8-4e59-a46e-2644921b7eb6 ClusterVersion: Stable at "<cluster_version>" ClusterOperators: All healthy and stable [must-gather ] OUT namespace/openshift-must-gather-8fh4x created [must-gather ] OUT clusterrolebinding.rbac.authorization.k8s.io/must-gather-rhlgc created [must-gather-5564g] POD 2023-07-17T10:17:37.610340849Z Gathering data for ns/openshift-cluster-version... [must-gather-5564g] POD 2023-07-17T10:17:38.786591298Z Gathering data for ns/default... [must-gather-5564g] POD 2023-07-17T10:17:39.117418660Z Gathering data for ns/openshift... [must-gather-5564g] POD 2023-07-17T10:17:39.447592859Z Gathering data for ns/kube-system... [must-gather-5564g] POD 2023-07-17T10:17:39.803381143Z Gathering data for ns/openshift-etcd... ... Reprinting Cluster State: When opening a support case, bugzilla, or issue please include the following summary data along with any other requested information: ClusterID: 829er0fa-1ad8-4e59-a46e-2644921b7eb6 ClusterVersion: Stable at "<cluster_version>" ClusterOperators: All healthy and stable
작업 디렉터리에 생성된
must-gather디렉터리의 압축 파일을 생성합니다. 예를 들어 Linux 운영 체제를 사용하는 컴퓨터에서 다음 명령을 실행합니다.$ tar cvaf must-gather.tar.gz must-gather-local.54213423446277122891- 1
must-gather-local.5421342344627712289//를must-gather툴에서 생성한 디렉터리 이름으로 교체합니다.
참고데이터를 지원 케이스에 첨부하거나 성능 프로파일을 생성할 때 Performance Profile Creator 래퍼 스크립트와 함께 사용할 압축 파일을 만듭니다.
- Red Hat Customer Portal에서 해당 지원 사례에 압축 파일을 첨부합니다.
11.5. 플랫폼 확인을 위한 대기 시간 테스트 수행
CNF(클라우드 네이티브 네트워크 기능) 테스트 이미지를 사용하여 CNF 워크로드 실행에 필요한 모든 구성 요소가 설치된 CNF 지원 OpenShift Container Platform 클러스터에서 대기 시간 테스트를 실행할 수 있습니다. 대기 시간 테스트를 실행하여 워크로드에 대한 노드 튜닝의 유효성을 검사합니다.
cnf-tests 컨테이너 이미지는 registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 에서 사용할 수 있습니다.
11.5.1. 대기 시간 테스트 실행을 위한 사전 요구 사항
대기 시간 테스트를 실행하려면 클러스터가 다음 요구 사항을 충족해야 합니다.
- Node Tuning Operator를 사용하여 성능 프로필을 구성했습니다.
- 클러스터에서 필요한 모든 CNF 구성을 적용했습니다.
-
클러스터에 기존
MachineConfigPoolCR이 적용되어 있습니다. 기본 작업자 풀은worker-cnf입니다.
추가 리소스
11.5.2. 대기 시간 측정
cnf-tests 이미지는 세 가지 툴을 사용하여 시스템의 대기 시간을 측정합니다.
-
hwlatdetect -
cyclictest -
oslat
각 툴에는 특정 용도가 있습니다. 안정적인 테스트 결과를 얻으려면 도구를 순서대로 사용하십시오.
- hwlatdetect
-
베어 메탈 하드웨어에서 수행할 수 있는 기준을 측정합니다. 다음 대기 시간 테스트를 진행하기 전에
hwlatdetect에서 보고한 대기 시간이 운영 체제 튜닝을 통해 하드웨어 대기 시간 급증을 수정할 수 없기 때문에 필요한 임계값을 충족하는지 확인합니다. - cyclictest
-
hwlatdetect가 검증을 통과한 후 실시간 커널 스케줄러 대기 시간을 확인합니다.cyclictest툴은 반복된 타이머를 스케줄링하고 원하는 트리거 시간과 실제 트리거 시간 간의 차이를 측정합니다. 차이점은 인터럽트 또는 프로세스 우선순위로 인한 튜닝의 기본 문제를 찾을 수 있습니다. 툴은 실시간 커널에서 실행해야 합니다. - oslat
- CPU 집약적인 DPDK 애플리케이션과 유사하게 작동하며 CPU 과도한 데이터 처리를 시뮬레이션하는 사용량이 많은 루프에 대한 모든 중단 및 중단을 측정합니다.
테스트에서는 다음과 같은 환경 변수를 도입합니다.
표 11.5. 대기 시간 테스트 환경 변수
| 환경 변수 | 설명 |
|---|---|
|
| 테스트 실행을 시작한 후 시간(초)을 지정합니다. 변수를 사용하여 CPU 관리자 조정 루프가 기본 CPU 풀을 업데이트할 수 있도록 허용할 수 있습니다. 기본값은 0입니다. |
|
| 대기 시간 테스트를 실행하는 Pod에서 사용하는 CPU 수를 지정합니다. 변수를 설정하지 않으면 기본 구성에 모든 분리된 CPU가 포함됩니다. |
|
| 대기 시간 테스트를 실행해야 하는 시간(초)을 지정합니다. 기본값은 300초입니다. 참고
대기 시간 테스트가 완료되기 전에 Ginkgo 2.0 테스트 모음이 시간 초과되지 않도록 하려면 |
|
|
워크로드 및 운영 체제에 대해 마이크로초 단위로 허용되는 최대 하드웨어 대기 시간을 지정합니다. |
|
|
|
|
|
|
|
| 마이크로초 단위로 허용되는 최대 대기 시간을 지정하는 통합 변수입니다. 사용 가능한 모든 대기 시간 툴에 적용됩니다. |
대기 시간 툴과 관련된 변수가 통합 변수보다 우선합니다. 예를 들어 OSLAT_MAXIMUM_LATENCY 가 30 마이크로초로 설정되고 MAXIMUM_LATENCY 가 10 마이크로초로 설정된 경우 oslat 테스트는 최대 허용 가능한 대기 시간으로 30 마이크로초의 최대 허용 대기 시간으로 실행됩니다.
11.5.3. 대기 시간 테스트 실행
클러스터 대기 시간 테스트를 실행하여 CNF(클라우드 네이티브 네트워크 기능) 워크로드에 대한 노드 튜닝을 검증합니다.
root가 아니거나 권한이 없는 사용자로 podman 명령을 실행하는 경우 마운트 경로가 권한 거부 오류로 인해 실패할 수 있습니다. podman 명령이 작동하도록 하려면 볼륨 생성에 :Z 를 추가합니다(예: -v $(pwd)/:/kubeconfig:Z. 이렇게 하면 podman 에서 적절한 SELinux 레이블을 다시 지정할 수 있습니다.
프로세스
kubeconfig파일이 포함된 디렉터리에서 쉘 프롬프트를 엽니다.현재 디렉터리에
kubeconfig파일과 볼륨을 통해 마운트된 관련$KUBECONFIG환경 변수가 테스트 이미지를 제공합니다. 이렇게 하면 실행 중인 컨테이너에서 컨테이너 내부에서kubeconfig파일을 사용할 수 있습니다.다음 명령을 입력하여 대기 시간 테스트를 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds>\ -e MAXIMUM_LATENCY=<time_in_microseconds> \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh \ --ginkgo.v --ginkgo.timeout="24h"
-
선택 사항: Append
--ginkgo.dryRun플래그는 시험 실행 모드에서 대기 시간 테스트를 실행합니다. 이 기능은 테스트가 실행되는 명령을 확인하는 데 유용합니다. -
선택 사항: Append
--ginkgo.v플래그는 상세 정보 표시가 증가하여 테스트를 실행합니다. 선택 사항: 대기 시간 테스트가 완료되기 전에 Ginkgo 2.0 테스트 모음이 시간 초과되지 않도록 하려면 Append
--ginkgo.timeout="24h"플래그가 있습니다.중요각 테스트의 기본 런타임은 300초입니다. 유효한 대기 시간 테스트 결과의 경우
LATENCY_TEST_RUNTIME변수를 업데이트하여 최소 12시간 동안 테스트를 실행합니다.
11.5.3.1. hwlatdetect 실행
hwlatdetect 툴은 RHEL(Red Hat Enterprise Linux) 9.x의 일반 서브스크립션과 함께 rt-kernel 패키지에서 사용할 수 있습니다.
root가 아니거나 권한이 없는 사용자로 podman 명령을 실행하는 경우 마운트 경로가 권한 거부 오류로 인해 실패할 수 있습니다. podman 명령이 작동하도록 하려면 볼륨 생성에 :Z 를 추가합니다(예: -v $(pwd)/:/kubeconfig:Z. 이렇게 하면 podman 에서 적절한 SELinux 레이블을 다시 지정할 수 있습니다.
사전 요구 사항
- 클러스터에 실시간 커널이 설치되어 있습니다.
-
고객 포털 인증 정보를 사용하여
registry.redhat.io에 로그인했습니다.
프로세스
hwlatdetect테스트를 실행하려면 다음 명령을 실행하여 변수 값을 적절하게 대체합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="hwlatdetect" --ginkgo.v --ginkgo.timeout="24h"
hwlatdetect테스트는 10분(600초) 동안 실행됩니다. 관찰된 최대 대기 시간이MAXIMUM_LATENCY(20 Cryostat)보다 작으면 테스트가 성공적으로 실행됩니다.결과가 대기 시간 임계값을 초과하면 테스트가 실패합니다.
중요유효한 결과를 위해 테스트는 최소 12시간 동안 실행되어야 합니다.
실패 출력 예
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=hwlatdetect I0908 15:25:20.023712 27 request.go:601] Waited for 1.046586367s due to client-side throttling, not priority and fairness, request: GET:https://api.hlxcl6.lab.eng.tlv2.redhat.com:6443/apis/imageregistry.operator.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662650718 Will run 1 of 3 specs [...] • Failure [283.574 seconds] [performance] Latency Test /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:62 with the hwlatdetect image /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:228 should succeed [It] /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:236 Log file created at: 2022/09/08 15:25:27 Running on machine: hwlatdetect-b6n4n Binary: Built with gc go1.17.12 for linux/amd64 Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg I0908 15:25:27.160620 1 node.go:39] Environment information: /proc/cmdline: BOOT_IMAGE=(hd1,gpt3)/ostree/rhcos-c6491e1eedf6c1f12ef7b95e14ee720bf48359750ac900b7863c625769ef5fb9/vmlinuz-4.18.0-372.19.1.el8_6.x86_64 random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ignition.platform.id=metal ostree=/ostree/boot.1/rhcos/c6491e1eedf6c1f12ef7b95e14ee720bf48359750ac900b7863c625769ef5fb9/0 ip=dhcp root=UUID=5f80c283-f6e6-4a27-9b47-a287157483b2 rw rootflags=prjquota boot=UUID=773bf59a-bafd-48fc-9a87-f62252d739d3 skew_tick=1 nohz=on rcu_nocbs=0-3 tuned.non_isolcpus=0000ffff,ffffffff,fffffff0 systemd.cpu_affinity=4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79 intel_iommu=on iommu=pt isolcpus=managed_irq,0-3 nohz_full=0-3 tsc=nowatchdog nosoftlockup nmi_watchdog=0 mce=off skew_tick=1 rcutree.kthread_prio=11 + + I0908 15:25:27.160830 1 node.go:46] Environment information: kernel version 4.18.0-372.19.1.el8_6.x86_64 I0908 15:25:27.160857 1 main.go:50] running the hwlatdetect command with arguments [/usr/bin/hwlatdetect --threshold 1 --hardlimit 1 --duration 100 --window 10000000us --width 950000us] F0908 15:27:10.603523 1 main.go:53] failed to run hwlatdetect command; out: hwlatdetect: test duration 100 seconds detector: tracer parameters: Latency threshold: 1us 1 Sample window: 10000000us Sample width: 950000us Non-sampling period: 9050000us Output File: None Starting test test finished Max Latency: 326us 2 Samples recorded: 5 Samples exceeding threshold: 5 ts: 1662650739.017274507, inner:6, outer:6 ts: 1662650749.257272414, inner:14, outer:326 ts: 1662650779.977272835, inner:314, outer:12 ts: 1662650800.457272384, inner:3, outer:9 ts: 1662650810.697273520, inner:3, outer:2 [...] JUnit report was created: /junit.xml/cnftests-junit.xml Summarizing 1 Failure: [Fail] [performance] Latency Test with the hwlatdetect image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:476 Ran 1 of 194 Specs in 365.797 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 2 Skipped --- FAIL: TestTest (366.08s) FAIL
hwlatdetect 테스트 결과 예
다음 유형의 결과를 캡처할 수 있습니다.
- 테스트 전체에서 수행된 변경 사항에 영향을 미치는 기록을 생성하기 위해 각 실행 후에 수집된 대략적인 결과.
- 최상의 결과 및 구성 설정과 함께 대략적인 테스트 세트입니다.
좋은 결과의 예
hwlatdetect: test duration 3600 seconds detector: tracer parameters: Latency threshold: 10us Sample window: 1000000us Sample width: 950000us Non-sampling period: 50000us Output File: None Starting test test finished Max Latency: Below threshold Samples recorded: 0
hwlatdetect 툴은 샘플이 지정된 임계값을 초과하는 경우에만 출력을 제공합니다.
잘못된 결과의 예
hwlatdetect: test duration 3600 seconds detector: tracer parameters:Latency threshold: 10usSample window: 1000000us Sample width: 950000usNon-sampling period: 50000usOutput File: None Starting tests:1610542421.275784439, inner:78, outer:81 ts: 1610542444.330561619, inner:27, outer:28 ts: 1610542445.332549975, inner:39, outer:38 ts: 1610542541.568546097, inner:47, outer:32 ts: 1610542590.681548531, inner:13, outer:17 ts: 1610543033.818801482, inner:29, outer:30 ts: 1610543080.938801990, inner:90, outer:76 ts: 1610543129.065549639, inner:28, outer:39 ts: 1610543474.859552115, inner:28, outer:35 ts: 1610543523.973856571, inner:52, outer:49 ts: 1610543572.089799738, inner:27, outer:30 ts: 1610543573.091550771, inner:34, outer:28 ts: 1610543574.093555202, inner:116, outer:63
hwlatdetect 의 출력은 여러 샘플이 임계값을 초과했음을 보여줍니다. 그러나 동일한 출력은 다음 요인에 따라 다른 결과를 나타낼 수 있습니다.
- 테스트 기간
- CPU 코어 수
- 호스트 펌웨어 설정
다음 대기 시간 테스트를 진행하기 전에 hwlatdetect 에서 보고한 대기 시간이 필요한 임계값을 충족하는지 확인합니다. 하드웨어에 의해 도입된 대기 시간을 수정하려면 시스템 벤더 지원에 문의해야 할 수 있습니다.
모든 대기 시간 급증이 하드웨어와 관련된 것은 아닙니다. 워크로드 요구 사항을 충족하도록 호스트 펌웨어를 조정해야 합니다. 자세한 내용은 시스템 튜닝의 펌웨어 매개변수 설정을 참조하십시오.
11.5.3.2. cyclictest 실행
cyclictest 툴은 지정된 CPU에서 실시간 커널 스케줄러 대기 시간을 측정합니다.
root가 아니거나 권한이 없는 사용자로 podman 명령을 실행하는 경우 마운트 경로가 권한 거부 오류로 인해 실패할 수 있습니다. podman 명령이 작동하도록 하려면 볼륨 생성에 :Z 를 추가합니다(예: -v $(pwd)/:/kubeconfig:Z. 이렇게 하면 podman 에서 적절한 SELinux 레이블을 다시 지정할 수 있습니다.
사전 요구 사항
-
고객 포털 인증 정보를 사용하여
registry.redhat.io에 로그인했습니다. - 클러스터에 실시간 커널이 설치되어 있습니다.
- Node Tuning Operator를 사용하여 클러스터 성능 프로필을 적용했습니다.
프로세스
cyclictest를 수행하려면 다음 명령을 실행하여 변수 값을 적절하게 대체합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="cyclictest" --ginkgo.v --ginkgo.timeout="24h"
명령은 10분(600초) 동안
cyclictest툴을 실행합니다. 관찰된 최대 대기 시간이MAXIMUM_LATENCY보다 작으면 테스트가 성공적으로 실행됩니다(이 예에서는 20 Cryostat). 20 Cryostat 이상으로 급증하는 대기 시간은 일반적으로 telco RAN 워크로드에는 허용되지 않습니다.결과가 대기 시간 임계값을 초과하면 테스트가 실패합니다.
중요유효한 결과를 위해 테스트는 최소 12시간 동안 실행되어야 합니다.
실패 출력 예
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=cyclictest I0908 13:01:59.193776 27 request.go:601] Waited for 1.046228824s due to client-side throttling, not priority and fairness, request: GET:https://api.compute-1.example.com:6443/apis/packages.operators.coreos.com/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662642118 Will run 1 of 3 specs [...] Summarizing 1 Failure: [Fail] [performance] Latency Test with the cyclictest image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:220 Ran 1 of 194 Specs in 161.151 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 2 Skipped --- FAIL: TestTest (161.48s) FAIL
cyclictest 결과 예
동일한 출력은 워크로드마다 다른 결과를 나타낼 수 있습니다. 예를 들어 4G DU 워크로드에는 최대 18 Cryostats의 급증이 허용되지만 5G DU 워크로드에서는 허용되지 않습니다.
좋은 결과의 예
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m # Histogram 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000002 579506 535967 418614 573648 532870 529897 489306 558076 582350 585188 583793 223781 532480 569130 472250 576043 More histogram entries ... # Total: 000600000 000600000 000600000 000599999 000599999 000599999 000599998 000599998 000599998 000599997 000599997 000599996 000599996 000599995 000599995 000599995 # Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Max Latencies: 00005 00005 00004 00005 00004 00004 00005 00005 00006 00005 00004 00005 00004 00004 00005 00004 # Histogram Overflows: 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 # Histogram Overflow at cycle number: # Thread 0: # Thread 1: # Thread 2: # Thread 3: # Thread 4: # Thread 5: # Thread 6: # Thread 7: # Thread 8: # Thread 9: # Thread 10: # Thread 11: # Thread 12: # Thread 13: # Thread 14: # Thread 15:
잘못된 결과의 예
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m # Histogram 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000002 564632 579686 354911 563036 492543 521983 515884 378266 592621 463547 482764 591976 590409 588145 589556 353518 More histogram entries ... # Total: 000599999 000599999 000599999 000599997 000599997 000599998 000599998 000599997 000599997 000599996 000599995 000599996 000599995 000599995 000599995 000599993 # Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Max Latencies: 00493 00387 00271 00619 00541 00513 00009 00389 00252 00215 00539 00498 00363 00204 00068 00520 # Histogram Overflows: 00001 00001 00001 00002 00002 00001 00000 00001 00001 00001 00002 00001 00001 00001 00001 00002 # Histogram Overflow at cycle number: # Thread 0: 155922 # Thread 1: 110064 # Thread 2: 110064 # Thread 3: 110063 155921 # Thread 4: 110063 155921 # Thread 5: 155920 # Thread 6: # Thread 7: 110062 # Thread 8: 110062 # Thread 9: 155919 # Thread 10: 110061 155919 # Thread 11: 155918 # Thread 12: 155918 # Thread 13: 110060 # Thread 14: 110060 # Thread 15: 110059 155917
11.5.3.3. oslat 실행
oslat 테스트는 CPU 집약적인 DPDK 애플리케이션을 시뮬레이션하고 모든 중단 및 중단을 측정하여 클러스터가 CPU 과도한 데이터 처리를 처리하는 방법을 테스트합니다.
root가 아니거나 권한이 없는 사용자로 podman 명령을 실행하는 경우 마운트 경로가 권한 거부 오류로 인해 실패할 수 있습니다. podman 명령이 작동하도록 하려면 볼륨 생성에 :Z 를 추가합니다(예: -v $(pwd)/:/kubeconfig:Z. 이렇게 하면 podman 에서 적절한 SELinux 레이블을 다시 지정할 수 있습니다.
사전 요구 사항
-
고객 포털 인증 정보를 사용하여
registry.redhat.io에 로그인했습니다. - Node Tuning Operator를 사용하여 클러스터 성능 프로필을 적용했습니다.
프로세스
oslat테스트를 수행하려면 다음 명령을 실행하여 변수 값을 적절하게 대체합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.focus="oslat" --ginkgo.v --ginkgo.timeout="24h"
LATENCY_TEST_CPUS는oslat명령으로 테스트할 CPU 수를 지정합니다.명령은 10분(600초) 동안
oslat툴을 실행합니다. 관찰된 최대 대기 시간이MAXIMUM_LATENCY(20 Cryostat)보다 작으면 테스트가 성공적으로 실행됩니다.결과가 대기 시간 임계값을 초과하면 테스트가 실패합니다.
중요유효한 결과를 위해 테스트는 최소 12시간 동안 실행되어야 합니다.
실패 출력 예
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=oslat I0908 12:51:55.999393 27 request.go:601] Waited for 1.044848101s due to client-side throttling, not priority and fairness, request: GET:https://compute-1.example.com:6443/apis/machineconfiguration.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662641514 Will run 1 of 3 specs [...] • Failure [77.833 seconds] [performance] Latency Test /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:62 with the oslat image /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:128 should succeed [It] /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:153 The current latency 304 is bigger than the expected one 1 : 1 [...] Summarizing 1 Failure: [Fail] [performance] Latency Test with the oslat image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:177 Ran 1 of 194 Specs in 161.091 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 2 Skipped --- FAIL: TestTest (161.42s) FAIL- 1
- 이 예에서 측정된 대기 시간은 허용되는 최대값을 벗어납니다.
11.5.4. 대기 시간 테스트 실패 보고서 생성
다음 절차를 사용하여 JUnit 대기 시간 테스트 출력 및 테스트 실패 보고서를 생성합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다.
프로세스
--report매개변수를 보고서가 덤프되는 위치에 경로를 전달하여 문제 해결을 위한 클러스터 상태 및 리소스에 대한 정보를 사용하여 테스트 실패 보고서를 생성합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/reportdest:<report_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --report <report_folder_path> --ginkgo.v
다음과 같습니다.
- <report_folder_path>
- 보고서가 생성되는 폴더의 경로입니다.Is the path to the folder where the report is generated.
11.5.5. JUnit 대기 시간 테스트 보고서 생성
다음 절차를 사용하여 JUnit 대기 시간 테스트 출력 및 테스트 실패 보고서를 생성합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다.
프로세스
--junit매개변수를 보고서가 덤프되는 위치와 함께 전달하여 JUnit 호환 XML 보고서를 생성합니다.참고이 명령을 실행하기 전에
junit폴더를 생성해야 합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/junit:/junit \ -e KUBECONFIG=/kubeconfig/kubeconfig registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.junit-report junit/<file-name>.xml --ginkgo.v
다음과 같습니다.
JUnit- junit 보고서가 저장되는 폴더입니다.
11.5.6. 단일 노드 OpenShift 클러스터에서 대기 시간 테스트 실행
단일 노드 OpenShift 클러스터에서 대기 시간 테스트를 실행할 수 있습니다.
root가 아니거나 권한이 없는 사용자로 podman 명령을 실행하는 경우 마운트 경로가 권한 거부 오류로 인해 실패할 수 있습니다. podman 명령이 작동하도록 하려면 볼륨 생성에 :Z 를 추가합니다(예: -v $(pwd)/:/kubeconfig:Z. 이렇게 하면 podman 에서 적절한 SELinux 레이블을 다시 지정할 수 있습니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다. - Node Tuning Operator를 사용하여 클러스터 성능 프로필을 적용했습니다.
프로세스
단일 노드 OpenShift 클러스터에서 대기 시간 테스트를 실행하려면 다음 명령을 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
참고각 테스트의 기본 런타임은 300초입니다. 유효한 대기 시간 테스트 결과의 경우
LATENCY_TEST_RUNTIME변수를 업데이트하여 최소 12시간 동안 테스트를 실행합니다. 버킷 대기 시간 검증 단계를 실행하려면 최대 대기 시간을 지정해야 합니다. 최대 대기 시간 변수에 대한 자세한 내용은 "레이턴 시간 측정" 섹션의 표를 참조하십시오.테스트 모음을 실행한 후에는 모든 무위 리소스가 정리됩니다.
11.5.7. 연결이 끊긴 클러스터에서 대기 시간 테스트 실행
CNF 테스트 이미지는 외부 레지스트리에 연결할 수 없는 연결이 끊긴 클러스터에서 테스트를 실행할 수 있습니다. 여기에는 다음 두 단계가 필요합니다.
-
cnf-tests이미지를 사용자 정의 연결이 끊긴 레지스트리에 미러링합니다. - 사용자 정의 연결이 끊긴 레지스트리의 이미지를 사용하도록 테스트에 지시합니다.
클러스터에서 액세스할 수 있는 사용자 정의 레지스트리로 이미지 미러링
oc 에서 테스트 이미지를 로컬 레지스트리에 미러링 하는 데 필요한 입력을 제공하기 위해 이미지에 미러 실행 파일이 제공됩니다.
클러스터 및 registry.redhat.io 에 액세스할 수 있는 중간 머신에서 이 명령을 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ /usr/bin/mirror -registry <disconnected_registry> | oc image mirror -f -
다음과 같습니다.
- <disconnected_registry>
-
구성한 연결이 끊긴 미러 레지스트리입니다(예:
my.local.registry:5000/).
cnf-tests이미지를 연결이 끊긴 레지스트리에 미러링한 경우 테스트를 실행할 때 이미지를 가져오는 데 사용되는 원래 레지스트리를 재정의해야 합니다. 예를 들면 다음과 같습니다.podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<disconnected_registry>" \ -e CNF_TESTS_IMAGE="cnf-tests-rhel8:v4.15" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ <disconnected_registry>/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
사용자 정의 레지스트리의 이미지를 사용하도록 테스트 구성
CNF_TESTS_IMAGE 및 IMAGE_REGISTRY 변수를 사용하여 사용자 정의 테스트 이미지 및 이미지 레지스트리를 사용하여 대기 시간 테스트를 실행할 수 있습니다.
사용자 정의 테스트 이미지 및 이미지 레지스트리를 사용하도록 대기 시간 테스트를 구성하려면 다음 명령을 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<custom_image_registry>" \ -e CNF_TESTS_IMAGE="<custom_cnf-tests_image>" \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
다음과 같습니다.
- <custom_image_registry>
-
사용자 지정 이미지 레지스트리입니다(예:
custom.registry:5000/). - <custom_cnf-tests_image>
-
사용자 지정 cnf-tests 이미지입니다(예:
custom-cnf-tests-image:latest).
클러스터 OpenShift 이미지 레지스트리에 이미지 미러링
OpenShift Container Platform은 클러스터에서 표준 워크로드로 실행되는 내장 컨테이너 이미지 레지스트리를 제공합니다.
프로세스
경로를 통해 레지스트리를 공개하여 레지스트리에 대한 외부 액세스 권한을 얻습니다.
$ oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=merge다음 명령을 실행하여 레지스트리 끝점을 가져옵니다.
$ REGISTRY=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')이미지를 공개하는 데 사용할 네임스페이스를 생성합니다.
$ oc create ns cnftests
테스트에 사용되는 모든 네임스페이스에서 이미지 스트림을 사용할 수 있도록 합니다. 테스트 네임스페이스가
cnf-tests이미지 스트림에서 이미지를 가져올 수 있도록 하려면 이 작업이 필요합니다. 다음 명령을 실행합니다.$ oc policy add-role-to-user system:image-puller system:serviceaccount:cnf-features-testing:default --namespace=cnftests
$ oc policy add-role-to-user system:image-puller system:serviceaccount:performance-addon-operators-testing:default --namespace=cnftests
다음 명령을 실행하여 Docker 보안 이름 및 인증 토큰을 검색합니다.
$ SECRET=$(oc -n cnftests get secret | grep builder-docker | awk {'print $1'}$ TOKEN=$(oc -n cnftests get secret $SECRET -o jsonpath="{.data['\.dockercfg']}" | base64 --decode | jq '.["image-registry.openshift-image-registry.svc:5000"].auth')dockerauth.json파일을 생성합니다. 예를 들면 다음과 같습니다.$ echo "{\"auths\": { \"$REGISTRY\": { \"auth\": $TOKEN } }}" > dockerauth.json이미지 미러링을 수행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:4.15 \ /usr/bin/mirror -registry $REGISTRY/cnftests | oc image mirror --insecure=true \ -a=$(pwd)/dockerauth.json -f -
테스트를 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUNTIME=<time_in_seconds> \ -e IMAGE_REGISTRY=image-registry.openshift-image-registry.svc:5000/cnftests cnf-tests-local:latest /usr/bin/test-run.sh --ginkgo.v --ginkgo.timeout="24h"
다른 테스트 이미지 세트 미러링
필요한 경우 대기 시간 테스트에 미러링된 기본 업스트림 이미지를 변경할 수 있습니다.
프로세스
mirror명령은 기본적으로 업스트림 이미지를 미러링하려고 합니다. 다음 형식의 파일을 이미지에 전달하여 재정의할 수 있습니다.[ { "registry": "public.registry.io:5000", "image": "imageforcnftests:4.15" } ]파일을
mirror명령에 전달합니다. 예를 들어images.json으로 로컬로 저장하십시오. 다음 명령을 사용하면 로컬 경로가 컨테이너 내/kubeconfig에 마운트되어 mirror 명령에 전달될 수 있습니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 /usr/bin/mirror \ --registry "my.local.registry:5000/" --images "/kubeconfig/images.json" \ | oc image mirror -f -
11.5.8. cnf-tests 컨테이너를 사용한 오류 문제 해결
대기 시간 테스트를 실행하려면 cnf-tests 컨테이너 내에서 클러스터에 액세스할 수 있어야 합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다.
프로세스
다음 명령을 실행하여
cnf-tests컨테이너 내부에서 클러스터에 액세스할 수 있는지 확인합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.15 \ oc get nodes
이 명령이 작동하지 않으면 DNS, MTU 크기 또는 방화벽 액세스 전반에 걸쳐 발생하는 오류가 발생할 수 있습니다.
12장. 작업자 대기 시간 프로필을 사용하여 대기 시간이 많은 환경에서 클러스터 안정성 개선
클러스터 관리자가 플랫폼 확인을 위해 대기 시간 테스트를 수행한 경우 대기 시간이 긴 경우 안정성을 보장하기 위해 클러스터의 작동을 조정해야 할 수 있습니다. 클러스터 관리자는 파일에 기록된 하나의 매개 변수만 변경해야 합니다. 이 매개변수는 감독자 프로세스가 상태를 읽고 클러스터의 상태를 해석하는 방법에 영향을 미치는 매개변수 4개를 제어합니다. 하나의 매개변수만 변경하면 지원 가능한 방식으로 클러스터 튜닝이 제공됩니다.
Kubelet 프로세스는 클러스터 상태를 모니터링하기 위한 시작점을 제공합니다. Kubelet 은 OpenShift Container Platform 클러스터의 모든 노드에 대한 상태 값을 설정합니다. Kubernetes Controller Manager(kube 컨트롤러)는 기본적으로 10초마다 상태 값을 읽습니다. kube 컨트롤러에서 노드 상태 값을 읽을 수 없는 경우 구성된 기간이 지난 후 해당 노드와의 연결이 끊어집니다. 기본 동작은 다음과 같습니다.
-
컨트롤 플레인의 노드 컨트롤러는 노드 상태를
Unhealthy로 업데이트하고 노드Ready조건 'Unknown'을 표시합니다. - 스케줄러는 이에 대한 응답으로 해당 노드에 대한 Pod 예약을 중지합니다.
-
Node Lifecycle Controller는
NoExecute효과가 있는node.kubernetes.io/unreachable테인트를 노드에 추가하고 기본적으로 5분 후에 제거하도록 노드에 Pod를 예약합니다.
이 동작은 특히 네트워크 엣지에 노드가 있는 경우 네트워크에서 대기 시간이 쉬운 경우 문제가 발생할 수 있습니다. 경우에 따라 네트워크 대기 시간으로 인해 Kubernetes 컨트롤러 관리자에서 정상적인 노드에서 업데이트를 수신하지 못할 수 있습니다. Kubelet 은 노드가 정상이지만 노드에서 Pod를 제거합니다.
이 문제를 방지하려면 작업자 대기 시간 프로필을 사용하여 Kubelet 및 Kubernetes 컨트롤러 관리자가 작업을 수행하기 전에 상태 업데이트를 기다리는 빈도를 조정할 수 있습니다. 이러한 조정은 컨트롤 플레인과 작업자 노드 간의 네트워크 대기 시간이 최적이 아닌 경우 클러스터가 올바르게 실행되도록 하는 데 도움이 됩니다.
이러한 작업자 대기 시간 프로필에는 대기 시간을 높이기 위해 클러스터의 응답을 제어하기 위해 신중하게 조정된 값으로 미리 정의된 세 가지 매개변수 세트가 포함되어 있습니다. 실험적으로 최상의 값을 수동으로 찾을 필요가 없습니다.
클러스터를 설치하거나 클러스터 네트워크에서 대기 시간을 늘리면 언제든지 작업자 대기 시간 프로필을 구성할 수 있습니다.
12.1. 작업자 대기 시간 프로필 이해
작업자 대기 시간 프로필은 신중하게 조정된 매개변수의 네 가지 범주입니다. 이러한 값을 구현하는 4개의 매개변수는 node-status-update-frequency,node-monitor-grace-period,default-not-ready-toleration-seconds 및 default-unreachable-toleration-seconds 입니다. 이러한 매개변수는 수동 방법을 사용하여 최상의 값을 결정할 필요 없이 대기 시간 문제에 대한 클러스터의 대응을 제어할 수 있는 값을 사용할 수 있습니다.
이러한 매개변수를 수동으로 설정하는 것은 지원되지 않습니다. 잘못된 매개변수 설정은 클러스터 안정성에 부정적인 영향을 미칩니다.
모든 작업자 대기 시간 프로필은 다음 매개변수를 구성합니다.
- node-status-update-frequency
- kubelet이 API 서버에 노드 상태를 게시하는 빈도를 지정합니다.
- node-monitor-grace-period
-
노드를 비정상적으로 표시하고
node.kubernetes.io/not-ready또는node.kubernetes.io/unreachable테인트를 노드에 추가하기 전에 Kubernetes 컨트롤러 관리자가 kubelet에서 업데이트를 기다리는 시간(초)을 지정합니다. - default-not-ready-toleration-seconds
- 해당 노드에서 Pod를 제거하기 전에 Kube API Server Operator가 기다리는 비정상적인 노드를 표시한 후 시간(초)을 지정합니다.
- default-unreachable-toleration-seconds
- 해당 노드에서 Pod를 제거하기 전에 Kube API Server Operator가 대기할 수 없는 노드를 표시한 후 시간(초)을 지정합니다.
다음 Operator는 작업자 대기 시간 프로필에 대한 변경 사항을 모니터링하고 적절하게 응답합니다.
-
MCO(Machine Config Operator)는 작업자 노드에서
node-status-update-frequency매개변수를 업데이트합니다. -
Kubernetes 컨트롤러 관리자는 컨트롤 플레인 노드에서
node-monitor-grace-period매개변수를 업데이트합니다. -
Kubernetes API Server Operator는 컨트롤 플레인 노드에서
default-not-ready-toleration-seconds및default-unreachable-toleration-seconds매개변수를 업데이트합니다.
기본 구성이 대부분의 경우 작동하지만 OpenShift Container Platform은 네트워크가 일반적인 것보다 대기 시간이 길어지는 상황에 대해 두 가지 다른 작업자 대기 시간 프로필을 제공합니다. 세 가지 작업자 대기 시간 프로필은 다음 섹션에 설명되어 있습니다.
- 기본 작업자 대기 시간 프로필
Default프로필을 사용하면 각Kubelet이 10초마다 상태를 업데이트합니다(node-status-update-frequency).Kube Controller Manager는 5초마다Kubelet의 상태를 확인합니다(node-monitor-grace-period).Kubernetes 컨트롤러 관리자는
Kubelet비정상을 고려하기 전에Kubelet에서 상태 업데이트를 40초 동안 기다립니다. Kubernetes 컨트롤러 관리자에서 사용할 수 없는 상태가 없는 경우 노드를node.kubernetes.io/not-ready또는node.kubernetes.io/unreachable테인트로 표시하고 해당 노드에서 Pod를 제거합니다.해당 노드의 Pod에
NoExecute테인트가 있는 경우tolerationSeconds에 따라 Pod가 실행됩니다. Pod에 테인트가 없는 경우 300초(Kube API서버의default-not-ready-toleration-seconds및default-unreachable-toleration-seconds설정)가 제거됩니다.프로필 Component 매개변수 현재의 Default
kubelet
node-status-update-frequency10s
kubelet Controller Manager
node-monitor-grace-period40s
Kubernetes API Server Operator
default-not-ready-toleration-seconds300s
Kubernetes API Server Operator
default-unreachable-toleration-seconds300s
- 중간 규모의 작업자 대기 시간 프로파일
네트워크 대기 시간이 평상시보다 약간 높은 경우
MediumUpdateAverageReaction프로필을 사용합니다.MediumUpdateAverageReaction프로필은 kubelet 업데이트 빈도를 20초로 줄이고 Kubernetes 컨트롤러 관리자가 해당 업데이트를 2분으로 기다리는 기간을 변경합니다. 해당 노드의 Pod 제거 기간은 60초로 단축됩니다. Pod에tolerationSeconds매개변수가 있는 경우 제거는 해당 매개변수에서 지정한 기간 동안 대기합니다.Kubernetes 컨트롤러 관리자는 노드의 비정상적인 것으로 간주하기 위해 2분 정도 기다립니다. 다른 분 후에 제거 프로세스가 시작됩니다.
프로필 Component 매개변수 현재의 MediumUpdateAverageReaction
kubelet
node-status-update-frequency20s
kubelet Controller Manager
node-monitor-grace-period2m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
- 작업자 대기 시간이 짧은 프로필
네트워크 대기 시간이 매우 높은 경우
LowUpdateSlowReaction프로필을 사용합니다.LowUpdateSlowReaction프로필은 kubelet 업데이트 빈도를 1분으로 줄이고 Kubernetes 컨트롤러 관리자가 해당 업데이트를 5분으로 기다리는 기간을 변경합니다. 해당 노드의 Pod 제거 기간은 60초로 단축됩니다. Pod에tolerationSeconds매개변수가 있는 경우 제거는 해당 매개변수에서 지정한 기간 동안 대기합니다.Kubernetes 컨트롤러 관리자는 노드의 비정상적인 것으로 간주하기 위해 5분 정도 기다립니다. 다른 분 후에 제거 프로세스가 시작됩니다.
프로필 Component 매개변수 현재의 LowUpdateSlowReaction
kubelet
node-status-update-frequency1m
kubelet Controller Manager
node-monitor-grace-period5m
Kubernetes API Server Operator
default-not-ready-toleration-seconds60s
Kubernetes API Server Operator
default-unreachable-toleration-seconds60s
12.2. 클러스터 생성 시 작업자 대기 시간 프로필 구현
설치 프로그램의 구성을 편집하려면 먼저 openshift-install create manifests 명령을 사용하여 기본 노드 매니페스트 및 기타 매니페스트 YAML 파일을 생성해야 합니다. 이 파일 구조는 workerLatencyProfile을 추가하기 전에 존재해야 합니다. 설치 중인 플랫폼에는 다양한 요구 사항이 있을 수 있습니다. 특정 플랫폼에 대한 설명서의 설치 섹션을 참조하십시오.
workerLatencyProfile 은 다음 순서로 매니페스트에 추가해야 합니다.
- 설치에 적합한 폴더 이름을 사용하여 클러스터를 빌드하는 데 필요한 매니페스트를 생성합니다.
-
YAML 파일을 생성하여
config.node를 정의합니다. 파일은manifests디렉터리에 있어야 합니다. -
매니페스트에
workerLatencyProfile을 처음 정의할 때 클러스터 생성 시기본,mediumUpdateAverageReaction또는LowUpdateSlowReaction.
검증
다음은 매니페스트 파일의
spec.workerLatencyProfileDefault값을 보여주는 매니페스트 생성 예제입니다.$ openshift-install create manifests --dir=<cluster-install-dir>
매니페스트를 편집하고 값을 추가합니다. 이 예제에서는
vi를 사용하여 "Default"workerLatencyProfile값이 추가된 매니페스트 파일 예제를 표시합니다.$ vi <cluster-install-dir>/manifests/config-node-default-profile.yaml
출력 예
apiVersion: config.openshift.io/v1 kind: Node metadata: name: cluster spec: workerLatencyProfile: "Default"
12.3. 작업자 대기 시간 프로필 사용 및 변경
네트워크 대기 시간을 처리하기 위해 작업자 대기 시간 프로필을 변경하려면 node.config 오브젝트를 편집하여 프로필 이름을 추가합니다. 대기 시간이 증가하거나 감소하면 언제든지 프로필을 변경할 수 있습니다.
한 번에 하나의 작업자 대기 시간 프로필을 이동해야 합니다. 예를 들어 Default 프로필에서 LowUpdateSlowReaction 작업자 대기 시간 프로파일로 직접 이동할 수 없습니다. 기본 작업자 대기 시간 프로필에서 먼저 MediumUpdateAverageReaction 프로필로 이동한 다음 LowUpdateSlowReaction 으로 이동해야 합니다. 마찬가지로 Default 프로필로 돌아갈 때 먼저 low 프로필에서 medium 프로필로 이동한 다음 Default 로 이동해야 합니다.
OpenShift Container Platform 클러스터를 설치할 때 작업자 대기 시간 프로필을 구성할 수도 있습니다.
프로세스
기본 작업자 대기 시간 프로필에서 이동하려면 다음을 수행합니다.
중간 작업자 대기 시간 프로필로 이동합니다.
node.config오브젝트를 편집합니다.$ oc edit nodes.config/cluster
spec.workerLatencyProfile: MediumUpdateAverageReaction:node.config오브젝트의 예apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: MediumUpdateAverageReaction 1 # ...- 1
- 중간 작업자 대기 시간을 지정합니다.
변경 사항이 적용되므로 각 작업자 노드의 예약이 비활성화됩니다.
선택 사항: 낮은 작업자 대기 시간 프로필로 이동합니다.
node.config오브젝트를 편집합니다.$ oc edit nodes.config/cluster
spec.workerLatencyProfile값을LowUpdateSlowReaction:으로 변경합니다.node.config오브젝트의 예apiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: LowUpdateSlowReaction 1 # ...- 1
- 낮은 작업자 대기 시간 정책 사용을 지정합니다.
변경 사항이 적용되므로 각 작업자 노드의 예약이 비활성화됩니다.
검증
모든 노드가
Ready조건으로 돌아가면 다음 명령을 사용하여 Kubernetes 컨트롤러 관리자를 확인하여 적용되었는지 확인할 수 있습니다.$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5
출력 예
# ... - lastTransitionTime: "2022-07-11T19:47:10Z" reason: ProfileUpdated status: "False" type: WorkerLatencyProfileProgressing - lastTransitionTime: "2022-07-11T19:47:10Z" 1 message: all static pod revision(s) have updated latency profile reason: ProfileUpdated status: "True" type: WorkerLatencyProfileComplete - lastTransitionTime: "2022-07-11T19:20:11Z" reason: AsExpected status: "False" type: WorkerLatencyProfileDegraded - lastTransitionTime: "2022-07-11T19:20:36Z" status: "False" # ...- 1
- 프로필이 적용되고 활성화되도록 지정합니다.
미디어 프로필을 기본값으로 변경하거나 기본값을 medium로 변경하려면 node.config 오브젝트를 편집하고 spec.workerLatencyProfile 매개변수를 적절한 값으로 설정합니다.
12.4. workerLatencyProfile의 결과 값을 표시하는 단계의 예
다음 명령을 사용하여 workerLatencyProfile 의 값을 표시할 수 있습니다.
검증
Kube API Server에서
default-not-ready-toleration-seconds및default-unreachable-toleration-seconds필드 출력을 확인합니다.$ oc get KubeAPIServer -o yaml | grep -A 1 default-
출력 예
default-not-ready-toleration-seconds: - "300" default-unreachable-toleration-seconds: - "300"
Kube Controller Manager에서
node-monitor-grace-period필드의 값을 확인합니다.$ oc get KubeControllerManager -o yaml | grep -A 1 node-monitor
출력 예
node-monitor-grace-period: - 40s
Kubelet에서
nodeStatusUpdateFrequency값을 확인합니다. 디버그 쉘 내에서/host디렉터리를 root 디렉터리로 설정합니다. root 디렉토리를/host로 변경하면 호스트의 실행 경로에 포함된 바이너리를 실행할 수 있습니다.$ oc debug node/<worker-node-name> $ chroot /host # cat /etc/kubernetes/kubelet.conf|grep nodeStatusUpdateFrequency
출력 예
“nodeStatusUpdateFrequency”: “10s”
이러한 출력은 Worker Latency Profile의 타이밍 변수 집합의 유효성을 검사합니다.
13장. 워크로드 파티셔닝
리소스가 제한적인 환경에서는 워크로드 파티셔닝을 사용하여 OpenShift Container Platform 서비스, 클러스터 관리 워크로드 및 인프라 Pod를 분리하여 예약된 CPU 세트에서 실행할 수 있습니다.
클러스터 관리에 필요한 최소 예약된 CPU 수는 4개의 CPU Hyper-Threads(HT)입니다. 워크로드 파티셔닝을 사용하면 클러스터 관리 워크로드 파티션에 포함할 수 있도록 클러스터 관리 Pod 세트와 일반적인 추가 기능 Operator 세트에 주석을 답니다. 이러한 Pod는 최소 크기 CPU 구성 내에서 정상적으로 작동합니다. 최소 클러스터 관리 Pod 세트 이외의 추가 Operator 또는 워크로드에는 워크로드 파티션에 추가 CPU를 추가해야 합니다.
워크로드 파티셔닝은 표준 Kubernetes 스케줄링 기능을 사용하여 플랫폼 워크로드에서 사용자 워크로드를 분리합니다.
워크로드 파티셔닝에는 다음과 같은 변경이 필요합니다.
install-config.yaml파일에서 추가 필드:cpu CryostatingMode 를추가합니다.apiVersion: v1 baseDomain: devcluster.openshift.com cpuPartitioningMode: AllNodes 1 compute: - architecture: amd64 hyperthreading: Enabled name: worker platform: {} replicas: 3 controlPlane: architecture: amd64 hyperthreading: Enabled name: master platform: {} replicas: 3- 1
- 설치 시 CPU 파티셔닝을 위한 클러스터를 설정합니다. 기본값은
None입니다.
참고워크로드 파티셔닝은 클러스터 설치 중에만 활성화할 수 있습니다. 워크로드 파티션 설치 후 비활성화할 수 없습니다.
성능 프로필에서
분리된CPU와예약된CPU를 지정합니다.권장되는 성능 프로파일 구성
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: # if you change this name make sure the 'include' line in TunedPerformancePatch.yaml # matches this name: include=openshift-node-performance-${PerformanceProfile.metadata.name} # Also in file 'validatorCRs/informDuValidator.yaml': # name: 50-performance-${PerformanceProfile.metadata.name} name: openshift-node-performance-profile annotations: ran.openshift.io/reference-configuration: "ran-du.redhat.com" spec: additionalKernelArgs: - "rcupdate.rcu_normal_after_boot=0" - "efi=runtime" - "vfio_pci.enable_sriov=1" - "vfio_pci.disable_idle_d3=1" - "module_blacklist=irdma" cpu: isolated: $isolated reserved: $reserved hugepages: defaultHugepagesSize: $defaultHugepagesSize pages: - size: $size count: $count node: $node machineConfigPoolSelector: pools.operator.machineconfiguration.openshift.io/$mcp: "" nodeSelector: node-role.kubernetes.io/$mcp: '' numa: topologyPolicy: "restricted" # To use the standard (non-realtime) kernel, set enabled to false realTimeKernel: enabled: true workloadHints: # WorkloadHints defines the set of upper level flags for different type of workloads. # See https://github.com/openshift/cluster-node-tuning-operator/blob/master/docs/performanceprofile/performance_profile.md#workloadhints # for detailed descriptions of each item. # The configuration below is set for a low latency, performance mode. realTime: true highPowerConsumption: false perPodPowerManagement: false표 13.1. 단일 노드 OpenShift 클러스터에 대한 PerformanceProfile CR 옵션
PerformanceProfile CR 필드 설명 metadata.namename이 관련 GitOps ZTP CR(사용자 정의 리소스)에 설정된 다음 필드와 일치하는지 확인합니다.-
TunedPerformancePatch.yaml에서include=openshift-node-performance-${PerformanceProfile.metadata.name} -
이름:validatorCRs/informDuValidator.yaml의 50-performance-${PerformanceProfile.metadata.name}
spec.additionalKernelArgs"EFI=runtime"은 클러스터 호스트에 대해 UEFI 보안 부팅을 구성합니다.spec.cpu.isolated분리된 CPU를 설정합니다. 모든 Hyper-Threading 쌍이 일치하는지 확인합니다.
중요예약 및 격리된 CPU 풀은 겹치지 않아야 하며 함께 사용 가능한 모든 코어에 걸쳐 있어야 합니다. 에 대해 고려하지 않은 CPU 코어로 인해 시스템에서 정의되지 않은 동작이 발생합니다.
spec.cpu.reserved예약된 CPU를 설정합니다. 워크로드 파티셔닝이 활성화되면 시스템 프로세스, 커널 스레드 및 시스템 컨테이너 스레드가 이러한 CPU로 제한됩니다. 분리되지 않은 모든 CPU를 예약해야 합니다.
spec.hugepages.pages-
대규모 페이지 수 설정 (
count) -
대규모 페이지 크기(
크기)를 설정합니다. -
node를hugepages가 할당된 NUMA 노드로 설정합니다(노드)
spec.realTimeKernel실시간 커널을 사용하려면
enabled를true로 설정합니다.spec.workloadHintsworkloadHints를 사용하여 다른 워크로드 유형에 대한 최상위 플래그 세트를 정의합니다. 예제 구성은 짧은 대기 시간과 높은 성능을 위해 클러스터를 구성합니다.-
워크로드 파티셔닝으로 플랫폼 pod의 확장된 management.workload.openshift.io/cores 리소스 유형을 도입합니다. kubelet은 해당 리소스 내에서 풀에 할당된 Pod의 리소스 및 CPU 요청을 알립니다. 워크로드 파티셔닝이 활성화되면 management.workload.openshift.io/cores 리소스를 사용하면 스케줄러에서 기본 cpuset 뿐만 아니라 호스트의 cpushares 용량에 따라 Pod를 올바르게 할당할 수 있습니다.
추가 리소스
- 단일 노드 OpenShift 클러스터에 권장되는 워크로드 파티셔닝 구성은 워크로드 분할 작업을 참조하십시오.
14장. Node Observability Operator 사용
Node Observability Operator는 컴퓨팅 노드의 스크립트에서 CRI-O 및 Kubelet 프로파일링 또는 메트릭을 수집하고 저장합니다.
Node Observability Operator를 사용하면 프로파일링 데이터를 쿼리하여 CRI-O 및 Kubelet의 성능 추세를 분석할 수 있습니다. 사용자 정의 리소스 정의에서 run 필드를 사용하여 성능 관련 문제를 디버깅하고 네트워크 지표에 포함된 스크립트를 실행할 수 있습니다. CRI-O 및 Kubelet 프로파일링 또는 스크립팅을 활성화하려면 사용자 정의 리소스 정의에서 type 필드를 구성할 수 있습니다.
Node Observability Operator는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
14.1. Node Observability Operator의 워크플로우
다음 워크플로는 Node Observability Operator를 사용하여 프로파일링 데이터를 쿼리하는 방법을 간략하게 설명합니다.
- OpenShift Container Platform 클러스터에 Node Observability Operator를 설치합니다.
- NodeObservability 사용자 정의 리소스를 생성하여 선택한 작업자 노드에서 CRI-O 프로파일링을 활성화합니다.
- 프로파일링 쿼리를 실행하여 프로파일링 데이터를 생성합니다.
14.2. Node Observability Operator 설치
Node Observability Operator는 기본적으로 OpenShift Container Platform에 설치되지 않습니다. OpenShift Container Platform CLI 또는 웹 콘솔을 사용하여 Node Observability Operator를 설치할 수 있습니다.
14.2.1. CLI를 사용하여 Node Observability Operator 설치
OpenShift CLI(oc)를 사용하여 Node Observability Operator를 설치할 수 있습니다.
사전 요구 사항
- OpenShift CLI(oc)가 설치되어 있습니다.
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다.
프로세스
다음 명령을 실행하여 Node Observability Operator를 사용할 수 있는지 확인합니다.
$ oc get packagemanifests -n openshift-marketplace node-observability-operator
출력 예
NAME CATALOG AGE node-observability-operator Red Hat Operators 9h
다음 명령을 실행하여
node-observability-operator네임스페이스를 생성합니다.$ oc new-project node-observability-operator
OperatorGroup오브젝트 YAML 파일을 생성합니다.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: node-observability-operator namespace: node-observability-operator spec: targetNamespaces: [] EOF
서브스크립션오브젝트 YAML 파일을 생성하여 Operator에 네임스페이스를 등록합니다.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: node-observability-operator namespace: node-observability-operator spec: channel: alpha name: node-observability-operator source: redhat-operators sourceNamespace: openshift-marketplace EOF
검증
다음 명령을 실행하여 설치 계획 이름을 확인합니다.
$ oc -n node-observability-operator get sub node-observability-operator -o yaml | yq '.status.installplan.name'
출력 예
install-dt54w
다음 명령을 실행하여 설치 계획 상태를 확인합니다.
$ oc -n node-observability-operator get ip <install_plan_name> -o yaml | yq '.status.phase'
<install_plan_name>은 이전 명령의 출력에서 얻은 설치 계획 이름입니다.출력 예
COMPLETE
Node Observability Operator가 실행 중인지 확인합니다.
$ oc get deploy -n node-observability-operator
출력 예
NAME READY UP-TO-DATE AVAILABLE AGE node-observability-operator-controller-manager 1/1 1 1 40h
14.2.2. 웹 콘솔을 사용하여 Node Observability Operator 설치
OpenShift Container Platform 웹 콘솔에서 Node Observability Operator를 설치할 수 있습니다.
사전 요구 사항
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다. - OpenShift Container Platform 웹 콘솔에 액세스할 수 있습니다.
프로세스
- OpenShift Container Platform 웹 콘솔에 로그인합니다.
- 관리자 탐색 패널에서 Operator → OperatorHub 를 확장합니다.
- All items 필드에 Node Observability Operator 를 입력하고 Node Observability Operator 타일을 선택합니다.
- 설치를 클릭합니다.
Operator 설치 페이지에서 다음 설정을 구성합니다.
- 채널 업데이트 영역에서 알파 를 클릭합니다.
- 설치 모드 영역에서 클러스터에서 특정 네임스페이스를 클릭합니다.
- 설치된 네임스페이스 목록에서 목록에서 node-observability-operator 를 선택합니다.
- 업데이트 승인 영역에서 Automatic 을 선택합니다.
- 설치를 클릭합니다.
검증
- 관리자 탐색 패널에서 Operator → 설치된 Operator 를 확장합니다.
- Node Observability Operator가 Operator 목록에 나열되어 있는지 확인합니다.
14.3. Node Observability Operator를 사용하여 CRI-O 및 Kubelet 프로파일링 데이터 요청
CRI-O 및 Kubelet 프로파일링 데이터를 수집하기 위해 노드 Observability 사용자 정의 리소스를 생성합니다.
14.3.1. 노드 Observability 사용자 정의 리소스 생성
프로파일링 쿼리를 실행하기 전에 NodeObservability CR(사용자 정의 리소스)을 생성하고 실행해야 합니다. NodeObservability CR을 실행하면 nodeSelector 와 일치하는 작업자 노드에서 CRI-O 프로파일링을 활성화하는 데 필요한 머신 구성 및 머신 구성 풀 CR을 생성합니다.
작업자 노드에서 CRI-O 프로파일링이 활성화되지 않으면 NodeObservabilityMachineConfig 리소스가 생성됩니다. NodeObservability CR에 지정된 nodeSelector 와 일치하는 작업자 노드가 재시작됩니다. 완료하는 데 10분 이상 걸릴 수 있습니다.
kubelet 프로파일링은 기본적으로 활성화되어 있습니다.
노드의 CRI-O unix 소켓은 에이전트 pod에 마운트되므로 에이전트가 CRI-O와 통신하여 pprof 요청을 실행할 수 있습니다. 마찬가지로 kubelet-serving-ca 인증서 체인은 에이전트 pod에 마운트되므로 에이전트와 노드의 kubelet 끝점 간의 보안 통신이 가능합니다.
사전 요구 사항
- Node Observability Operator가 설치되어 있습니다.
- OpenShift CLI(oc)가 설치되어 있습니다.
-
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다.
프로세스
다음 명령을 실행하여 OpenShift Container Platform CLI에 로그인합니다.
$ oc login -u kubeadmin https://<HOSTNAME>:6443
다음 명령을 실행하여
node-observability-operator네임스페이스로 다시 전환합니다.$ oc project node-observability-operator
다음 텍스트가 포함된
nodeobservability.yaml이라는 CR 파일을 생성합니다.apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservability metadata: name: cluster 1 spec: nodeSelector: kubernetes.io/hostname: <node_hostname> 2 type: crio-kubeletNodeObservabilityCR을 실행합니다.oc apply -f nodeobservability.yaml
출력 예
nodeobservability.olm.openshift.io/cluster created
다음 명령을 실행하여
NodeObservabilityCR의 상태를 검토합니다.$ oc get nob/cluster -o yaml | yq '.status.conditions'
출력 예
conditions: conditions: - lastTransitionTime: "2022-07-05T07:33:54Z" message: 'DaemonSet node-observability-ds ready: true NodeObservabilityMachineConfig ready: true' reason: Ready status: "True" type: Ready이유는
Ready이고 상태가True인 경우NodeObservabilityCR 실행이 완료됩니다.
14.3.2. 프로파일링 쿼리 실행
프로파일링 쿼리를 실행하려면 NodeObservabilityRun 리소스를 생성해야 합니다. 프로파일링 쿼리는 30초 동안 CRI-O 및 Kubelet 프로파일링 데이터를 가져오는 차단 작업입니다. 프로파일링 쿼리가 완료되면 컨테이너 파일 시스템 /run/node-observability 디렉터리 내에서 프로파일링 데이터를 검색해야 합니다. 데이터의 수명은 emptyDir 볼륨을 통해 에이전트 Pod에 바인딩되므로 에이전트 Pod가 실행 중인 동안 프로파일링 데이터에 액세스할 수 있습니다.
언제든지 하나의 프로파일링 쿼리만 요청할 수 있습니다.
사전 요구 사항
- Node Observability Operator가 설치되어 있습니다.
-
NodeObservabilityCR(사용자 정의 리소스)을 생성했습니다. -
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다.
프로세스
다음 텍스트가 포함된
nodeobservabilityrun.yaml이라는NodeObservabilityRun리소스 파일을 생성합니다.apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservabilityRun metadata: name: nodeobservabilityrun spec: nodeObservabilityRef: name: clusterNodeObservabilityRun리소스를 실행하여 프로파일링 쿼리를 트리거합니다.$ oc apply -f nodeobservabilityrun.yaml
다음 명령을 실행하여
NodeObservabilityRun의 상태를 검토합니다.$ oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq '.status.conditions'
출력 예
conditions: - lastTransitionTime: "2022-07-07T14:57:34Z" message: Ready to start profiling reason: Ready status: "True" type: Ready - lastTransitionTime: "2022-07-07T14:58:10Z" message: Profiling query done reason: Finished status: "True" type: Finished
상태가
True이면 프로파일링 쿼리가 완료되고 유형이 완료됨.다음 bash 스크립트를 실행하여 컨테이너의
/run/node-observability경로에서 프로파일링 데이터를 검색합니다.for a in $(oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq .status.agents[].name); do echo "agent ${a}" mkdir -p "/tmp/${a}" for p in $(oc exec "${a}" -c node-observability-agent -- bash -c "ls /run/node-observability/*.pprof"); do f="$(basename ${p})" echo "copying ${f} to /tmp/${a}/${f}" oc exec "${a}" -c node-observability-agent -- cat "${p}" > "/tmp/${a}/${f}" done done
14.4. Node Observability Operator 스크립팅
스크립팅을 사용하면 현재 Node Observability Operator 및 Node Observability Agent를 사용하여 사전 구성된 bash 스크립트를 실행할 수 있습니다.
이 스크립트는 CPU 부하, 메모리 부족, 작업자 노드 문제와 같은 주요 지표를 모니터링합니다. 또한 sar 보고서 및 사용자 지정 성능 메트릭을 수집합니다.
14.4.1. 스크립팅을 위한 노드 Observability 사용자 정의 리소스 생성
스크립팅을 실행하기 전에 NodeObservability CR(사용자 정의 리소스)을 생성하고 실행해야 합니다. NodeObservability CR을 실행하면 nodeSelector 레이블과 일치하는 컴퓨팅 노드에서 에이전트가 스크립팅 모드로 활성화됩니다.
사전 요구 사항
- Node Observability Operator가 설치되어 있습니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다.
프로세스
다음 명령을 실행하여 OpenShift Container Platform 클러스터에 로그인합니다.
$ oc login -u kubeadmin https://<host_name>:6443
다음 명령을 실행하여
node-observability-operator네임스페이스로 전환합니다.$ oc project node-observability-operator
다음 콘텐츠가 포함된
nodeobservability.yaml파일을 생성합니다.apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservability metadata: name: cluster 1 spec: nodeSelector: kubernetes.io/hostname: <node_hostname> 2 type: scripting 3다음 명령을 실행하여
NodeObservabilityCR을 생성합니다.$ oc apply -f nodeobservability.yaml
출력 예
nodeobservability.olm.openshift.io/cluster created
다음 명령을 실행하여
NodeObservabilityCR의 상태를 검토합니다.$ oc get nob/cluster -o yaml | yq '.status.conditions'
출력 예
conditions: conditions: - lastTransitionTime: "2022-07-05T07:33:54Z" message: 'DaemonSet node-observability-ds ready: true NodeObservabilityScripting ready: true' reason: Ready status: "True" type: Ready이유는Ready이고상태가"True"인 경우NodeObservabilityCR 실행이 완료됩니다.
14.4.2. 노드 Observability Operator 스크립팅 구성
사전 요구 사항
- Node Observability Operator가 설치되어 있습니다.
-
NodeObservabilityCR(사용자 정의 리소스)을 생성했습니다. -
cluster-admin권한이 있는 클러스터에 액세스할 수 있습니다.
프로세스
다음 콘텐츠가 포함된
nodeobservabilityrun-script.yaml파일을 생성합니다.apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservabilityRun metadata: name: nodeobservabilityrun-script namespace: node-observability-operator spec: nodeObservabilityRef: name: cluster type: scripting중요다음 스크립트만 요청할 수 있습니다.
-
metrics.sh -
network-metrics.sh(monitor.sh사용)
-
다음 명령으로
NodeObservabilityRun리소스를 생성하여 스크립팅을 트리거합니다.$ oc apply -f nodeobservabilityrun-script.yaml
다음 명령을 실행하여
NodeObservabilityRun스크립팅의 상태를 검토합니다.$ oc get nodeobservabilityrun nodeobservabilityrun-script -o yaml | yq '.status.conditions'
출력 예
Status: Agents: Ip: 10.128.2.252 Name: node-observability-agent-n2fpm Port: 8443 Ip: 10.131.0.186 Name: node-observability-agent-wcc8p Port: 8443 Conditions: Conditions: Last Transition Time: 2023-12-19T15:10:51Z Message: Ready to start profiling Reason: Ready Status: True Type: Ready Last Transition Time: 2023-12-19T15:11:01Z Message: Profiling query done Reason: Finished Status: True Type: Finished Finished Timestamp: 2023-12-19T15:11:01Z Start Timestamp: 2023-12-19T15:10:51ZStatus가True이고Type이 완료되면 스크립팅이완료됩니다.다음 bash 스크립트를 실행하여 컨테이너의 루트 경로에서 스크립팅 데이터를 검색합니다.
#!/bin/bash RUN=$(oc get nodeobservabilityrun --no-headers | awk '{print $1}') for a in $(oc get nodeobservabilityruns.nodeobservability.olm.openshift.io/${RUN} -o json | jq .status.agents[].name); do echo "agent ${a}" agent=$(echo ${a} | tr -d "\"\'\`") base_dir=$(oc exec "${agent}" -c node-observability-agent -- bash -c "ls -t | grep node-observability-agent" | head -1) echo "${base_dir}" mkdir -p "/tmp/${agent}" for p in $(oc exec "${agent}" -c node-observability-agent -- bash -c "ls ${base_dir}"); do f="/${base_dir}/${p}" echo "copying ${f} to /tmp/${agent}/${p}" oc exec "${agent}" -c node-observability-agent -- cat ${f} > "/tmp/${agent}/${p}" done done
14.5. 추가 리소스
작업자 메트릭을 수집하는 방법에 대한 자세한 내용은 Red Hat 지식베이스 문서를 참조하십시오.